MIT6824笔记七 链式复制
这节课主要介绍了链复制的基本思想以及链复制的改进(Chain Replication with Apportioned Queries,CRAQ)。
CRAQ通过引入版本机制以及clean/dirty状态机制来改进多个节点的分散读。当数据首次到达中间节点时,该数据会被标识为dirty;当数据达到tail节点时,数据标识为clean,并进行反向传播,使之前的节点也将该数据标识为clean。
论文:https://pdos.csail.mit.edu/6.824/papers/craq.pdf
链复制
基本方法

为了保持线性一致的语义,链复制的基本思想是将服务器组成链表,请求从头部开始,一直链式传递到尾部。
写请求发往头部,读请求发往尾部。不同的是,写请求要经过完整的链传递复制,读请求不需要。
具体而言,当链表头部的服务器收到写请求时,它应用写请求,然后传递给下一个服务器。下一个服务器同样应用写请求,再传递下一个服务器。当尾部服务器应用完写请求时,它才回复客户端写请求已经完成。
读请求则十分简单,直接根据尾部服务器的状态读取。没有完成的写请求要么没有传递到尾服务器,要么就是回复丢失。而链复制一次只处理一个请求。所以读请求能看到最新的写请求状态,自然就是线性一致。
故障恢复
链复制的写请求出现故障只有两种情况:要么写请求被所有服务器看到(commited),要么写请求只传递到中间某个服务器。
(1)Head故障
写请求在Head转发前,Head就故障了。那么没有服务器能看到这个写请求,第二个节点成为新的Head。
写请求在Head转发后,Head故障了,那么这个写请求还是会被持续转发下去,所有live服务器都看到这个写请求。
(2)Tail故障
如果TAIL出现故障,处理流程也非常相似,TAIL的前一个节点可以接手成为新的TAIL。所有TAIL知道的信息,TAIL的前一个节点必然都知道,因为TAIL的所有信息都是其前一个节点告知的。
(3)中间节点故障
或许有一些写请求被故障节点接收了,但是还没有被故障节点之后的节点接收,所以,当我们将其从链中移除时,故障节点的前一个节点或许需要重发最近的一些写请求给它的新后继节点。这是恢复中间节点流程的简单版本。
对比Raft
(1)性能
对于Raft,如果我们有一个Leader和一些Follower。Leader需要直接将数据发送给所有的Follower
然而在Chain Replication中,HEAD只需要将写请求发送到一个其他节点。
所以Raft Leader的负担会比Chain Replication中HEAD的负担更高。当客户端请求变多时,Raft Leader会到达一个瓶颈,而不能在单位时间内处理更多的请求。
(2)读写分离
另一个与Raft相比的有趣的差别是,Raft中读请求同样也需要在Raft Leader中处理,所以Raft Leader可以看到所有的请求。而在Chain Replication中,每一个节点都可以看到写请求,但是只有TAIL可以看到读请求。所以负载在一定程度上,在HEAD和TAIL之间分担了,而不是集中在单个Leader节点。
(3)故障恢复
Chain Replication故障恢复更加简单。
配置管理器
Chain Replication并不能抵御网络分区,也不能抵御脑裂。在实际场景中,这意味它不能单独使用。总是会有一个外部的权威(External Authority)来决定谁是活的,谁挂了,并确保所有参与者都认可由哪些节点组成一条链,这样在链的组成上就不会有分歧。这个外部的权威通常称为Configuration Manager。
Configuration Manager的工作就是监测节点存活性,一旦Configuration Manager认为一个节点挂了,它会生成并送出一个新的配置,在这个新的配置中,描述了链的新的定义,包含了链中所有的节点,HEAD和TAIL。Configuration Manager认为挂了的节点,或许真的挂了也或许没有,但是我们并不关心。因为所有节点都会遵从新的配置内容,所以现在不存在分歧了。
现在只有一个角色(Configuration Manager)在做决定,它不可能否认自己,所以可以解决脑裂的问题。
当然,你是如何使得一个服务是容错的,不否认自己,同时当有网络分区时不会出现脑裂呢?答案是,Configuration Manager通常会基于Raft或者Paxos。在CRAQ的场景下,它会基于Zookeeper。而Zookeeper本身又是基于类似Raft的方案。
所以,你的数据中心内的设置通常是,你有一个基于Raft或者Paxos的Configuration Manager,它是容错的,也不会受脑裂的影响。之后,通过一系列的配置更新通知,Configuration Manager将数据中心内的服务器分成多个链。
CRAQ
Chain Replication with Apportioned Queries (CRAQ) 是一种对链式复制的改进,它通过在所有对象副本上分配负载,在保持强一致性的同时极大地提高了读吞吐量。
对象存储
对象存储支持两种基本原语:
read或query操作返回存储在对象名称下的数据块write或update操作更改单个对象的状态
一致性模型
本文涉及到的两种一致性模型为:
- 强一致性:系统保证对一个对象的读写操作都以顺序执行,并且对于一个对象的读操作总是会观察到最新被写入的值。
- 最终一致性:在系统中,对一个对象的写入仍是按顺序在所有节点上应用的,但对不同节点的最终一致性读取可能会在一段时间内(即,在写操作应用于所有节点之前)返回过时的数据。但是,一旦所有副本都接收到写入操作,则读操作将不会返回比最新提交的写操作更早的版本。
链复制
基本方法是将所有存储对象的节点组织在一条链中,其中链的尾节点处理所有读取请求,而链的头节点处理所有写入请求。在客户端收到确认之前,写操作沿链向下传播,因此尾节点可以得到所有对象操作的执行顺序,具有强一致性。该方法没有任何复杂或多轮通信的协议,但是提供了简单、高吞吐量和容易故障恢复的特性。
不幸的是,基础的链复制方法有一些局限性。对一个对象的所有读取都在头节点,从而导致潜在的热点问题。虽然可以通过一致性哈希方法或更中心化的目录方法将集群中的节点组织到多个链中,以实现更好的负载均衡,但是如果特定对象访问较少,这些算法仍然可能会负载不平衡,这在实践中是一个真实的问题。
链式复制的 故障恢复:
- 当头节点出故障时:后续节点取代它成为头节点,没有丢失的已提交写操作
- 当尾节点出故障时:前一个节点取代它成为尾节点,没有丢失的写操作
- 当中间节点故障时:从链中去掉,前一个节点需要重新发送最近的写操作
局限性:对一个对象的所有读取必须都要转到同一个节点,尾节点的负载很大。
CRAQ分散读的改进
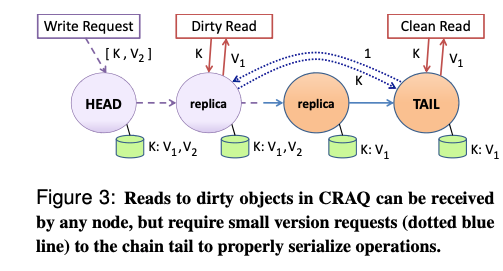
CRAQ的主要思想,在保证强一致性的前提下,通过允许任意节点接收处理client读请求,提升系统读吞吐量。其主要扩展包括:
每个节点都可以存储一个object的多个版本,每个版本包含一个单调递增的版本号和一个表示该版本dirty/clean状态的附加属性。每个版本的初始状态设置为clean。
当节点接收到一个object的新版本时(写入操作沿着复制链传播),将其加入到该object的版本列表中,存在以下两种情况:
- 若该节点不是TAIL节点,则将object的当前版本状态标记为dirty,并传播write请求;
- 若该节点是TAIL节点,则将object的当前版本状态标记为clean,意味着该write请求已committed,并发送ack确认消息(ack消息沿着复制链传播)。
当节点收到一个object的某个版本的ack消息时,将object对应版本状态标记为clean,并删除之前所有的版本。
当节点接收到一个object的读请求时,按照以下方式处理:
- 若object的最新版本状态为clean,则返回该值;
- 否则,向TAIL节点获取该object最新提交的版本号,并返回该版本的值。(TAIL节点在回复object的最新提交版本号之后,可能又提交了新的write请求,但并不破坏强一致性保证:读写请求最终都是由TAIL节点确定执行顺序。)
CRAQ的一致性模型
CRAQ同时提供3种读一致性模型,允许读请求指明可选的一致性类型。
• 强一致性,默认的一致性类型,允许从任意节点均可读取到object最近已提交的数据。
• 最终一致性,从任意节点读,均返回该节点已知的object的最新版本数据(clean)。这可能会导致连续两次从不同节点读取到不一致的数据,因此,不满足单调读一致性保证。
• 具有最大不一致边界的最终一致性,从任意节点能读取到object新写入的未提交的数据(dirty),但需要满足某些限制条件。该模型下,读请求的返回值具有最大不一致的周期(时间或版本号)。对于正常情况下,该不一致表示获取到比最后一次提交的版本更新的版本。对于异常情况下,比如网络分区导致部分节点未参与写请求,该不一致表示获取到比当前已提交的版本更旧的版本。
CRAQ的拓展
MIT6824笔记七 链式复制