MIT6.S081 xv6book chapter7
第七章讲述了xv6中线程调度的机制,核心就是swtch函数以及调度器内核线程。在线程调度的基础上,讲述了线程同步的一个机制:sleep&wakeup(其实就是条件变量)。有了同步机制后,继续展开讲进程退出、资源回收等知识。fork+exec+wait 一套流程。
融合了lec11和lec13的内容,两节课的内容,收获颇丰。
线程概述
首先,线程可以认为是一种在有多个任务时简化编程的抽象。线程是串行执行代码的单元,尽管有许多不同线程的定义,在这里我们可以认为线程就是但个串行执行代码的单元,它只占用一个CPU并且以普通的方式一个接一个执行指令。
除此之外,线程还具有状态,我们可以随时保存线程的状态并暂停线程的运行,并在之后通过恢复状态来恢复线程的运行。
线程的状态包括:
- 程序计数器
- 寄存器
- 栈(Stack记录了函数调用的记录,并反映了当前线程的执行点)
多线程的并行运行主要有两个策略:
多核处理器,每个CPU对应运行一个线程,每个线程自动的根据所在CPU就有了程序计数器和寄存器。
一个CPU对应多个线程,一个CPU在多个线程之间来回切换。
实际上,与大多数其他操作系统一样,XV6结合了这两种策略,首先线程会运行在所有可用的CPU核上,其次每个CPU核会在多个线程之间切换,因为通常来说,线程数会远远多于CPU的核数。xv6的线程切换主要是时间片轮转(先运行一个线程,之后将线程的状态保存,再切换至运行第二个线程,然后再是第三个线程,依次类推直到每个线程都运行了一会,再回来重新执行第一个线程)
不同线程系统之间的一个主要的区别就是,线程之间是否会共享内存。一种可能是你有一个地址空间,多个线程都在这一个地址空间内运行,并且它们可以看到彼此的更新。
XV6内核共享了内存,并且XV6支持内核线程的概念,对于每个用户进程都有一个内核线程来执行来自用户进程的系统调用。所有的内核线程都共享了内核内存,所以XV6的内核线程的确会共享内存。
多核能够进行线程切换的前提是:多个CPU核心共享同一套内存。
xv6线程调度
线程调度的难点:
第一个是如何实现线程间的切换。这里停止一个线程的运行并启动另一个线程的过程通常被称为线程调度(Scheduling)。
第二个挑战是,当你想要实际实现从一个线程切换到另一个线程时,你需要保存并恢复线程的状态,所以需要决定线程的哪些信息是必须保存的,并且在哪保存它们。
最后一个挑战是如何处理运算密集型线程(compute bound thread)。对于线程切换,很多直观的实现是由线程自己自愿的保存自己的状态,再让其他的线程运行。但是如果我们有一些程序正在执行一些可能要花费数小时的长时间计算任务,这样的线程并不能自愿的出让CPU给其他的线程运行。所以这里需要能从长时间运行的运算密集型线程撤回对于CPU的控制,将其放置于一边,稍后再运行它。
处理运算密集线程的答案就是定时器中断,定时器中断(比如说每隔10ms触发),能将程序运行的控制权从用户空间代码切换到内核中的中断处理程序。这里的基本流程是,定时器中断将CPU控制权给到内核,内核再自愿的出让CPU。
在执行线程调度的时候,调度程序需要能区分几类线程:
- 当前在CPU上运行的线程 RUNNING
- 一旦CPU有空闲时间就想要运行在CPU上的线程 RUNABLE
- 以及不想运行在CPU上的线程,因为这些线程可能在等待I/O或者其他事件 SLEEPING
对于RUNNING状态下的线程,它的程序计数器和寄存器位于正在运行它的CPU硬件中。UNABLE线程需要保存它的状态信息,我们需要拷贝的信息就是程序计数器(Program Counter)和寄存器。当线程调度器决定要运行一个RUNABLE线程时,这里涉及了很多步骤,但是其中一步是将之前保存的程序计数器和寄存器拷贝回调度器对应的CPU中。
学生提问:当一个线程结束执行了,比如说在用户空间通过exit系统调用结束线程,同时也会关闭进程的内核线程。那么线程结束之后和下一个定时器中断之间这段时间,CPU仍然会被这个线程占有吗?还是说我们在结束线程的时候会启动一个新的线程?
Robert教授:exit系统调用会出让CPU。尽管我们这节课主要是基于定时器中断来讨论,但是实际上XV6切换线程的绝大部分场景都不是因为定时器中断,比如说一些系统调用在等待一些事件并决定让出CPU。exit系统调用会做各种操作然后调用yield函数来出让CPU,这里的出让并不依赖定时器中断。
线程切换过程
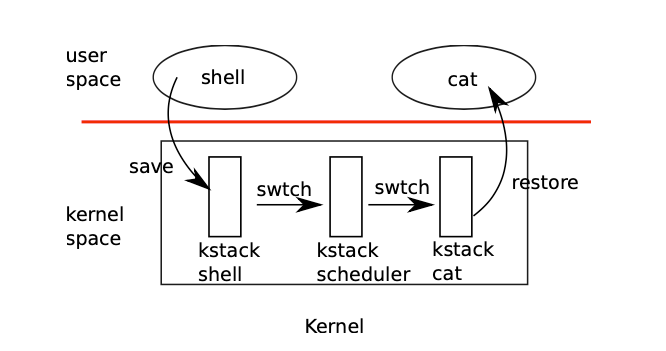
xv6实现线程切换相当曲折:
- 首先用户程序会因为定时器中断陷入内核(走到内核线程),此时用户空间的状态已经保存在trapframe中;
- 从第一个用户内核线程切换到内核线程调度线程;
- 线程调度程序再切换到第二个用户内核线程;
- 第二个用户进程从内核态返回到用户态。
其中,从一个内核线程切换到另一个内核线程,需要保存旧线程的状态到context对象中,然后恢复从新的contex对象恢复另一个内核线程的状态(其实就是调用swtch函数)
学生提问:context保存在哪?
Robert教授:每一个内核线程都有一个context对象。但是内核线程实际上有两类。每一个用户进程有一个对应的内核线程,它的context对象保存在用户进程对应的proc结构体中。
每一个调度器线程,它也有自己的context对象,但是它却没有对应的进程和proc结构体,所以调度器线程的context对象保存在cpu结构体中。在内核中,有一个cpu结构体的数组,每个cpu结构体对应一个CPU核,每个结构体中都有一个context字段。
学生提问:为什么不能将context对象保存在进程对应的trapframe中?
Robert教授:context可以保存在trapframe中,因为每一个进程都只有一个内核线程对应的一组寄存器,我们可以将这些寄存器保存在任何一个与进程一一对应的数据结构中。对于每个进程来说,有一个proc结构体,有一个trapframe结构体,所以我们可以将context保存于trapframe中。但是或许出于简化代码或者让代码更清晰的目的,trapframe还是只包含进入和离开内核时的数据。而context结构体中包含的是在内核线程和调度器线程之间切换时,需要保存和恢复的数据。
学生提问:出让CPU是由用户发起的还是由内核发起的?
Robert教授:对于XV6来说,并不会直接让用户线程出让CPU或者完成线程切换,而是由内核在合适的时间点做决定。有的时候你可以猜到特定的系统调用会导致出让CPU,例如一个用户进程读取pipe,而它知道pipe中并不能读到任何数据,这时你可以预测读取会被阻塞,而内核在等待数据的过程中会运行其他的进程。
内核会在两个场景下出让CPU。当定时器中断触发了,内核总是会让当前进程出让CPU,因为我们需要在定时器中断间隔的时间点上交织执行所有想要运行的进程。另一种场景就是任何时候一个进程调用了系统调用并等待I/O,例如等待你敲入下一个按键,在你还没有按下按键时,等待I/O的机制会触发出让CPU。
学生提问:每一个CPU的调度器线程有自己的栈吗?
Robert教授:是的,每一个调度器线程都有自己独立的栈。实际上调度器线程的所有内容,包括栈和context,与用户进程不一样,都是在系统启动时就设置好了。如果你查看XV6的start.s(注:是entry.S和start.c)文件,你就可以看到为每个CPU核设置好调度器线程。
学生提问:我们这里一直在说线程,但是从我看来XV6的实现中,一个进程就只有一个线程,有没有可能一个进程有多个线程?
Robert教授:我们这里的用词的确有点让人混淆。在XV6中,一个进程要么在用户空间执行指令,要么是在内核空间执行指令,要么它的状态被保存在context和trapframe中,并且没有执行任何指令。这里该怎么称呼它呢?你可以根据自己的喜好来称呼它,对于我来说,每个进程有两个线程,一个用户空间线程,一个内核空间线程,并且存在限制使得一个进程要么运行在用户空间线程,要么为了执行系统调用或者响应中断而运行在内核空间线程 ,但是永远也不会两者同时运行。
线程调度代码
yield
1 | // Give up the CPU for one scheduling round. |
线程切换的第一步(实际是内核线程的第一步),放弃CPU,调用sched切换到调度器程序。
sched
1 | // Switch to scheduler. |
这里其实有几个问题:为什么线程切换的时候禁止持有除了进程锁之外的其他锁?为什么要持有进程锁进行线程切换?
usually the thread that acquires a lock is also responsible for releasing the lock, which makes it easier to reason about correctness
一个进程持有锁同时也负有责任去释放锁
For context switching it is necessary to break this convention because p->lock protects invariants on the process’s state and context fields that are not true while executing in swtch.
但是context switch打破了这个常规。
One example of a problem that could arise if p->lock were not held during swtch: a different CPU might decide to run the process after yield had set its state to RUNNABLE, but before swtch caused it to stop using its own kernel stack. The result would be two CPUs running on the same stack, which would cause chaos.
因为yield将进程状态设置为runnable,如果提前释放锁,其他CPU就有可能运行这个进程,而此时进程还没完成内核栈的切换。两个CPU使用同一个内核栈会造成错误。
More reading
One way to think about the structure of the scheduling code is that it enforces a set of invariants about each process, and holds p->lock whenever those invariants are not true. One invariant is that if a process is RUNNING, a timer interrupt’s yield must be able to safely switch away from the process; this means that the CPU registers must hold the process’s register values (i.e. swtch hasn’t moved them to a context), and c->proc must refer to the process. Another invariant is that if a process is RUNNABLE, it must be safe for an idle CPU’s scheduler to run it; this means that p->context must hold the process’s registers (i.e., they are not actually in the real registers), that no CPU is executing on the process’s kernel stack, and that no CPU’s c->proc refers to the process. Observe that these properties are often not true while p->lock is held.
Maintaining the above invariants is the reason why xv6 often acquires p->lock in one thread and releases it in another, for example acquiring in yield and releasing in scheduler. Once yield has started to modify a running process’s state to make it RUNNABLE, the lock must remain held until the invariants are restored: the earliest correct release point is after scheduler (running on its own stack) clears c->proc. Similarly, once scheduler starts to convert a RUNNABLE pro- cess to RUNNING, the lock cannot be released until the kernel thread is completely running (after the swtch, for example in yield).
Swtch.S
1 | .globl swtch |
真正执行切换的其实是switch汇编代码,swtch函数会将当前的内核线程的寄存器保存到p->context中。swtch函数的另一个参数c->context,c表示当前CPU的结构体。CPU结构体中的context保存了当前CPU核的调度器线程的寄存器。所以swtch函数在保存完当前内核线程的内核寄存器之后,就会恢复当前CPU核的调度器线程的寄存器,并继续执行当前CPU核的调度器线程。
注意两个特殊的寄存器ra和sp。ra寄存器保存的是当前函数的返回地址,所以调度器线程中的代码会返回到ra寄存器中的地址,sp则切换了内核栈。
这里有个有趣的问题,或许你们已经注意到了。swtch函数的上半部分保存了ra,sp等等寄存器,但是并没有保存程序计数器pc(Program Counter),为什么会这样呢?
学生回答:因为程序计数器不管怎样都会随着函数调用更新。
是的,程序计数器并没有有效信息,我们现在知道我们在swtch函数中执行,所以保存程序计数器并没有意义。但是我们关心的是我们是从哪调用进到swtch函数的,因为当我们通过switch恢复执行当前线程并且从swtch函数返回时,我们希望能够从调用点继续执行。
另一个问题是,为什么RISC-V中有32个寄存器,但是swtch函数中只保存并恢复了14个寄存器?
学生回答:因为switch是按照一个普通函数来调用的,对于有些寄存器,swtch函数的调用者默认swtch函数会做修改,所以调用者已经在自己的栈上保存了这些寄存器,当函数返回时,这些寄存器会自动恢复。所以swtch函数里只需要保存Callee Saved Register就行。(注,详见5.4)
Caller saved寄存器,在函数调用中需要caller主动保存的寄存器。因此,callee可以直接自由更改这些寄存器,而不需要其他额外操作。
Callee saved寄存器则对称相反,caller可以直接修改这些寄存器而不用保存。
scheduler
1 | // Per-CPU process scheduler. |
可以看到调度器程序其实就是一个无限循环,不断从所有进程中挑选能够运行的程序,然后swtch到那个程序。同理,其他程序会swtch到scheduler调用swtch函数的那一行。每个CPU都有调度器,在xv6启动过程中kernel/main.c会调用scheduler。
然后我们还注意到 acquire(&p->lock);,因为要修改进程的状态,但是在swtch之前我们都没有释放锁,这是为什么?与前面同理。
The only place a kernel thread gives up its CPU is in sched, and it always switches to the same location in scheduler, which (almost) always switches to some kernel thread that previously called sched. Thus, if one were to print out the line numbers where xv6 switches threads, one would observe the following simple pattern: (kernel/proc.c:456), (kernel/proc.c:490), (kernel/proc.c:456), (kernel/proc.c:490), and so on.
线程调用swtch总是切换到另一个线程调用swtch的地方,那么第一个线程调用swtch它切换到哪里?
在第一个线程之前,没有其他线程之前调用过swtch。
学生提问:当调用swtch函数的时候,实际上是从一个线程对于switch的调用切换到了另一个线程对于switch的调用。所以线程第一次调用swtch函数时,需要伪造一个“另一个线程”对于switch的调用,是吧?因为也不能通过swtch函数随机跳到其他代码去。
Robert教授:是的。我们来看一下第一次调用switch时,“另一个”调用swtch函数的线程的context对象。proc.c文件中的allocproc函数会被启动时的第一个进程和fork调用,allocproc会设置好新进程的context,如下所示:
1 | // Set up new context to start executing at forkret, |
再看forkret
1 | // A fork child's very first scheduling by scheduler() |
从代码中看,它的工作其实就是释放调度器之前获取的锁。函数最后的usertrapret函数其实也是一个假的函数,它会使得程序表现的看起来像是从trap中返回,但是对应的trapframe其实也是假的,这样才能跳到用户的第一个指令中。
学生提问:与之前的context对象类似的是,对于trapframe也不用初始化任何寄存器,因为我们要去的是程序的最开始,所以不需要做任何假设,对吧?
Robert教授:我认为程序计数器还是要被初始化为0的。
线程切换持锁限制
xv6切换中,进程在调用switch函数的过程中,必须要持有p->lock(注,也就是进程对应的proc结构体中的锁),但是同时又不能持有任何其他的锁。
这是为什么?构建一个场景:
我们有进程P1,P1的内核线程持有了p->lock以外的其他锁,这些锁可能是在使用磁盘,UART,console过程中持有的。之后内核线程在持有锁的时候,通过调用switch/yield/sched函数出让CPU,这会导致进程P1持有了锁,但是进程P1又不在运行。
假设我们在一个只有一个CPU核的机器上,假设P2也想使用磁盘,UART或者console,它会对P1持有的锁调用acquire,这是对于同一个锁的第二个acquire调用。当然这个锁现在已经被P1持有了,所以这里的acquire并不能获取锁。但是很明显进程P2的acquire不会返回,所以即使进程P2稍后愿意出让CPU,P2也没机会这么做。这就造成了死锁。
Sleep & Wakeup
当你在写一个线程的代码时,有些场景需要等待一些特定的事件,或者不同的线程之间需要交互。比如
- 读pipe,等待pipe的非空事件
- 读磁盘,等待磁盘读完成
- wait函数,等待子进程推出
怎么能让进程或者线程等待一些特定的事件呢?一种非常直观的方法是通过循环实现busy-wait,但是浪费CPU。
1 | struct semaphore { |
我们希望能够在等待的时候让出CPU,然后在事件完成时重新获取CPU。Coordination就是出让CPU,直到等待的事件发生再恢复执行。人们发明了很多不同的Coordination的实现方式,但是与许多Unix风格操作系统一样,XV6使用的是Sleep&Wakeup这种方式。
这里的机制是,如果一个线程需要等待某些事件,比如说等待UART硬件愿意接收一个新的字符,线程调用sleep函数并等待一个特定的条件。当特定的条件满足时,代码会调用wakeup函数。这里的sleep函数和wakeup函数是成对出现的。还需要注意:sleep和wakeup函数需要通过某种方式链接到一起。也就是说,如果我们调用wakeup函数,我们只想唤醒正在等待刚刚发生的特定事件的线程。所以,sleep函数和wakeup函数都带有一个叫做sleep channel的参数,我们在调用wakeup的时候,需要传入与调用sleep函数相同的sleep channel。
以信号量为例谈实现
The basic idea is to have sleep mark the current process as SLEEPING and then call sched to release the CPU; wakeup looks for a process sleeping on the given wait channel and marks it as RUNNABLE.
sleep函数做的事情很简单,将进程标记为sleep,记录channel(p->ch)到进程然后调用sched让出CPU;wakeup查找在相应channel(p->ch)上睡眠的进程,然后将其标记为runnable。
1 | void V(struct semaphore* s){ |
但如果sleep和wakeup都只带一个channel参数会出现lost wakeup问题:P刚判断完count为0,V就调整count值加一并且执行了wakeup,此时P还未睡眠,这个wakeup就丢失了。也就是说,P的判断count和sleep之间不是原子的。
解决这个问题也很简单,将锁上移,保护count。
1 | void V(struct semaphore* s){ |
但这就带来了严重的问题:死锁。P带着锁睡眠,count将永远得不到更新,其他进程也得不到锁。
所以sleep的实现需要修改:增加一个额外参数,条件锁。在它将进程标记为sleep后要能够释放锁,然后在sleep返回时,还需要能获得锁。
正确实现
1 | // Atomically release lock and sleep on chan. |
注意点:
- sleep依靠线程切换sched来放弃CPU的控制权;
- sleep在内部使用了两把锁:一把进程锁,一把是参数的条件锁;
- 参数中的条件锁提示sleep要和锁一起使用;
- sleep和wakeup通过一个channel参数联系在一起;
- sleep在sched返回后,还需要自动获得条件锁。
It is sometimes the case that multiple processes are sleeping on the same channel; for example, more than one process reading from a pipe. A single call to wakeup will wake them all up. One of them will run first and acquire the lock that sleep was called with, and (in the case of pipes) read whatever data is waiting in the pipe. The other processes will find that, despite being woken up, there is no data to be read. From their point of view the wakeup was “spurious,” and they must sleep again.
For this reason sleep is always called inside a loop that checks the condition.
xv6中的sleep和wakeup机制其实就是条件变量。
使用例子:pipe
1 | int piperead(struct pipe *pi, uint64 addr, int n){ |
代码第7行,如果pipe为空,需要等待写事件。需要注意的是,直接用nread作为sleep和wakeup的联系,因为nread只会在pipread中得到更新。
1 | int pipewrite(struct pipe *pi, uint64 addr, int n){ |
进程相关
exit系统调用
每个进程最终都需要退出,我们需要清除进程的状态,释放栈。在XV6中,一个进程如果退出的话,我们需要释放用户内存,释放page table,释放trapframe对象,将进程在进程表单中标为REUSABLE,这些都是典型的清理步骤。
两大问题:
不能直接单方面的摧毁另一个线程(指kill),如果我们直接就把线程杀掉了,我们可能在线程完成更新复杂的内核数据过程中就把线程杀掉了。
即使一个线程调用了exit系统调用是自己决定要退出,但它仍然持有运行代码所需要的一些资源,例如它的栈,以及它在进程表单中的位置。当它还在执行代码,它就不能释放正在使用的资源。
1 | void exit(int status) { |
首先exit函数关闭了所有已打开的文件。接下来是类似的处理,进程有一个对于当前目录的记录,这个记录会随着你执行cd指令而改变。在exit过程中也需要将对这个目录的引用释放给文件系统。
如果一个进程要退出,但是它又有自己的子进程,接下来需要设置这些子进程的父进程为init进程(父进程中的wait系统调用会完成进程退出最后的几个步骤。所以如果父进程退出了,那么子进程就不再有父进程,当它们要退出时就没有对应的父进程的wait。所以在exit函数中,会为即将exit进程的子进程重新指定父进程为init进程,也就是PID为1的进程)。
之后,我们需要通过调用wakeup函数唤醒当前进程的父进程,当前进程的父进程或许正在等待当前进程退出。
接下来,进程的状态被设置为ZOMBIE。现在进程还没有完全释放它的资源,所以它还不能被重用。
现在我们还没有结束,因为我们还没有释放进程资源。我们在还没有完全释放所有资源的时候,通过调用sched函数进入到调度器线程。
到目前位置,进程的状态是ZOMBIE,并且进程不会再运行,因为调度器只会运行RUNNABLE进程。同时进程资源也并没有完全释放,如果释放了进程的状态应该是UNUSED。但是可以肯定的是进程不会再运行了,因为它的状态是ZOMBIE。所以调度器线程会决定运行其他的进程。
wait系统调用
1 | // Wait for a child process to exit and return its pid. |
它里面包含了一个大的循环。当一个进程调用了wait系统调用,它会扫描进程表单,找到父进程是自己且状态是ZOMBIE的进程。从上一节可以知道,这些进程已经在exit函数中几乎要执行完了。之后由父进程调用的freeproc函数,来完成释放进程资源的最后几个步骤。
1 | static void freeproc(struct proc *p){ |
如果由正在退出的进程自己在exit函数中执行这些步骤,将会非常奇怪。这里释放了trapframe,释放了page table。如果我们需要释放进程内核栈,那么也应该在这里释放。但是因为内核栈的guard page,我们没有必要再释放一次内核栈。不管怎样,当进程还在exit函数中运行时,任何这些资源在exit函数中释放都会很难受,所以这些资源都是由父进程释放的。
在Unix中,对于每一个退出的进程,都需要有一个对应的wait系统调用,这就是为什么当一个进程退出时,它的子进程需要变成init进程的子进程。init进程的工作就是在一个循环中不停调用wait。每个进程都需要对应一个wait,这样它的父进程才能调用freeproc函数,并清理进程的资源。当父进程完成了清理进程的所有资源,子进程的状态会被设置成UNUSED,之后,fork系统调用才能重用进程在进程表单的位置。
kill系统调用
1 | int kill(int pid) { |
最后我想看的是kill系统调用。Unix中的一个进程可以将另一个进程的ID传递给kill系统调用,并让另一个进程停止运行。
如果我们不够小心的话,kill一个还在内核执行代码的进程,会有一些我几分钟前介绍过的风险,比如我们想要杀掉的进程的内核线程还在更新一些数据,比如说更新文件系统,创建一个文件。如果这样的话,我们不能就这样杀掉进程。所以kill系统调用不能就直接停止目标进程的运行。实际上,在XV6和其他的Unix系统中,kill系统调用基本上不做任何事情。
它先扫描进程表单,找到目标进程。然后只是将进程的proc结构体中killed标志位设置为1。如果进程正在SLEEPING状态,将其设置为RUNNABLE。
而目标进程运行到内核代码中能安全停止运行的位置时,会检查自己的killed标志位,如果设置为1,目标进程会自愿的执行exit系统调用。
这里需要注意的是sleep的进程被唤醒的问题:
通常sleep的进程都会等待某个事件,sleep的代码会被包含在一个loop条件检查中。当sleep被再次唤醒时,loop的条件检查还需要检查进程是否killed。
1 | while(pi->nread == pi->nwrite && pi->writeopen){ //DOC: pipe-empty |
也就是说,现在进程被唤醒的原因多了一个:它可能是被杀死了,而不是等待的事件完成了。我们需要小心的检查进程唤醒后的状态。
学生提问:这节课可能没有怎么讲到,但是如果关闭一个操作系统会发生什么?
Robert教授:这个过程非常复杂,并且依赖于你运行的是什么系统。因为文件系统是持久化的,它能在多次重启之间保持数据,我们需要保持文件系统的良好状态,如果我们正在更新文件系统的过程中,例如创建文件,然后我们想关闭操作系统,断电之类的。我们需要一个策略来确保即使我们正在一个复杂的更新文件系统的过程中,我们并不会破坏磁盘上的文件系统数据。文件系统其实就是一个位于磁盘的数据结构。所以这里涉及到了很多的机制来确保如果你关闭操作系统或者因为断电之类,我们可以恢复磁盘上的文件系统。
其他的,你是否需要做一些特殊的操作来关闭系统,取决于你正在运行什么进程。如果你正在运行一些重要的服务器,例如数据库服务器,并且许多其他计算机依赖这个数据库并通过网络使用它。那谁知道呢?答案或许是你不能就这么直接关闭操作系统,因为你正在提供一个对于其他计算机来说非常关键的服务。
如果你的计算机并没有在做任何事情,那么你可以直接关闭它。或许对于你的问题来说,如果你想关闭一个计算机,确保文件系统是正确的,之后停止执行指令,之后就可以关闭计算机了。
总结
xv6的线程调度确实蛮曲折的,所谓线程调度就是一个线程让出CPU,然后决定另外一个线程运行的过程。
我们需要知道一个线程会在什么场景让出CPU,一个是定时器中断,线程的时间片到期;另一个场景是等待事件,比如等待管道、等待外设等。第二个场景是通过sleep和wakeup做到让出CPU和恢复运行。
调度器程序本身就是个无限循环,从进程表中挑出可运行的线程,然后再交出CPU到可运行线程。线程切换需要保存上下文到contex,contex包括ra和sp寄存器以及14个callee save寄存器,然后恢复新线程的上下文。第一个线程会返回到forkret的位置,假装调用swtch。
有了同步机制后,我们就能理解fork+wait的威力。进程退出由自己释放资源显得有点奇怪,因为代码运行还是需要依靠一些资源(比如栈、页表等)。这就给进程的ZOMBIE状态一个很好的解释:进程打算退出了,有一些资源还没释放,它等待父进程来释放这些资源。同样的,父进程需要主动调用wait来清理子进程的剩余资源。wait并不仅仅是等待子进程结束那么简单。
kill调用反而最无力,只能标记进程的killed字段,唤醒沉睡的进程。如此一来,进程在任何唤醒的地方都要增加进程是否被杀死的条件检验。
MIT6.S081 xv6book chapter7
https://xyz.desirer233.fun/2024/01/16/MIT6.S081/book/chapter7/