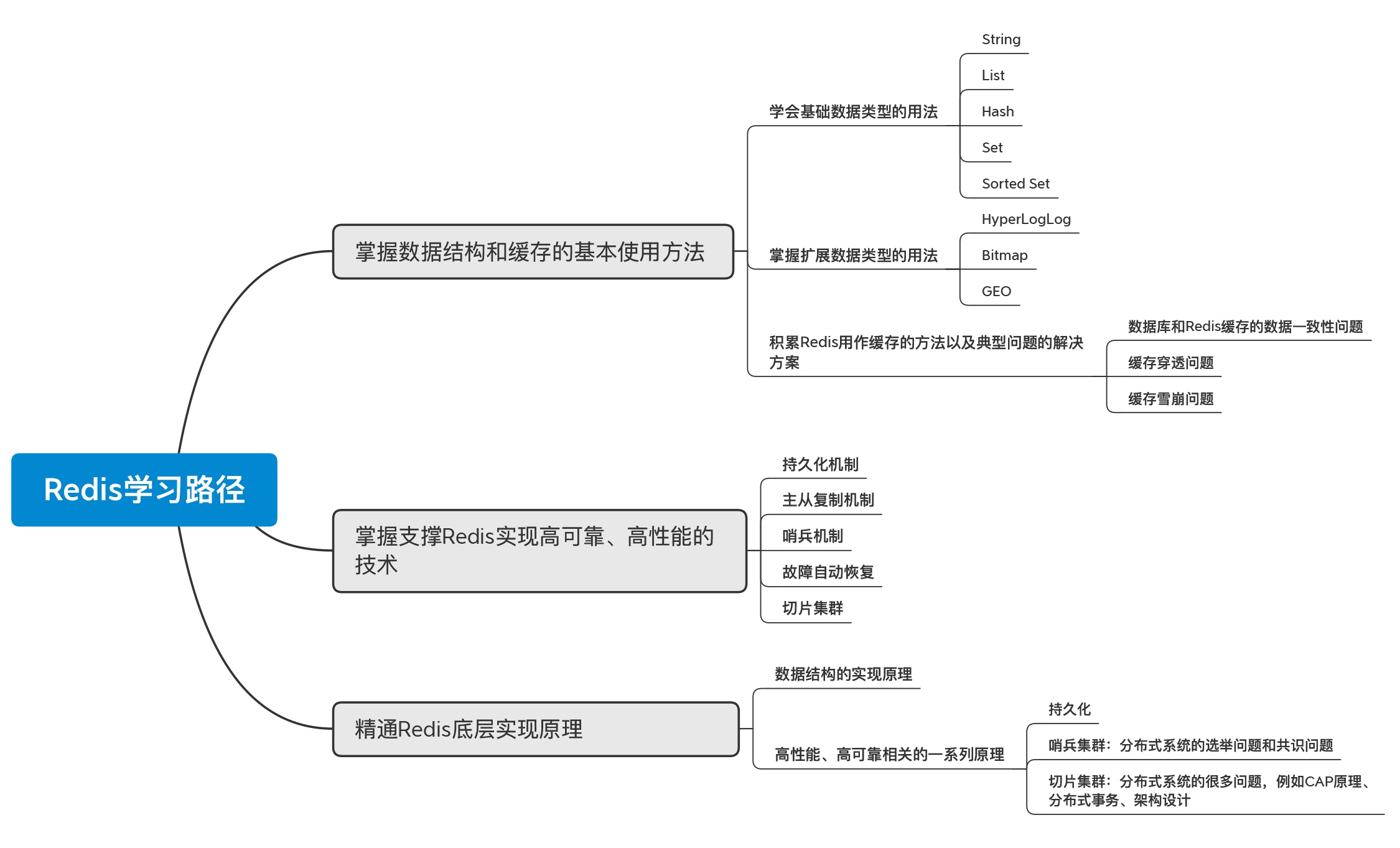
Redis学习篇
Redis是一款用C编写的基于内存的非关系数据库,实际开发中,Redis用作缓存数据库,用来减轻后端数据库的压力。Redis全称为:Remote Dictionary Server(远程数据服务)。
Redis官网::http://redis.io/
咱认为,学习Redis的最佳方式是从项目开始。先学一点数据结构Redis的终端命令,然后再接入SpringBoot快速上手项目使用。学完基本数据使用后,再探究其原理。
基本数据类型
Reids的基本数据类型是value的类型,而不是键的类型。
string类型
基本读写
1 | set key value [EX seconds|PX milliseconds] [NX|XX] |
- EX|PX 设置过期时间,单位不同;
- NX (Not Exist),表示键不存在才进行操作,XX相反;
多字符串存取
1 | mset key value [key2 value2 ...] |
值的加减
1 | incr key |
key对应的数据不是字符串类型吗?怎么能进行加减操作?这里埋个坑。
hash类型
redis hash 是 字符 filed 和 value 之间的映射表,所以非常适合用于存储对象。比如说key作为对象名,Field作为对象的属性字段,value则是属性字段的值。
基本读写
1 | hset key field value [field value ...] |
查看哈希表的所有field: hkeys key
查看哈希表的所有value:hvals key
查看哈希表的所有field value对:hgetall key
判断一个Key是否存在:hexists key field
应用场景
hash类型一般适合用来存对象,能够独立存储每个字段,如果需要修改某个字段的值,可针对性修改。适合对象字段频繁改变的情况。
string类型也能用来存储对象,首先将对象序列化为Json字符串,再存入Redis。这样的坏处是修改字段麻烦。适合对象字段不怎么改变的情况。
List类型
redis的list相当于Java中的LinkedList,是一个双向链表,可以在头部或者尾部添加元素,当列表弹出最后一个元素后,该结构自动删除。
(1)基本读写
1 | lpush key element [element2] |
lpush 可以将一个或多个值依次插入列表的头部,rpush则将一个或多个值依次插入列表的尾部。
lindex获取指定index的值(注意index从0开始)
(2)删除元素
1 | lpop key |
(3)获取区间元素,注意区间是左闭右闭。
1 | lrange start stop |
(4)插入元素
1 | linsert list BEFORE|AFTER target_element new element |
Set类型
set就是集合,集合的元素不重复无序。Redise的Set底层由哈希表实现,查询复杂度为$O(1)$。
添加一个或多个元素
1 | SADD key element [element2 ...] |
移除一个或多个元素
1 | SREM key element [element2 ..] |
获取集合的所有元素
1 | SMEMBERS key |
判断是否是成员
1 | SISMEMBER key member |
集合应用场景
(1)用户点赞
用户对某条评论点赞。偶数次点赞会取消赞。这就要求用户是否对某条评论点赞的判断。
利用set的是否是成员快速判断用户是否点赞。如果点赞,就将用户id添加到评论的点赞set里。
(2)共同关注
利用集合取交集的命令,就能实现共同关注的功能。
Zset类型
Set是无序集合,ZSet则是有序集合。有序性是因为ZSet中的每个元素关联了一个Score分数,依据分数进行排序。
ZSet的终端命令与Set大体相同,前缀从S换成了Z,并且额外要求一个Score参数。
有序集合应用场景
(1)点赞好友显示
朋友圈点赞头像显示。利用时间戳作为Zset的score,就能以时间排序。
(2)朋友圈滚动分页
用户查看朋友圈其实是查看它的收件箱。如果有新动态发布,那一定是在最顶上。以时间戳作为排序就能实现这种情况。
通用命令
(1)exists 存在命令
1 | exists key |
判断指定的key是否存在
(2)keys 查找命令
1 | keys pattern |
查找指定模式的键,模式匹配(通配符、正则表达式)
(3)rename 重命令
1 | rename key newKeyName |
(4)del 删除key
1 | del key |
(5)ttl 获取键的生存时间
1 | ttl key |
值得注意:在多个键时,可以用冒号为键分隔,达到更好可视化效果
底层数据结构

简单动态字符串
1 | struct sdshdr{ |
SDS类似Java的ArrayList、cpp的vector,动态扩容。虽然底层使用字符数组存储字符,但配合了两个整数变量控制存储空间,这两个变量就是实际所占空间大小和剩余空间大小。
SDS采取预先分配冗余空间策略减少内存的频繁分配。当字符串所占空间小于1M时,成倍扩容。超过1M时,每次只扩容1MB,最多512MB。
压缩链表 ZipList
1 | struct ziplist<T> { |
ZipList与SDS结构相差无几,由连续内存块组成的顺序型数据结构,它有多个entry节点,每个entry节点可以存放整数或者字符串。另外多了几个标志符,字节数、偏移量、长度、结尾标志符。
List 使用压缩链表的情况:List中元素的数量小于或等于16个时,Redis会使用压缩链表进行存储。
hash对象只有同时满足以下条件,才会采用ziplist编码:
- hash对象保存的键和值字符串长度都小于64字节
- hash对象保存的键值对数量小于512
当Zset中元素的数量小于或等于256个时,Redis会使用压缩列表进行存储。
当ziplist作为zset的底层存储结构时候,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员,第二个元素保存元素的分值。
哈希表
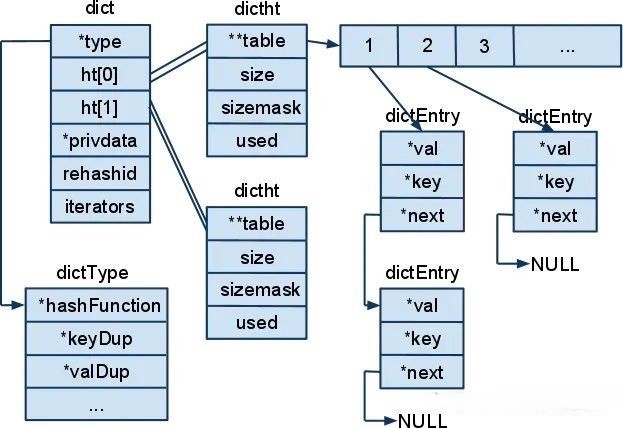
Redis的哈希表实现其实是字典,一个字典中包含了两个哈希表。一个哈希表里面可以有多个槽,而每个槽保存了一个键值对(或者多个,取决于是否有哈希冲突)。
采用开链法解决哈希冲突,当不同key映射到同一个哈希槽时,Redis会采用链表的方式,将后来的节点链接到上一节点。
双哈希表设计:这是一种以空间换时间的技术。特别是应对ReHash过程(哈希表扩容或收缩)。
当哈希表的负载因子超过一定阈值时,就会将0号哈希表上的键值对转移到1号哈希表上。具体过程为:为1号哈希表申请空间,然后重新计算哈希值和索引,并重新插入到 ht[1] 中,插入一个删除一个。当0号哈希表所有元素转移完成时,释放0的空间,然后将1号设为0号。
注意这个数据转移过程可以是一次性操作、也可以是分批次操作(渐进式rehash)。另外因为有两个哈希表,查询时如果0号哈希表查不到,还需要在1号哈希表再查一次,牺牲了一点查询性能。
整数集合
1 | typedef struct intset{ |
当set存的都是整数,且个数小于512个时,底层使用整数集合。
跳跃链表 SkipList
跳表 = 单链表+随机化的多级索引。
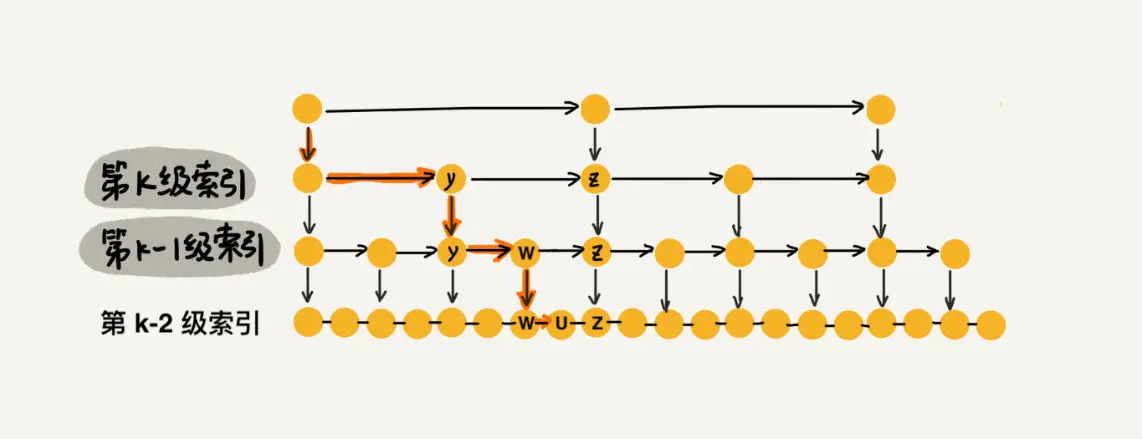
它的基本思想是在链表的基础上,增加多级索引,从而提高数据的查找效率。在一般情况下,它的查找、插入、删除等操作的时间复杂度都为O(log n)。
跳表的核心是索引,它通过维护多级有序链表来实现。每一级索引是原始链表的一部分节点组成,每一级索引的元素数量都比它下一级索引的元素数量少一半。最上面一级索引只有两个节点,第二级索引有四个节点,以此类推。通过这种方式,跳表在空间复杂度和时间复杂度之间做到了平衡。
跳表的查找过程与二分查找类似,先在最高级的索引中查找目标节点,然后通过下降到更低一级的索引再次查找,直到在最底层的索引中找到目标节点或者查找到整个跳表中都没有这个节点。由于跳表的结构不依赖于节点的分布情况,所以它可以用来代替平衡树,实现更高效的查找操作。
1 | 跳跃链表相比红黑树的一些主要好处: |