MIT6824笔记四 容错与FTVM
这节课主要介绍容错的主要手段——复制以及相应的论文:Fautl-Tolerant Virtual Machines。
复制与容错关系
容错本身是为了提供高可用性。例如,当你想构建一个服务时,尽管计算机硬件总是有可能故障,但是我们还是希望能稳定的提供服务。
容错的简单手段就是复制。复制能应对什么样的故障?
最简单的描述就是单台计算机的fail-stop故障。Fail-stop是一种容错领域的通用术语。它是指,如果某些东西出了故障,比如说计算机,那么它会单纯的停止运行。当任何地方出现故障时,就停止运行,而不是运算出错误结果。
但是复制不能处理软件中的bug和硬件设计中的缺陷,关联性错误(同一批次产品的生产设计缺陷)。
Fautl-Tolerant Virtual Machines
INTRODUCTION
论文的introduction写得很简练,直接放原文。
A common approach to implementing fault-tolerant servers is the primary / backup approach [1], where a backup server is always available to take over if the primary server fails.
The state of the backup server must be kept nearly identical to the primary server at all times, so that the backup server can take over immediately when the primary fails, and in such a way that the failure is hidden to external clients and no data is lost.
应对容错的主要方式就是主从复制。主节点崩溃时,从节点能够马上接管,并且从节点的状态要与主节点尽可能一致。
One way of replicating the state on the backup server is to ship changes to all state of the primary, including CPU, memory, and I/O devices, to the backup nearly continuously. However, the bandwidth needed to send this state, particular changes in memory, can be very large.
在备份服务器上复制状态的一种方法是将对主服务器的所有状态(包括 CPU、内存和 I/O 设备)的更改几乎连续地传送到备份中。但是,发送此状态所需的带宽(特别是内存中的更改)可能非常大。
A different method for replicating servers that can use much less bandwidth is sometimes referred to as the state-machine approach [13]. The idea is to model the servers as deterministic state machines that are kept in sync by starting them from the same initial state and ensuring that they receive the same input requests in the same order. Since most servers or services have some operations that are not deterministic, extra coordination must be used to ensure that a primary and backup are kept in sync. However, the amount of extra information need to keep the primary and backup in sync is far less than the amount of state (mainly memory updates) that is changing in the primary.
另一种方法基于状态机。这个想法是通过从相同的初始状态启动服务器并确保它们以相同的顺序接收相同的输入请求来将服务器建模为保持同步的确定性状态机。由于大多数服务器或服务都具有一些不确定的操作,因此必须使用额外的协调来确保主服务器和备份服务器保持同步。但是,保持主数据库和备份数据库同步所需的额外信息量远远小于主数据库中更改的状态(主要是内存更新)量。
BASIC FT DESIGN
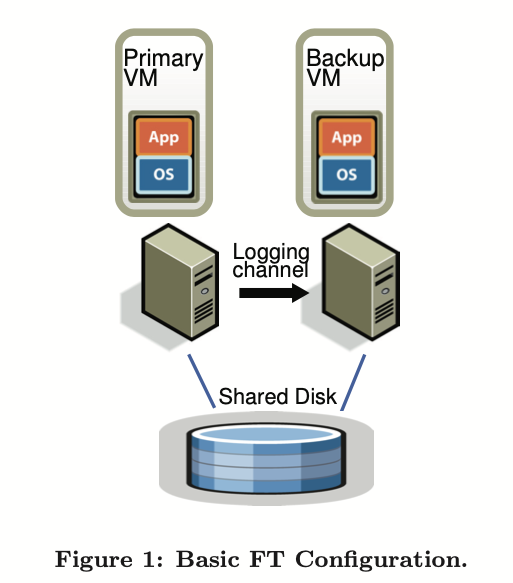
所有的输入(网络输入、鼠标键盘输入)由主节点接收。主节点和从节点间通过网络的方式通信,称之为logging channel。主节点将它看见的所有输入都通过logging channel 发给从节点。另外,logging channel还传输一些其他包括非确定性行为的信息。
这样从节点就和主节点执行一模一样的的操作,但是从节点的输出被抛弃,只有主节点才能回复客户端。
非确定性事件
非确定性事件:不由当前内存和寄存器直接决定的指令
比如随机数生成、事件日期、唯一ID,这些统称为Weird Instructions
客户端的网络输入:包中的数据和包到达的中断触发位置。
FT Protocol
output requirement
if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the primary VM has sent to the external world.
如果备份虚拟机在主虚拟机发生故障后接管,则备份虚拟机将继续以与主虚拟机发送到外部世界的所有输出完全一致的方式执行。
感觉这句话就是脱裤子放屁,多此一举。从状态机肯定要与主状态机状态一致,这样才能在故障时进行主从切换。可以通过延迟任何外部输出(通常是网络数据包)来确保输出要求,直到备份 VM 收到所有信息,使其至少可以重播到该输出操作的点。这就引出来第二个点
output rule
the primary VM may not send an out put to the external world, until the backup VM has received and acknowledged the log entry associated with the operation producing the output.
只有主节点收到日志复制完成的回复,它才向外部输出。这意味着从节点收到了日志(此时日志可能堆在缓冲区,尚未执行)
Test-and-Set服务
一种常见的场景就是主从间网络不可用,此时它们都以为对方挂了,从而各自掌权回复客户端,也就是脑裂问题。
这篇论文解决这个问题的方法是,向一个外部的第三方权威机构求证,来决定Primary还是Backup允许上线。这里的第三方就是Test-and-Set服务。
VM通过网络请求Test-and-Set服务,这个服务会在内存中保留一些标志位,当你向它发送一个Test-and-Set请求,它会设置标志位,并且返回旧的值。这有点像锁,保证了原子操作。任何情况下,想要上线掌权的副本都需要获取Test-and-Set服务。
持有锁的服务挂了怎么办?一般锁都是设置一个租约,有一些心跳机制来续约。
MIT6824笔记四 容错与FTVM