MIT6.S081 xv6book chapter4
第四章的主题是陷阱与系统调用。关键问题:系统调用是怎么从用户态切换到内核态的?
从中断角度看,系统调用是一软中断,发生中断后由中断向量处理,其中中断向量的地址又在寄存器stvec上。
这里融合了lec06的内容 和lec08的内容,lec08讲述了page fault中断处理的妙用,核心思想都是懒分配:给你虚拟页但不实际分配物理页,等到实际要用时再分配。
前言
什么时候需要用户态到内核态的切换?
- 程序执行系统调用;
- 程序出现了类似page fault、运算时除以0的错误;
- 一个设备触发了中断使得当前程序运行需要响应内核设备驱动。
这里用户空间和内核空间的切换通常被称为trap,而trap涉及了许多小心的设计和重要的细节,这些细节对于实现安全隔离和性能来说非常重要。trap机制要尽可能的简单来应对频繁的切换。
我们需要清楚如何让程序的运行,从只拥有user权限并且位于用户空间的Shell,切换到拥有supervisor权限的内核。在这个过程中,硬件的状态将会非常重要,因为我们很多的工作都是将硬件从适合运行用户应用程序的状态,改变到适合运行内核代码的状态。
应用程序的用户寄存器,像a0如此的有32个,此外还有一些特别的寄存器:
- stvec:The kernel writes the address of its trap handler here
- sepc:When a trap occurs, RISC-V saves the program counter here
- scause:RISC-V puts a number here that describes the reason for the trap.
- sscratch
- sstatus:硬件中断、一些标识位
- satp:保存pagetable的地址
这些寄存器的值表明了执行系统调用时的计算机状态。那么执行trap时,我们需要做的事:
- 保存状态(包括32个寄存器、pc等)
- 将mode切换为supervisor,这样才能执行特权指令
- 切换satp页表为内核页表
- 设置堆栈寄存器指向内核中一个地址,这样内核的C函数才能使用栈
- 一旦设置好以上状态,跳入内核的C代码开始执行
要怎么实现?操作系统的一些high-level的目标能帮我们过滤一些实现选项。其中一个目标是安全和隔离,我们不想让用户代码介入到这里的user/kernel切换,否则有可能会破坏安全性。所以这意味着,trap中涉及到的硬件和内核机制不能依赖任何来自用户空间的东西。XV6的trap机制不会查看这些寄存器,而只是将它们保存起来。
Supervisor mode下能够执行的操作:
其中的一件事情是,你现在可以读写控制寄存器了。比如说,当你在supervisor mode时,你可以:读写SATP寄存器,也就是page table的指针;STVEC,也就是处理trap的内核指令地址;SEPC,保存当发生trap时的程序计数器;SSCRATCH等等。在supervisor mode你可以读写这些寄存器,而用户代码不能做这样的操作。
另一件事情supervisor mode可以做的是,它可以使用PTE_U标志位为0的PTE。当PTE_U标志位为1的时候,表明用户代码可以使用这个页表;如果这个标志位为0,则只有supervisor mode可以使用这个页表。
需要特别指出的是,supervisor mode中的代码并不能读写任意物理地址。在supervisor mode中,就像普通的用户代码一样,也需要通过page table来访问内存。如果一个虚拟地址并不在当前由SATP指向的page table中,又或者SATP指向的page table中PTE_U=1,那么supervisor mode不能使用那个地址。所以,即使我们在supervisor mode,我们还是受限于当前page table设置的虚拟地址。
shell执行write系统调用

上图是系统调用的大致流程。//todo 简述每一个过程
ecall
1 | .global write |
shell执行write系统调用实际是执行usys.S中的这段代码,其中透过ecall指令执行系统调用。
ecall指令做的事情:(实际上对应book第44页末尾那段硬件操作)
- ecall将mode从user mode改到supervisor mode;
- ecall将程序计数器的值保存在了SEPC寄存器;
- ecall会跳转到STVEC寄存器指向的指令。
所以现在,ecall帮我们做了一点点工作,但是实际上我们离执行内核中的C代码还差的很远。接下来:
- 我们需要保存32个用户寄存器的内容,这样当我们想要恢复用户代码执行时,我们才能恢复这些寄存器的内容。
- 因为现在我们还在user page table,我们需要切换到kernel page table。
- 我们需要创建或者找到一个kernel stack,并将Stack Pointer寄存器的内容指向那个kernel stack。这样才能给C代码提供栈。
- 我们还需要跳转到内核中C代码的某些合理的位置。
为什么ecall不多做点工作来将代码执行从用户空间切换到内核空间呢?为什么ecall不会保存用户寄存器,或者切换page table指针来指向kernel page table,或者自动的设置Stack Pointer指向kernel stack,或者直接跳转到kernel的C代码,而不是在这里运行复杂的汇编代码?
原因是RISC的设计思想,尽可能的简单且通用,让用户完成自定义的操作。然后这样做的代价就是性能不是特别好。
uservec
现在指令来到了TRAMPOLINE的vuservec。为什么会来这?是因为内核设置了stvec寄存器的值为这里。每个进程创建时都会映射TRAMPOLINE页面在虚拟地址的最高处,内容初始化为trampoline.S的代码。
1 | .globl uservec |
现在已经是supervisor mode,但还没完成状态保存。
怎么保存状态?或许直接将32个寄存器中的内容写到物理内存中某些合适的位置,但此时还没完成页表的切换,并且在trap代码当前的位置,也就是trap机制的最开始,我们并不知道kernel page table的地址。并且更改SATP寄存器的指令,要求写入SATP寄存器的内容来自于另一个寄存器。
答案是用户地址空间的trapframe页。在创建用户进程时预先分配好这个页面来保存寄存器的值。
怎么知道trapframe页的虚拟地址?答案是SSCRATCH寄存器。所以uservec的第一条指令是csrrw a0, sscratch, a0交换寄存器的值,然后就能用a0寄存器干活儿了。保存完其他寄存器值后,还要记得保存原始a0寄存器的值(目前在SScRATCH寄存器上)。
然后加载内核sp指针,trapframe中的kernel_sp是由kernel在进入用户空间之前就设置好的,它的值是这个进程的kernel stack。
然后就是核心的保存,设置跳转地址,切换内核页表,最后跳转到内核C代码。
为什么切换内核页表后,还能正确的执行跳转指令?
答:因为我们还在trampoline代码中,而trampoline代码在用户空间和内核空间都映射到了同一个地址。
usertrap()
1 | // kernel/trap.c |
usertrap最主要的作用就是判断中断类型,根据中断类型做出相应的处理。
这里看系统调用的流程, p->trapframe->epc += 4;是为了能在中断返回时返回到下一条指令,也就是ecall下一条指令ret。然后就调用syscall函数。
sysycall()
1 | // kernel/syscall.c |
这段代码写得非常简单,从a7寄存器中获取系统调用号然后根据哈希表查询执行相应的系统调用,将返回值保存在a0寄存器中。
usertrapret() 返回
1 | // kernel/trap.c |
usertrapret最主要的作用就是设置返回到用户空间之前内核要做的工作。
重新设置stvec为用户中断向量,然后就是几个内核相关的寄存器值(这样下一次从用户空间转换到内核空间时可以用到这些数据)。
接下来我们要设置SSTATUS寄存器,这是一个控制寄存器。这个寄存器的SPP bit位控制了sret指令的行为,该bit为0表示下次执行sret的时候,我们想要返回user mode而不是supervisor mode。这个寄存器的SPIE bit位控制了,在执行完sret之后,是否打开中断。因为我们在返回到用户空间之后,我们的确希望打开中断,所以这里将SPIE bit位设置为1。修改完这些bit位之后,我们会把新的值写回到SSTATUS寄存器。
trampoline代码的最后执行了sret指令。这条指令会将程序计数器设置成SEPC寄存器的值。所以现在设置sepc为epc值,用于返回到正确位置。
倒数第二行的作用是计算出我们将要跳转到汇编代码的地址。我们期望跳转的地址是tampoline中的userret函数,这个函数包含了所有能将我们带回到用户空间的指令。所以这里我们计算出了userret函数的地址。
倒数第一行,将fn指针作为一个函数指针,执行相应的函数(也就是userret函数)并传入两个参数,两个参数存储在a0,a1寄存器中。
实际上,我们会在汇编代码trampoline中完成page table的切换,并且也只能在trampoline中完成切换,因为只有trampoline中代码是同时在用户和内核空间中映射。但是我们现在还没有在trampoline代码中,我们现在还在一个普通的C函数中,所以这里我们将page table指针准备好,并将这个指针作为第二个参数传递给汇编代码,这个参数会出现在a1寄存器。
userret
1 | userret: |
现在程序执行又回到了trampoline代码。
第二步中,a0是上一步传入的trampoline地址,然后通过trampoline找到a0寄存器(保存了系统调用返回值),再保存在sscratch中。
第四步,让sscratch保存trampframe(这样下一次trap又能用了),同时恢复a0。
sret是我们在kernel中的最后一条指令,当我执行完这条指令:
- 程序会切换回user mode
- SEPC寄存器的数值会被拷贝到PC寄存器(程序计数器)
- 重新打开中断
这将会返回到ret指令,ret指令位于ecal指令下一条。
ret
现在我们回到了用户空间,执行完ret指令之后我们就可以从write系统调用返回到Shell中了。或者更严格的说,是从触发了系统调用的write库函数中返回到Shell中。
最后总结一下,系统调用被刻意设计的看起来像是函数调用,但是背后的user/kernel转换比函数调用要复杂的多。之所以这么复杂,很大一部分原因是要保持user/kernel之间的隔离性,内核不能信任来自用户空间的任何内容。
另一方面,XV6实现trap的方式比较特殊,XV6并不关心性能。但是通常来说,操作系统的设计人员和CPU设计人员非常关心如何提升trap的效率和速度。
PageFault
首先,我们需要思考的是,什么样的信息对于page fault是必须的。或者说,当发生page fault时,内核需要什么样的信息才能够响应page fault。
引起page fault的内存地址
引起page fault的原因类型
引起page fault时的程序计数器值,这表明了page fault在用户空间发生的位置
当出现page fault的时候,XV6内核会打印出错的虚拟地址,并且这个地址会被保存在STVAL寄存器中。
我们需要知道的第二个信息是出错的原因,比如因为load指令触发的page fault、因为store指令触发的page fault又或者是因为jump指令触发的page fault。出错原因存在SCAUSE寄存器中,其中总共有3个类型的原因与page fault相关,分别是读、写和指令。
我们或许想要知道的第三个信息是触发page fault的指令的地址。从上节课可以知道,作为trap处理代码的一部分,这个地址存放在SEPC寄存器中,并同时会保存在trapframe->epc中。
由于页表提供了一种非常有用的抽象,隔离性与抽象管理,这使得我们有许多优化可以进行,这些优化基本都是按照懒加载的思想进行。
在进行这些优化时,我们需要时常思考,page fault什么时候会产生以及产生page fault时的行为。
Lazy Allocation
我们首先来看一下内存allocation,或者更具体的说sbrk,它使得用户应用程序能扩大自己的heap。当一个应用程序启动的时候,sbrk指向的是heap的最底端,同时也是stack的最顶端。这个位置通过代表进程的数据结构中的sz字段表示,这里以p->sz表示。
这意味着,当sbrk实际发生或者被调用的时候,内核会分配一些物理内存,并将这些内存映射到用户应用程序的地址空间,然后将内存内容初始化为0,再返回sbrk系统调用。

在XV6中,sbrk的实现默认是eager allocation,这表示,一旦调用了sbrk,内核会立即分配应用程序所需要的物理内存。
但是实际上,应用程序来说很难预测自己需要多少内存。通常来说,应用程序倾向于申请多于所需的内存。这意味着,进程的内存消耗会增加许多,但是有部分内存永远也不会被应用程序所使用到。
lazy allocation的核心思想非常简单,sbrk系统调基本上不做任何事情,唯一需要做的事情就是提升p->sz,将p->sz增加n,其中n是需要新分配的内存page数量。但是内核在这个时间点并不会分配任何物理内存。之后在某个时间点,应用程序使用到了新申请的那部分内存,这时会触发page fault,因为我们还没有将新的内存映射到page table。
所以,如果我们解析一个大于旧的p->sz,但是又小于新的p->sz(注,也就是旧的p->sz + n)的虚拟地址,我们希望内核能够分配一个内存page,并且重新执行指令。
实际上,lazy allocation会复杂一些。如果我们扩大用户内存而没实际分配页面时,要注意进程结束释放未分配的页面内存回收(实际上会回收空值);如果sbrk传入负数,也要注意回收的内存是否实际分配页面。
Zero Fill On Demand
首先,当你查看一个用户程序的地址空间时,存在text区域,data区域,同时还有一个BSS区域(BSS区域包含了未被初始化或者初始化为0的全局或者静态变量)。
之所以这些变量要单独列出来,是因为例如你在C语言中定义了一个大的全局变量,它的元素初始值都是0,为什么要为这个变量分配内存呢?其实只需要记住这个变量的内容是0就行。

通常可以调优的地方是,我有如此多的内容全是0的page,在物理内存中,我只需要分配一个page,这个page的内容全是0。然后将所有虚拟地址空间的全0的page都map到这一个物理page上。这样至少在程序启动的时候能节省大量的物理内存分配。
当然这里的mapping需要非常的小心,我们不能允许对于这个page执行写操作,因为所有的虚拟地址空间page都期望page的内容是全0,所以这里的PTE都是只读的。之后在某个时间点,应用程序尝试写BSS中的一个page时,比如说需要更改一两个变量的值,我们会得到page fault。
那么,对于这个特定场景中的page fault我们该做什么呢?
学生回答:我认为我们应该创建一个新的page,将其内容设置为0,并重新执行指令。
假设store指令发生在BSS最顶端的page中。我们想要做的是,在物理内存中申请一个新的内存page,将其内容设置为0,因为我们预期这个内存的内容为0。之后我们需要更新这个page的mapping关系,首先PTE要设置成可读可写,然后将其指向新的物理page。这里相当于更新了PTE,之后我们可以重新执行指令。
好处:
- 假设程序申请了一个大的数组,来保存可能的最大的输入,并且这个数组是全局变量且初始为0。但是最后或许只有一小部分内容会被使用。
- 第二个好处是在exec中需要做的工作变少了。程序可以启动的更快,这样你可以获得更好的交互体验,因为你只需要分配一个内容全是0的物理page。
坏处是多次page fault代价更大。
Copy On Write Fork
当Shell处理指令时,它会通过fork创建一个子进程。Shell的子进程执行的第一件事情就是调用exec运行一些其他程序,比如运行echo。现在的情况是,fork创建了Shell地址空间的一个完整的拷贝,而exec做的第一件事情就是丢弃这个地址空间,取而代之的是一个包含了echo的地址空间。这里看起来有点浪费。
所以对于这个特定场景有一个非常有效的优化:当我们创建子进程时,与其创建,分配并拷贝内容到新的物理内存,其实我们可以直接共享父进程的物理内存page。所以这里,我们可以设置子进程的PTE指向父进程对应的物理内存page。

一旦子进程想要修改这些内存的内容,相应的更新应该对父进程不可见,因为我们希望在父进程和子进程之间有强隔离性,所以这里我们需要更加小心一些。为了确保进程间的隔离性,我们可以将这里的父进程和子进程的PTE的标志位都设置成只读的。
在某个时间点,当我们需要更改内存的内容时,我们会得到page fault。在得到page fault之后,我们需要拷贝相应的物理page。假设现在是子进程在执行store指令,那么我们会分配一个新的物理内存page,然后将page fault相关的物理内存page拷贝到新分配的物理内存page中,并将新分配的物理内存page映射到子进程。这时,新分配的物理内存page只对子进程的地址空间可见,所以我们可以将相应的PTE设置成可读写,并且我们可以重新执行store指令。实际上,对于触发刚刚page fault的物理page,因为现在只对父进程可见,相应的PTE对于父进程也变成可读写的了。
学生提问:我们如何发现父进程写了这部分内存地址?是与子进程相同的方法吗?
Frans教授:是的,因为子进程的地址空间来自于父进程的地址空间的拷贝。如果我们使用了特定的虚拟地址,因为地址空间是相同的,不论是父进程还是子进程,都会有相同的处理方式。
学生提问:对于一些没有父进程的进程,比如系统启动的第一个进程,它会对于自己的PTE设置成只读的吗?还是设置成可读写的,然后在fork的时候再修改成只读的?
Frans教授:这取决于你。实际上在lazy lab之后,会有一个copy-on-write lab。在这个lab中,你自己可以选择实现方式。当然最简单的方式就是将PTE设置成只读的,当你要写这些page时,你会得到一个page fault,之后你可以再按照上面的流程进行处理。
学生提问:当发生page fault时,我们其实是在向一个只读的地址执行写操作。内核如何能分辨现在是一个copy-on-write fork的场景,而不是应用程序在向一个正常的只读地址写数据。是不是说默认情况下,用户程序的PTE都是可读写的,除非在copy-on-write fork的场景下才可能出现只读的PTE?
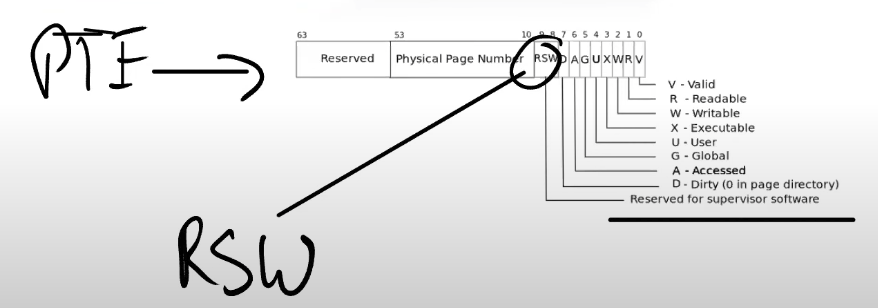
Frans教授:内核必须要能够识别这是一个copy-on-write场景。几乎所有的page table硬件都支持了这一点。我们之前并没有提到相关的内容,下图是一个常见的多级page table。对于PTE的标志位,我之前介绍过第0bit到第7bit,但是没有介绍最后两位RSW。这两位保留给supervisor software使用,supervisor softeware指的就是内核。内核可以随意使用这两个bit位。所以可以做的一件事情就是,将bit8标识为当前是一个copy-on-write page。
对于这里的物理内存page,现在有多个用户进程或者说多个地址空间都指向了相同的物理内存page,举个例子,当父进程退出时我们需要更加的小心,因为我们要判断是否能立即释放相应的物理page。如果有子进程还在使用这些物理page,而内核又释放了这些物理page,我们将会出问题。那么现在释放内存page的依据是什么呢?
我们需要对于每一个物理内存page的引用进行计数,当我们释放虚拟page时,我们将物理内存page的引用数减1,如果引用数等于0,那么我们就能释放物理内存page。
Demand Paging
我们回到exec,在未修改的XV6中,操作系统会加载程序内存的text,data区域,并且以eager的方式将这些区域加载进page table。
为什么我们要以eager的方式将程序加载到内存中?为什么不再等等,直到应用程序实际需要这些指令的时候再加载内存?程序的二进制文件可能非常的巨大,将它全部从磁盘加载到内存中将会是一个代价很高的操作。又或者data区域的大小远大于常见的场景所需要的大小,我们并不一定需要将整个二进制都加载到内存中。
所以对于exec,在虚拟地址空间中,我们为text和data分配好地址段,但是相应的PTE并不对应任何物理内存page。对于这些PTE,我们只需要将valid bit位设置为0即可。
接下来思考什么时候会触发page fault:应用程序是从地址0开始运行,位于地址0的指令会出发第一个page fault。
然后就是触发page fault的行为:首先我们可以发现,这些page是on-demand page。我们需要在某个地方记录了这些page对应的程序文件,我们在page fault handler中需要从程序文件中读取page数据,加载到内存中;之后将内存page映射到page table;最后再重新执行指令。
在最坏的情况下,用户程序使用了text和data中的所有内容,那么我们将会在应用程序的每个page都收到一个page fault。但是如果我们幸运的话,用户程序并没有使用所有的text区域或者data区域,那么我们一方面可以节省一些物理内存,另一方面我们可以让exec运行的更快。
在lazy allocation中,如果内存耗尽了该如何办?一个选择是撤回page(evict page)。比如说将部分内存page中的内容写回到文件系统再撤回page。一旦你撤回并释放了page,那么你就有了一个新的空闲的page,你可以使用这个刚刚空闲出来的page,分配给刚刚的page fault handler,再重新执行指令。
问题又来了,什么样的page可以被撤回?并且该使用什么样的策略来撤回page?常用的策略,Least Recently Used,或者叫LRU,除了这个策略之外,还有一些其他的小优化。如果你要撤回一个page,你可以在dirty page和non-dirty page中做选择。
如果你们再看PTE,还有其他信息。当硬件向一个page写入数据,会设置dirty bit,之后操作系统就可以发现这个page曾经被写入了。类似的,还有一个Access bit,任何时候一个page被读或者被写了,这个Access bit会被设置。
为什么这两个信息重要(access bit & dirty bit)呢?它们能怎样帮助内核呢?
学生回答:没有被Access过的page可以直接撤回,是吗?
Frans教授:是的,或者说如果你想实现LRU,你需要找到一个在一定时间内没有被访问过的page,那么这个page可以被用来撤回。而被访问过的page不能被撤回。所以Access bit通常被用来实现这里的LRU策略。
学生提问:那是不是要定时的将Access bit恢复成0?
Frans教授:是的,这是一个典型操作系统的行为。操作系统会扫描整个内存,这里有一些著名的算法例如clock algorithm,就是一种实现方式。
另一个学生提问:为什么需要恢复这个bit?
Frans教授:如果你想知道page最近是否被使用过,你需要定时比如每100毫秒或者每秒清除Access bit,如果在下一个100毫秒这个page被访问过,那你就知道这个page在上一个100毫秒中被使用了。而Access bit为0的page在上100毫秒未被使用。这样你就可以统计每个内存page使用的频度,这是一个成熟的LRU实现的基础。(注,可以通过Access bit来决定内存page 在LRU中的排名)
Memory Mapped Files
这里的核心思想是,将完整或者部分文件加载到内存中,这样就可以通过内存地址相关的load或者store指令来操纵文件,避免缓慢的文件系统交互读写read/write。
现代操作系统一般会提供一个mmap系统调用,这个系统调用会接收一个虚拟内存地址(VA),长度(len),protection,一些标志位,一个打开文件的文件描述符,和偏移量(offset)。语义是,从文件描述符对应的文件的偏移量的位置开始,映射长度为len的内容到虚拟内存地址VA,同时我们需要加上一些保护,比如只读或者读写。
假设文件内容是读写并且内核实现mmap的方式是eager方式(不过大部分系统都不会这么做),内核会从文件的offset位置开始,将数据拷贝到内存,设置好PTE指向物理内存的位置。之后应用程序就可以使用load或者store指令来修改内存中对应的文件内容。当完成操作之后,会有一个对应的unmap系统调用,参数是虚拟地址(VA),长度(len)。来表明应用程序已经完成了对文件的操作,在unmap时间点,我们需要将dirty block写回到文件中。
当然,在任何聪明的内存管理机制中,所有的这些都是以lazy的方式实现。你不会立即将文件内容拷贝到内存中,而是先记录一下这个PTE属于这个文件描述符。相应的信息通常在VMA结构体中保存,VMA全称是Virtual Memory Area。例如对于这里的文件f,会有一个VMA,在VMA中我们会记录文件描述符,偏移量等等,这些信息用来表示对应的内存虚拟地址的实际内容在哪,这样当我们得到一个位于VMA地址范围的page fault时,内核可以从磁盘中读数据,并加载到内存中。
学生提问:如果其他进程直接修改了文件的内容,那么是不是意味着修改的内容不会体现在这里的内存中?
Frans教授:是的。但是如果文件是共享的,那么你应该同步这些变更。我记不太清楚在mmap中,文件共享时会发生什么。
MIT6.S081 xv6book chapter4
https://xyz.desirer233.fun/2024/01/07/MIT6.S081/book/chapter4/