MIT6824笔记二 Go与RPC
这节课主要介绍Go语言以及用Go实现爬虫的例子。
GO
GO的优势
- 语法层面支持线程和管道
- 垃圾回收机制,不需要手动管理内存
- 类型安全(内存安全) //关于内存安全还需要再深刻认识
线程协调方式
- channels:go 中比较推荐的方式,分阻塞和带缓冲。
- sync.Cond:信号机制。
- waitGroup:阻塞知道一组 goroutine 执行完毕,后面还会提到。
爬虫例子
从一个种子网页 URL 开始
通过 HTTP 请求,获取其内容文本
解析其内容包含的所有 URL,针对所有 URL 重复过程 2,3
为了避免重复抓取,需要记下所有抓取过的 URL。
串行爬取
(1)串行爬取的主要逻辑
1 | fmt.Printf("=== Serial===\n") |
1 | func Serial(url string, fetcher Fetcher, fetched map[string]bool) { |
深度优先遍历(DFS )全部网页构成的图结构,利用一个名为 fetched 的 set 来保存所有已经抓取过的 URL。
(2)爬取函数的主要逻辑
- Fetcher接口,里面定义了一个Fetch方法
- fakeFetcher自定义类型,是一个string到fakeResult的map
- fakeResult结构体,包括body和urls
1 | // |
并行爬取
(1)思考并行的方法
简单将抓取部分用go关键并行。
- 但如果仅这么改造,不利用某些手段(sync.WaitGroup)等待子 goroutine,而直接返回,那么可能只会抓取到种子 URL,同时造成子 goroutine 的泄露。
- 如果访问已经抓取的 URL 集合 fetched 不加锁,很可能造成多次拉取同一个网页(两个线程都访问fetched,这个url访问过了吗,结果都是未访问)
(2)并行实现——利用锁和共享变量
1 | fmt.Printf("=== ConcurrentMutex ===\n") |
1 | // |
其中,关键部分为:sync.WaitGroup
1 | var done sync.WaitGroup |
WaitGroup 内部维护了一个计数器:调用 wg.Add(n) 时候会增加 n;调用 wait.Done() 时候会减少 1。调用 wg.Wait() 会一直阻塞直到当计数器变为 0
所以 WaitGroup 适合等待一组 goroutine 都结束的场景。
利用channel实现并行爬取
我们可以实现一个新的爬虫版本,不用锁 + 共享变量,而用 go 中内置的语法:channel 来通信。具体做法类似实现一个生产者消费者模型,使用 channel 做消息队列。
- 初始将种子 url 塞进 channel。
- 消费者:master 不断从 channel 中取出 urls,判断是否抓取过,然后启动新的 worker goroutine 去抓取。
- 生产者:worker goroutine 抓取到给定的任务 url,并将解析出的结果 urls 塞回 channel。
- master 使用一个变量 n 来追踪发出的任务数;往发出一份任务增加一;从 channel 中获取并处理完一份结果(即将其再安排给 worker)减掉一;当所有任务都处理完时,退出程序。
1 | fmt.Printf("=== ConcurrentChannel ===\n") |
1 | // |
Q&A:
- master 读 channel,多 worker 写 channel,不会有竞争问题吗?channel 是线程安全的。
- channel 不需要最后 close 吗?我们用 n 追踪了所有执行中的任务数,因此当 n 为 0 退出时,channel 中不存在任何任务 / 结果,因此 master/worker 都不会对 channel 存在引用,稍后 gc collector 会将其回收。
- 为什么在 ConcurrentChannel 需要用 goroutine 往 channel 中写一个 url?否则 master 在读取的时候会一直阻塞。并且 channel 是一个非缓冲 channel,如果不用 goroutine,将会永远阻塞在写的时候。第3个问题,如果不用goroutine,并且是非缓冲管道情况下,发送方会阻塞在发送代码,直到有接收放接收消息。
RPC
定义与结构
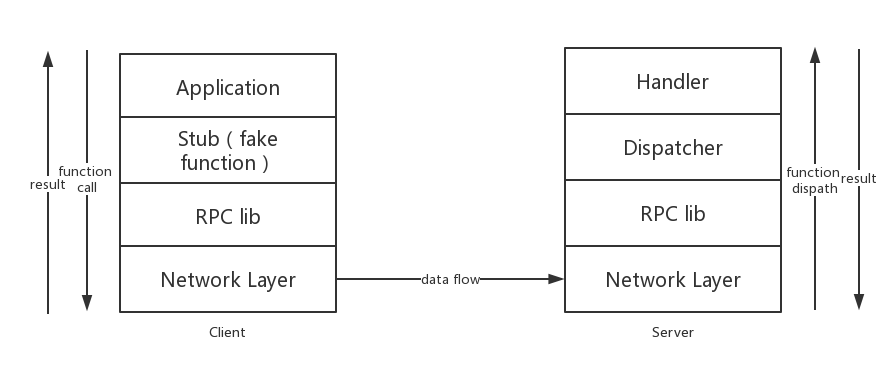
远程过程调用,用户在不知道底层网络协议的情况下,在本地的计算机就可以调用远端服务器的一些处理方法,然后服务器会把处理的结果返回到用户本地,就像这个方法写在用户本地空间中一样。
Client 端(由上到下):
- Application:应用层,表示和用户直接交互的部分,用户在该层确定自己想要调用的函数,并且输入参数
- stub:原意是烟蒂,很形象的表示这只是个函数空壳,表示用户想要调用的函数,这里可以是函数名
- RPC lib:RPC 库,包括一系列的编码解码工作,对于用户端来说,是编码用户的函数调用请求进入网络层,或者是解码服务端的结果成为上层结构可以理解的语言
- Network Layer:网络层传输协议,这里不再赘述,它可以使 TCP
Server 端(由下到上):
- Network Layer:网络层传输协议,同上
- RPC lib:RPC 库,对服务端来说,用于解码用户的调用函数请求,或者是函数结果的封装。
- Dispatcher:用户的请求到达该层后,服务端需要通过 Dispatcher,根据请求的函数,找到服务器中对应的函数,并把任务交到这个函数上
- Handler:具体的函数逻辑
RPC 的关键技术点
RPC 具体实现的关键技术点如下
- Marshall / Unmarshall:即为我们平常说的序列化/反序列化,用于将应用层的信息转化为网络层可以理解语言,抑或是将网络层的信息解码成为应用层可以理解的语言。这部分在 RPC lib 中可以完成
- Binding:在一个大的网络环境中,如何为用户分配一个符合用户所需逻辑要求的,可用的服务器也是一大难点
- Threads:handler 可能执行得很慢,而通过多线程则可以增强 Server 的吞吐量
RPC 的潜在失败情况和处理方案
RPC 的潜在失败情况有如下几种:
- Lose Packet:网络环境差造成的丢包
- Broken Net:网络直接断了
- Server Crash:服务器崩了
- Server Slow:服务器处理速度太慢
主要为Client/Server通信可能出现的问题以及主机本身的问题。
At Least Once
客户端要确保自己的消息到达服务端,那么还要设置超时过期重发机制。
缺点:网络错误,导致服务端处理重复请求。
At Most Once
服务端会收到客户端发的重复消息,重复消息的处理可能不是幂等的,那么需要一个机制能够标识重复请求。
- 客户端请求标识
- 服务端重复请求缓存
客户端需要一个标志区别重复请求或者保证时序,比如clinet IP+时间戳,可以保证旧请求在网络时延的情况下不被重复处理。
采用clinet IP+序列号的方式,可以保证相同的请求不被重复处理,而且服务端可以缓存请求结果,对于相同的重复请求,直接返回缓存。
1 | 服务端缓存什么时候删除?**客户端证明自己收到了回复的时候**。 |
MIT6824笔记二 Go与RPC