MIT6824笔记三 分布式存储系统GFS
这节课主要介绍分布式存储系统的难点以及论文GFS。
分布式系统出现的原因是人们想要利用更多的机器实现更好的性能,但更多的机器意味着故障的期望上升。解决单台机器故障最简单的办法就是多副本的容错机制,但多副本间需要时间同步。一致性难题意味着牺牲性能,这是个闭环,人们必须在性能和一致性上做取舍。
对于GFS的学习,我觉得首先要明白GFS应对的需求,整体的架构设计,然后就是读写过程,数据一致性,这是从使用层面上来说的。在高可用方面,GFS的备份管理、文件快照、崩溃恢复等细节需要再深入研究。
分布式存储系统的难点
从一种角度出发理解分布式储存的难点:
- 性能
一开始,人们想用大量机器提供更高的性能,这称之为分片(sharding)。但分片一多,故障率就上来了。
- 故障
故障:单台计算机出错概率小,多台计算机出错的期望就上来了。上千台计算机总有一台失效停机。我们需要一种容错机制(fault torlance)。
- 容错
实现容错机制最简单的办法就是提供多个副本(replication、backup),一旦一个副本失败,就马上用另一个副本顶替。
- 副本
有了复制,也还需要注意副本之间的同步,或者说一致型。
- 一致性
维护一致性通常需要精心设计的手段,比如说主从之间定期通信,传快照或者状态改变。但无论如何设计,一致性的存在或多或少会损害性能。这就是分布式存储系统/分布式系统的难点所在。
如果构建强一致系统会付出相应代价,如果不想付出很多代价,就得忍受不确定的行为。在实践中,要根据场景设计合理的系统,适当取舍。
尽管我们会通过数百台计算机构建一个系统,但是对于一个理想的强一致模型,你看到的就像是只有一台服务器,一份数据,并且系统一次只做一件事情。这是一种直观的理解强一致的方式。
Google File System
GFS 是谷歌最早开发应用的分布式存储框架。GFS的可贵之处在于它的应用性,尽管学界研究了数十年的分布式系统,但GFS是第一个应用到上千台计算机的分布式系统。论文写得很棒,推荐读英文原文。
论文中的一些思想在当时都不是特别新颖,比如分布式,分片,容错这些在当时已经知道如何实现了。这篇论文的特点是,它描述了一个真正运行在成百上千台计算机上的系统,这个规模远远超过了学术界建立的系统。并且由于GFS被用于工业界,它反映了现实世界的经验,例如对于一个系统来说,怎样才能正常工作,怎样才能节省成本,这些内容也极其有价值。
GFS 可贵之处是经过实践检验、部署过上千台机器的工业级系统,颠覆了之前学术界中很多的经典设计认知,比如:
- 为了保证数据访问不出错,需要提供强一致性保证(GFS 仅提供某种弱一致性)
- 为了系统的可靠性,用多机来保证主节点的可靠性(GFS 使用了单点 Master)
GFS的设计场景
对于任何一种分布式系统,都要明确它应用的场景需求,然后才能对此作出相应设计保障。
- 大文件存储,GB级别大小
- 大量顺序读和少量随机读
- 大量追加写和少量随机写
- 能够应对多客户端并发写入
- 部署在普通计算机上,有较高故障率,需要好的容错机制
GFS的总体设计
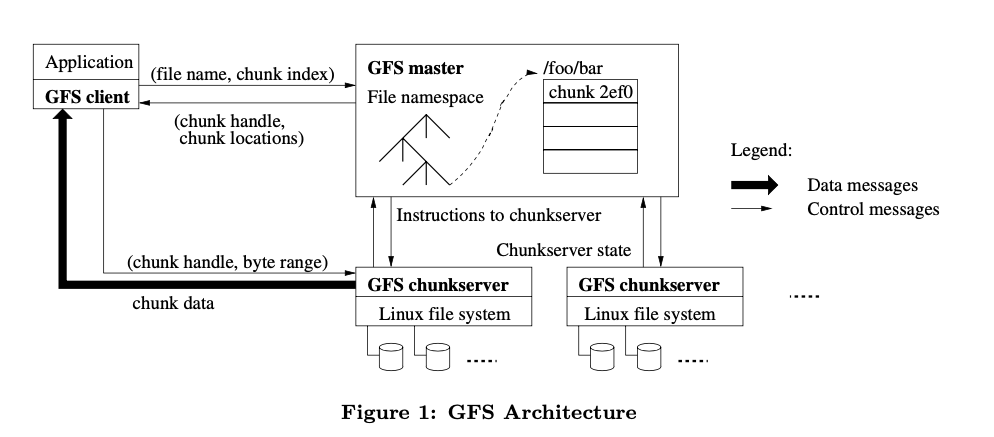
一个GFS集群包括若干个客户端、一个主节点、若干个从节点(分片服务器成,chunkserver)。
文件被分为64MB大小的块,每个块对应一个唯一64bit的块标识(chunk handle)并分散存储在从节点上。从节点就只是个运行LInux系统的普通机器。
主节点维护命名空间(文件系统的路径)、访问控制信息、文件与块的对应信息、块的存储信息(每个块存储在哪个从节点上)。
客户端与主节点的交互只有文件的元信息。客户端得到它想要的文件存储的真实信息后,就直接向从节点索要数据。
GFS读过程
// 略
GFS写过程
// 略
GFS的一致性
GFS 把自己的一致性称为松弛的一致性模型(relaxed consistency model)。
元数据(命名空间)的操作都是由单一的 master 处理的,并且操作通过锁来保护,保证了原子性,也保证了正确性。
文件的数据修改则相对复杂。在讲述接下来的内容前,首先我们先明确,在文件的某一部分被修改后,它可能进入以下三种状态的其中之一:
- 客户端读取不同的 Replica 时可能会读取到不同的内容,那这部分文件是不一致的(Inconsistent)
- 所有客户端无论读取哪个 Replica 都会读取到相同的内容,那这部分文件就是一致的(Consistent)
- 所有客户端都能看到上一次修改的所有完整内容,且这部分文件是一致的,那么我们说这部分文件是确定的(Defined)

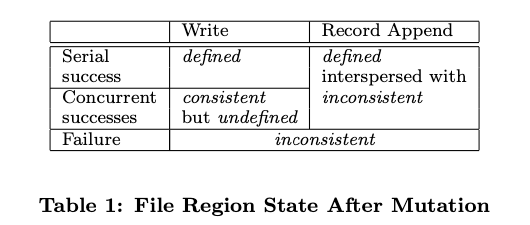
在修改后,一个文件的当前状态将取决于此次修改的类型以及修改是否成功。具体来说:
- 如果一次写入操作成功且没有与其他并发的写入操作发生重叠,那这部分的文件是确定的(同时也是一致的)
- 如果有若干个写入操作并发地执行成功,那么这部分文件会是一致的但会是不确定的:在这种情况下,客户端所能看到的数据通常不能直接体现出其中的任何一次修改
- 失败的写入操作会让文件进入不一致的状态
适应 GFS 的松弛一致性
GFS 的松弛一致性模型,实际上是一种不一致的模型,或者更准确地说,在一致的数据中间夹杂着不一致的数据。这就要求上层应用在使用 GFS 时能够适应 GFS 所提供的一致性语义。
论文中给出了几条使用 GFS 的建议:依赖追加(append)而不是依赖覆盖(overwrite)、设立检查点(checkpoint)、写入自校验(write self-validating)、自记录标识(self-identifying record)。
简单来讲,上层应用可以通过两种方式来做到这一点:更多使用追加操作而不是覆写操作;写入包含校验信息的数据。
青睐追加操作而不是覆写操作的原因是明显的:GFS 针对追加操作做出了显著的优化,这使得这种数据写入方式的性能更高,而且也能提供更强的一致性语义。
对于不一致的数据,为每条记录添加校验数,读取方通过校验数识别出不一致的数据,并且丢弃不一致的数据。
对于重复数据,可以采用数据幂等处理。具体来说,可以采用两种方式处理。第一种,对于同一份数据处理多次,这并无负面影响;第二种,如果执行多次处理带来不同的结果,那么应用就需要过滤掉不一致的数据。写入方写入记录时额外写入一个唯一的标识(identifier),读取方读取数据后,通过标识辨别之前是否已经处理过该数据。
GFS的设计哲学
前面讲解了基于GFS的应用,需要通过一些特殊手段来应对GFS的松弛一致性模型带来的各种问题。对于使用者来说,GFS的一致性保证是非常不友好的,很多人第一次看到这样的一致性保证都是比较吃惊的。
GFS在架构上选择这样的设计,有它自己的设计哲学。GFS追求的是简单、够用的原则。GFS主要解决的问题是如何使用廉价的服务器存储海量的数据,且达到非常高的吞吐量(GFS非常好地做到了这两点,但这不是本书的主题,这里就不展开介绍了),并且文件系统本身要简单,能够快速地实现出来(GFS的开发者在开发完GFS之后,很快就去开发BigTable了[2])。
GFS很好地完成了这样的目标,但是留下了一致性问题,给使用者带来了负担。这个问题在GFS推广应用的初期阶段不明显,因为GFS的主要使用者(BigTable系统是GFS系统的主要调用方)就是GFS的开发者,他们深知应该如何使用GFS。这种不一致性在BigTable中被屏蔽掉(采用上面所说的方法),BigTable提供了很好的一致性保证。
但是随着GFS推广应用的不断深入,GFS简单、够用的架构开始带来很多问题,一致性问题仅仅是其中之一。Sean Quinlan作为Leader主导GFS的研发很长时间,在一次采访中,他详细说明了在GFS渡过推广应用的初期阶段之后,这种简单的架构带来的各种问题[2]。
在清晰地看到GFS的一致性模型给使用者带来的不便后,开源的HDFS(Hadoop分布式文件系统)坚定地摒弃了GFS的一致性模型,提供了更好的一致性保证(第3章将介绍HDFS的实现方式)。
参考资料:
Google File System 论文详析 https://zhuanlan.zhihu.com/p/33944479
GFS的分布式哲学 https://mp.weixin.qq.com/s/ut8Q7vXa5Lm0auNaN2_Emg
[1] Ghemawat S, Gobioff H, Leung S T. The Google File System. ACM SIGOPS Operating Systems Review, 2003.
[2] Marshall, Kirk, McKusick, et al. GFS: Evolution on Fast-forward. Communications of the ACM, 2009.
MIT6824笔记三 分布式存储系统GFS