MIT6824笔记五 Raft
Raft是一个分布式共识算法/协议,即让多台机器达成一致的算法。
Raft将共识问题分解为三部分:Leader选举、Log复制以及安全性设置(一致性设置)。
由于实验2完整复现了Raft协议,这里只挑一些重点讲。复现时应该着重考虑:节点崩溃又上线、不可靠网络。
Leader选举
角色转变
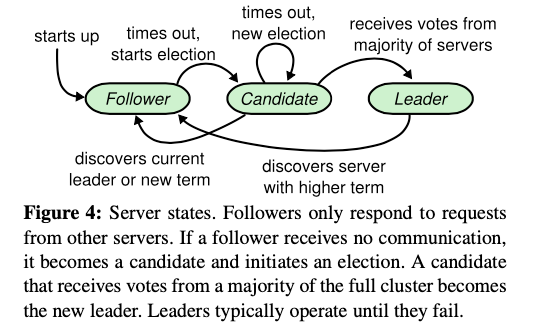
server有三种状态:follower、candidate、leader。分别经过如图所示的过程进行状态转变。
follower和candidate的任务就是等定时器过期发起投票,leader则是发起心跳请求。
当followers选举时间间隔到期后转变为candidate,增加自己的任期号,发起一轮投票;
当leader时,心跳时间间隔开启,选举时间间隔关闭,每隔一段时间向所有node发送空的AppendEntry。
任期机制
发送和回复RPC都要带上自己的任期。任何时刻(收到请求和处理回复)发现自己的任期旧,都要转变身份为follower。
一期一票制度:一个机器在一个任期只能投一票,投票对象VotedFor应该作持久化,避免节点崩溃再次上线重新投票。
投票过程
想明白几个问题:
- 什么时候才能发起投票?
- 发起投票的步骤?
- 收到过半选票后的处理?
- 什么条件下才能为candidate投出自己的选票?
- 选举定时器重置的时间点?
过半票决的好处:
- 在一机一票的场景下,只会产生一个leader节点
- 出现网络分区的时候,只可能有一个分区会有超过一半的服务器互相通信
- 旧leader的过半服务器必然与新leader的过半服务器有重叠,那么就有一个服务器经历过两个任期,它收集了完整的log信息
响应投票:
收到投票RPC消息后,需要比较任期号,驳回旧的任期号投票请求;
如果任期号校验通过,重置选举时间;
当且仅当自己的votedFor为空或为消息中的candidateId时,并且比较自己的log与RPC中的lastLog信息后,才同意投票,并设置自己的votedFor为candidateId。
日志复制
想明白几个问题:
- nextIndex和matchIndex的作用?
- 日志不一致时的回退算法?
- 什么时候日志能提交?怎么避免日志重复提交?
leader只能提交当前任期内的日志。
MIT6824笔记五 Raft