实验一的目的是熟悉系统调用以及有限的C标准库使用,借此实现一些经典的unix命令。
在其中碰到了一些bug,大多与字符串解析有关。只记录了几个有意思点的实验。
搭建环境 : docker+目录映射
pingpong 用一个管道就能完成父子进程通信,子进程fork也会复制打开的文件描述符,我看网上好多实现都是双管道。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" int main (int argc, char *argv[]) { int p[2 ]; char buf[128 ]; if (pipe(p)<0 ){ fprintf (2 , "Please enter a number!\n" ); } if (fork()==0 ){ read(p[0 ], buf, 1 ); printf ("%d: received ping\n" , getpid()); char send = 'a' ; write(p[1 ], &send, 1 ); close(p[0 ]); close(p[1 ]); exit (0 ); } write(p[1 ], "x" , 1 ); wait(0 ); read(p[0 ], buf, 1 ); printf ("%d: received pong\n" , getpid()); close(p[1 ]); close(p[0 ]); exit (0 ); }
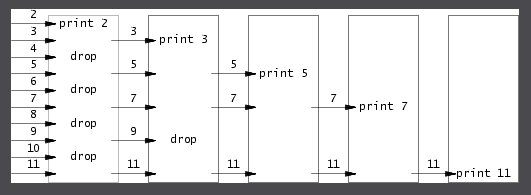
Primes素数筛 思想
首先看图,一个直观的感受就是数字像水一样从左到右流过,中间有一道道关卡,这些关卡会拦截数字,被拦截的数字将不能继续往右走。在这里,一道关卡就是一个进程,它接受来自左边进程的输出,然后它自己再输出给右边的进程。注意到每个进程都只输出一个质数到标准输出。
1 2 3 4 5 6 p = get a number from left neighbor print p loop: n = get a number from left neighbor if (p does not divide n) send n to right neighbor
更正式地描述:每个进程都从左边得到一个数。进程将得到的第一个数(记作A)输出,然后持续从左边拿到一个数(记作A_k)进行判断。如果Ak被A整除了,那么A_k不是质数,丢弃。否则将A_k传递给下一个进程。第一个进程的输出是所有数字(2~N,N取决于你想要的素质范围)。
实现 利用管道作为父子进程的通信,worker函数抽象一个进程的执行流。
在这个实验中,需要额外注意文件描述符的关闭,否则就会因为系统资源不够而无法新开管道。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" void worker (int * p) { close(p[1 ]); int first_num; if (read(p[0 ], &first_num, sizeof (int ))==0 ){ close(p[0 ]); exit (0 ); } printf ("prime %d\n" , first_num); int next_p[2 ]; if (pipe(next_p)<0 ) {fprintf (2 , "create pipe error!\n" ); exit (-1 );} if (fork()==0 ) worker(next_p); close(next_p[0 ]); int next_num; while (read(p[0 ], &next_num, sizeof (int )) != 0 ){ if (next_num % first_num == 0 ) continue ; write(next_p[1 ], &next_num, sizeof (int )); } close(p[0 ]); close(next_p[1 ]); wait(0 ); exit (0 ); } int main (int argc, char *argv[]) { int p[2 ]; if (pipe(p)<0 ) fprintf (2 , "create pipe error!\n" ); if (fork()==0 ){ worker(p); } for (int i=2 ; i<=35 ; ++i){ if (write(p[1 ], &i, 4 )!=4 ) fprintf (2 , "write pipe error!\n" ); } close(p[0 ]); close(p[1 ]); wait(0 ); exit (0 ); }
find 这个实验主要目的是熟悉目录项的数据结构,它是一个包含了目录条目的数组,可以看作树的结构。深度优先搜索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 #include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" char * fmtname (char * path) { static char buf[DIRSIZ+1 ]; char *p; for (p = path + strlen (path); p >= path && *p != '/' ; p--); p ++; if (strlen (p) >= DIRSIZ) return p; memmove(buf, p, strlen (p)); buf[strlen (p)] = 0 ; return buf; } void find (char *root_path, char *file_name) { int fd; char buf[512 ], *p; struct dirent de ; struct stat st ; if ((fd = open(root_path, 0 )) < 0 ){ fprintf (2 , "ls: cannot open %s\n" , root_path); return ; } if (fstat(fd, &st) < 0 ){ fprintf (2 , "ls: cannot stat %s\n" , root_path); close(fd); return ; } if (st.type==T_FILE) { if (strcmp (file_name, fmtname(root_path))==0 ) printf ("%s\n" , root_path); close(fd); return ; } if (strlen (root_path) + 1 + DIRSIZ + 1 > sizeof buf){ printf ("ls: path too long\n" ); } strcpy (buf, root_path); p = buf+strlen (buf); *p++ = '/' ; while (read(fd, &de, sizeof (de)) == sizeof (de)){ if (de.inum == 0 || !strcmp (de.name, "." ) || !strcmp (de.name, ".." )) continue ; memmove(p, de.name, DIRSIZ); p[DIRSIZ] = 0 ; if (stat(buf, &st) < 0 ){ printf ("ls: cannot stat %s\n" , buf); continue ; } if (st.type==T_FILE) { if (strcmp (file_name, de.name)==0 ) printf ("%s\n" , buf); }else if (st.type == T_DIR){ find(buf, file_name); } } close(fd); return ; } int main (int argc, char *argv[]) { if (argc < 2 ){ fprintf (2 , "argc < 2!" ); exit (0 ); } find(argv[1 ], argv[2 ]); exit (0 ); }
xargs 解读 不熟悉xargs命令可能会有点懵,它其实是读取标准输出中的字符,然后把它当作命令行的额外参数。
1 echo hello too | xargs echo bye
它会输出
相当于执行了命令
这个实验要注意的一点就是输入数据可能有多行,需要一行一行的解析参数,然后这些参数都要复制执行一遍。有n行就要执行n个命令。
实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #include "kernel/types.h" #include "kernel/stat.h" #include "kernel/param.h" #include "user/user.h" void copy (char **p1, char *p2) { *p1 = malloc (strlen (p2) + 1 ); strcpy (*p1, p2); } int read_parse_one_line (char ** argv, int argc) { int i=0 ; char buffer[1024 ]; char * buf = buffer; while (read(0 , buf+i, 1 )){ if (buf[i]=='\n' ) break ; ++i; } if (i==0 ) return -1 ; buf[i] = ' ' ; char * delim; while (*buf && (*buf==' ' )) buf++; while ((delim = strchr (buf, ' ' ))) { *delim = 0 ; copy(&argv[argc], buf); buf = delim+1 ; argc = argc+1 ; while (*buf && (*buf==' ' )) buf++; } argv[argc] = 0 ; return argc; } int main (int argc, char *argv[]) { if (argc < 2 ){ printf ("Please enter more parameters!\n" ); exit (1 ); } char *pars[MAXARG]; for (int i = 1 ; i < argc; i++){ copy(&pars[i - 1 ], argv[i]); } while (read_parse_one_line(pars, argc-1 )!=-1 ){ if (fork() == 0 ){ exec(pars[0 ], pars); exit (1 ); }else { wait(0 ); } } exit (0 ); }
踩坑 这里的parseline其实是修改了csapp的图8-25解析shell的一个输入行的代码。
但是有一点不同是csapp通过fgets函数读取一行的输入,fgets读取的输入将包括换行符。而strlen函数计算字符串长度时,也会将换行符计算在内,所以这里的buf[strlen(buf)-1] = ' ';取代换行符的操作就出错了。
总结 难点 实验一的难点在于熟悉系统调用以及C系统库。熟悉系统调用其实就是熟悉进程、管道、文件描述符这些核心概念。
1 2 3 4 5 6 7 8 9 10 int fork (void ) ;int exit (int ) __attribute__ ((noreturn )) ;int wait (int *) ;int pipe (int *) ;int write (int , const void *, int ) ;int read (int , void *, int ) ;int close (int ) ;int exec (char *, char **) ;int open (const char *, int ) ;int sleep (int ) ;
系统调用的实现可能会有点困难,此时只需要理解如何使用,下一章会详细其实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int atoi (const char *) ;uint strlen (const char *) ; char * strcpy (char *, const char *) ;char * strchr (const char *, char c) ;int strcmp (const char *, const char *) ;char * gets (char *, int max) ;void printf (const char *, ...) ;void fprintf (int , const char *, ...) ;void * memset (void *, int , uint) ;void * memmove (void *, const void *, int ) ;void * memcpy (void *, const void *, uint) ;int memcmp (const void *, const void *, uint) ;
C标准库的实现有必要好好读一读。
关于C 阻碍可读性的一个很大关键问题就是C的指针以及类型不安全特性。
(1)类型不安全
类型不安全一个经典的场景在于if的判断条件,可以把整数转换为布尔值,只有0是失败,其他都是成功。
(2)指针
1 2 3 4 *p++ char * arr[] void (*fun)(void ) void (*fun[])(void )
*和++一起用就很有迷惑性,到底是哪个先作用?答案是++。
利用指针操作字符串也需要谨慎操作。