MIT6.S081 xv6book chapter8
这八章讲述了xv6的文件系统,这个文件系统的实现很简单,有许多可以优化的地方,但也有很多复杂的地方。从磁盘组织、缓存、日志、Inode、目录、文件名与文件描述符。其实可以简单分为三部分:
- 底层存储(磁盘组织、磁盘缓存、Inode、Directory)
- 持久层(日志事务)
- 用户层(文件名、文件描述符)
前言
文件系统的有趣性:
- 抽象:如何对硬件的抽象
- 崩溃恢复——文件系统的持久性
- 文件组织——如何在磁盘上排布文件系统
- 性能——读取磁盘通常比较慢,如何取得性能的提升
文件系统分层:

最底层是磁盘,也就是一些实际保存数据的存储设备,正是这些设备提供了持久化存储。
在这之上是buffer cache或者说block cache,这些cache可以避免频繁的读写磁盘。这里我们将磁盘中的数据保存在了内存中。
为了保证持久性,再往上通常会有一个logging层。
longging层之上有inode cache,这主要是为了同步(synchronization)。
再往上就是inode本身了。它实现了read/write。
再往上,就是文件名,和文件描述符操作。
文件究竟维护了怎样的数据结构呢?核心的数据结构就是inode和file descriptor。后者主要与用户进程进行交互。
最重要的就是Inode,它代表了一个文件。文件名只是一个link,Inode之间通过编号进行区分。
- inode必须有一个link count来跟踪指向这个inode的文件名的数量。一个文件(inode)只能在link count为0的时候被删除。
- 实际中还有一个openfd count,也就是当前打开了文件的文件描述符计数。一个文件只能在这两个计数器都为0的时候才能被删除。
- 文件描述符必然自己悄悄维护了对于文件的offset。
磁盘组织
屏蔽不同磁盘的区别,我们可以将磁盘看成block或setor的数组,每个block大小固定,这样我们就能通过块号读取一个块的内容。
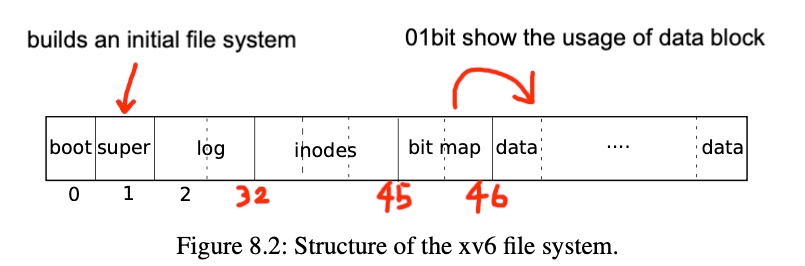
block0要么没有用,要么被用作boot sector来启动操作系统。
block1通常被称为super block,它描述了文件系统。它可能包含磁盘上有多少个block共同构成了文件系统这样的信息。
在XV6中,log从block2开始,到block32结束。实际上log的大小可能不同,这里在super block中会定义log就是30个block。
接下来在block32到block45之间,XV6存储了inode。我之前说过多个inode会打包存在一个block中,一个inode是64字节。
之后是bitmap block,这是我们构建文件系统的默认方法,它只占据一个block。它记录了数据block是否空闲。
之后就全是数据block了,数据block存储了文件的内容和目录的内容。
On-disk inode structure
Inode代表一个文件,那Inode究竟是怎么组织的呢?
Inode有两种形式,一种是在磁盘上,一种是在内存上。稍后将会解释为什么会有两种Inode模型,以及这两种Inode之间的同步。
1 | // On-disk inode structure |
- The
typefield distinguishes between files, directories, and special files (devices). A type of zero indicates that an on- disk inode is free. - The
nlinkfield counts the number of directory entries that refer to this inode, in order to recognize when the on-disk inode and its data blocks should be freed. - The
addrsarray records the block numbers of the disk blocks holding the file’s content.The last entry in theaddrsarray gives the address of the indirect block.
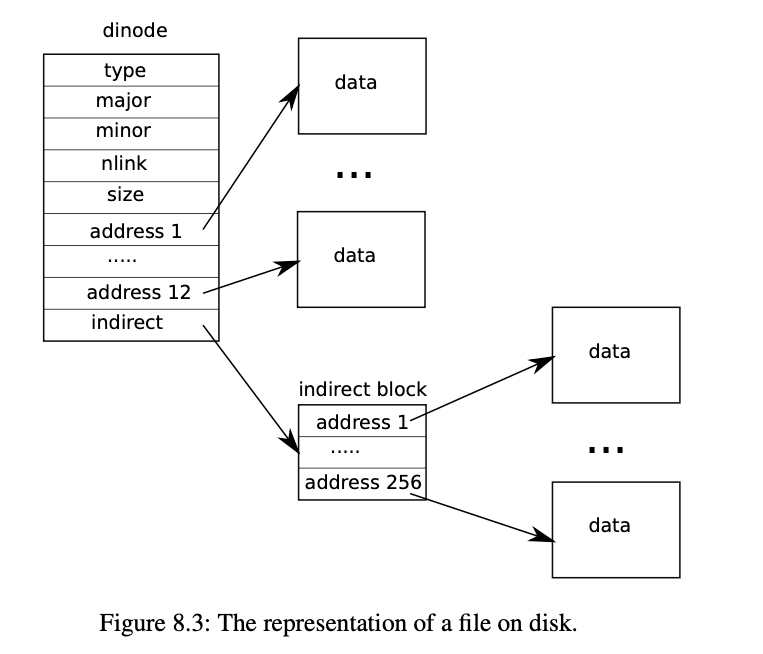
dinode 最令人不解的通常就是addrs数组了,它其实类似多级页表。首先,addrs数组存储了所有文件内容所在块的块号。它分为两级索引,第一级索引是直接映射,意思是我得到的块号就是文件内容真实的块号。第二级索引是addrs[12]的内容,它得到块号指向一个数据块,这个数据块才真正指向了文件内容块号。所以在xv6中,文件大小最多是 (12 + 256)* block size 这么大。
当dinode的type字段为T_DIR时,表明这个dinode是目录。目录的数据内容存的是目录条目,包含2字节的inode编号和14字节的文件名。
1 | struct dirent { |
看完On-disk inode structure我们就知道了,文件内容是放在data区,Inode用来索引这些文件,并区分文件类型。这是通常的设计,文件的元信息和文件内容分离存储。
in-memory copy of an inode
1 | // in-memory copy of an inode |
struct inode is the in-memory copy of a struct dinode on disk. The kernel stores an inode in memory only if there are C pointers referring to that inode
为什么会有in-memory copy of an inode 的存在?其实就是方便操作系统管理inode,提供更多关于inode的信息,比如引用计数等。
Buffer Cache
文件
创建文件的过程其实就是创建inode,然后写inode的内容,最后同步到磁盘。通过inode代表文件。
1 | // Allocate an inode on device dev. |
superblock记录了inode的数量,遍历所有创建好的inode,然后查看是否是空闲的inode(其type字段为0),然后使用它。
重点看这两行:
1 | bp = bread(dev, IBLOCK(inum, sb)); |
1 | // Inodes per block. |
通过bread函数,我们读取了特定设备dev上的第IBLOCK(inum, sb)个block的内容到buf上。通过宏定义我们能够知道IBLOCK(inum, sb)就是第inum 个 inode所在的块号,inum%IPB则是inode在块内的偏移量。
bread函数将读取磁盘的过程作了一层封装,我们再看bread函数:
1 | // Return a locked buf with the contents of the indicated block. |
可以看到bread其实是先调用bget
1 | // Look through buffer cache for block on device dev. |
bget读取的是bcache(缓存),如果缓存中没有,返回一个加锁的buf(containing a copy of a block which can be read or modified in memory),如果buf失效,最后才从磁盘读。
bcache
1 | struct buf { |
bcache就是个大小为30的LRU链表,链表的元素为buf。buf具有引用计数,表明有多少个线程正在使用它。blockno块号的内容就存在data里。
The buffer cache has two jobs: (1) synchronize access to disk blocks to ensure that only one copy of a block is in memory and that only one kernel thread at a time uses that copy; (2) cache popular blocks so that they don’t need to be re-read from the slow disk.
buffer cache作为缓存能有效的减少访问磁盘的时间,同时buffer cache必须保证一个磁盘block之对应一个buf,一个buf只能被一个线程使用,否则就会出问题。
如果buffer cache中有两份block 33的cache将会出现问题。假设一个进程要更新inode19,另一个进程要更新inode20。如果它们都在处理block 33的cache,并且cache有两份,那么第一个进程可能持有一份cache并先将inode19写回到磁盘中,而另一个进程持有另一份cache会将inode20写回到磁盘中,并将inode19的更新覆盖掉。所以一个block只能在buffer cache中出现一次。
从bget返回加锁的buf这点来看,xv6并不支持多个线程同时读写一块block。第二个获取相同block的线程需要等待第一个线程释放,acquiresleep确保线程能够睡眠。
Logging Layer
logging的目标:实现原子的系统调用,快速恢复和高性能。
持久化的基本思想
xv6 系统调用不直接写入磁盘上的文件系统数据结构。相反,它会在磁盘上的日志中放置它希望进行的所有磁盘写入的描述。一旦系统调用记录了其所有写入操作,它就会将一条特殊的提交记录写入磁盘,指示该日志包含完整的操作。此时,系统调用将写入复制到磁盘文件系统数据结构中。完成这些写入后,系统调用将擦除磁盘上的日志。
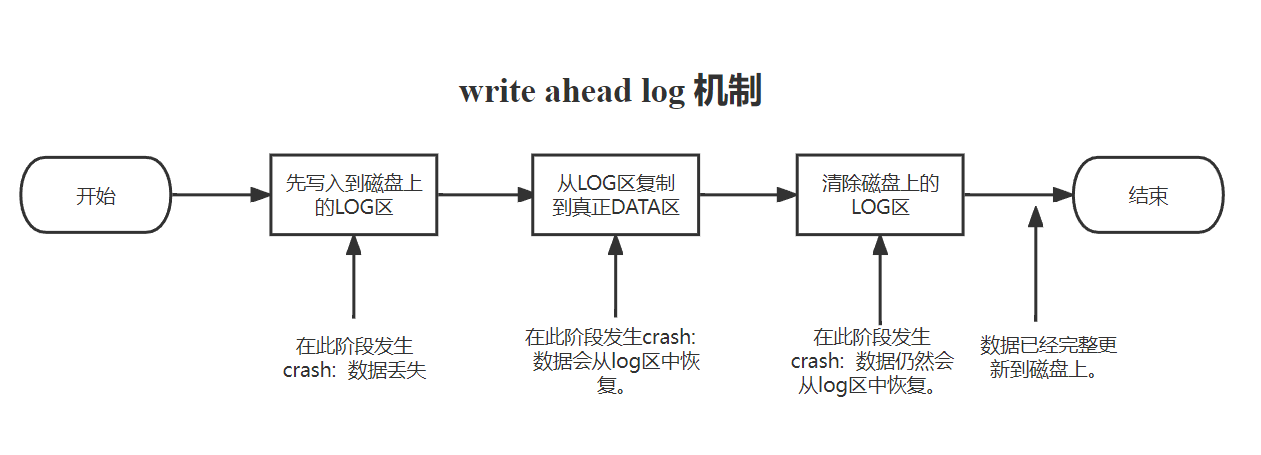 简单来说:就是系统调用先写log区,log区写完后写一条提交记录。提交记录写完,再将log区的block搬回到data区,搬运完之后擦除磁盘的日志。
简单来说:就是系统调用先写log区,log区写完后写一条提交记录。提交记录写完,再将log区的block搬回到data区,搬运完之后擦除磁盘的日志。
遵循write ahead rule,也就是说在写入commit记录之前,你需要确保所有的写操作都在log中。
日志设计
1 | // Contents of the header block, used for both the on-disk header block |
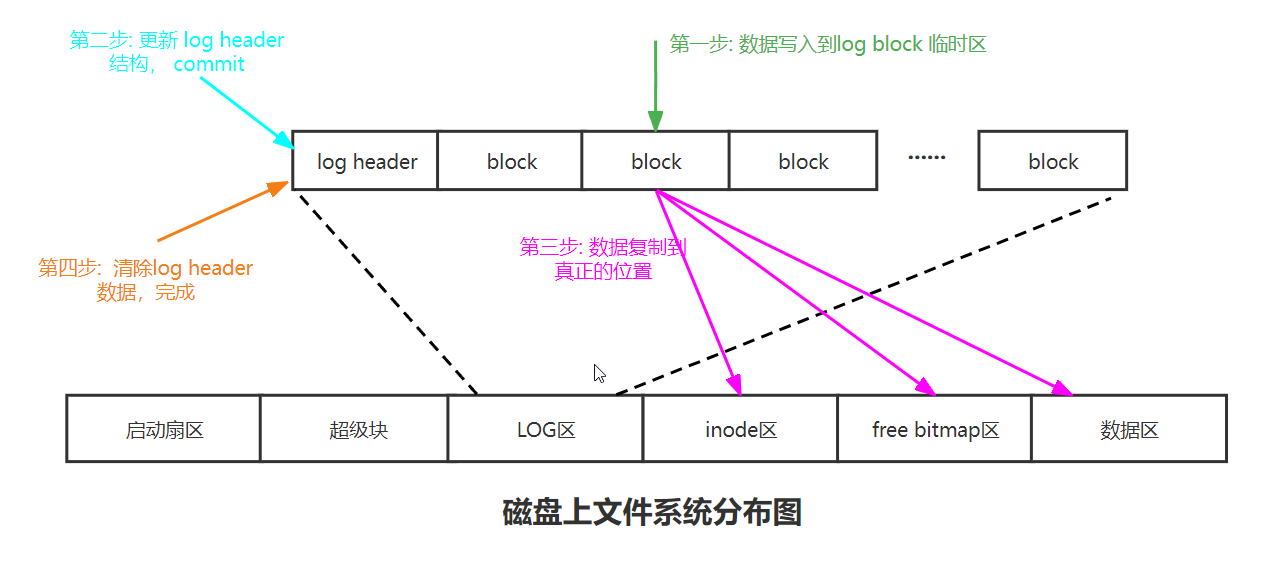
log主要由两部分组成,log header和log block。header里有一个数组追踪每个log block。
日志基本调用流程
1 | begin_op(); // 第一步 |
begin_op表示开启一次日志记录,这里暂时不揭示内容。
bread读缓存然后对data进行修改,此时需要调用log_write来记录修改到log。让我们来看看:
1 | // Caller has modified b->data and is done with the buffer. |
当在内存中修改了一个磁盘数据后,如果想从缓存真正写入的磁盘上, 有bwirte()函数。但是,xv6支持了log机制,使用log_write()代替了bwrite()函数来完成这个工作。 该函数其实只完成:在logheader中记录要写入的block块。(如果已经记录过,就无需再次添加,称之为log absorbtion)。这里注意,还调用bpin让这个buf的引用计数增一,避免这个脏块在回写前被bget给回收掉。
真正的写磁盘的动作在end_op()函数中来完成。
1 | void end_op(void) { |
代码最前端有一些复杂情况处理,直接跳过,看commit函数。
1 | static void commit(){ |
write_log将缓冲块写入到磁盘的日志区,完成脏块的持久化。
write_head则将logheader进行持久化。
install_trans负责使用日志覆盖掉对应的盘块。该方法读取logheader.blocks数组,将每个对应的日志区的盘块安装到文件区。
当成功用日志覆盖掉对应的盘块后,系统已经无需再继续持有这些日志,因此会再次调用write_head修改日志区的logheader来清除日志,并设定log[dev].lh.n = 0。
日志挑战
第一个挑战是bcache不能撤回已经在日志transaction中的buf,这么做会破坏原子性。所以有一个buf_pin操作会将buf固定在cache中(实际上就是增加一个引用计数)
第二个挑战是文件系统操作受限于log大小。这里意思是说xv6的log区大小为30,这就限制一次系统调用最多写的block数量。如果写入的block数超过了30,那么一个写操作会被分割成多个小一些的写操作。
1 | int max = ((MAXOPBLOCKS-1-1-2) / 2) * BSIZE; |
第三个挑战就是并发操作。
log的并发还挺有意思的,除了加锁保护外,还限制于log的空间大小。
比如,现在有两个并发的transaction,其中t0在log的前半部分,t1在log的后半部分,可是用完了log空间但一个transcation都没完成。这样就陷入了死锁,任何一个transaction 都期待另一个提交释放空间,但一个都不能提交。

所以说还要保证多个并发transaction也适配log的大小。当我们还没有完成一个文件系统操作时,我们必须在确保可能写入的总的log数小于log区域的大小的前提下,才允许另一个文件系统操作开始。
XV6通过限制并发文件系统操作的个数来实现这一点。在begin_op中,我们会检查当前有多少个文件系统操作正在进行。如果有太多正在进行的文件系统操作,我们会通过sleep停止当前文件系统操作的运行,并等待所有其他所有的文件系统操作都执行完并commit之后再唤醒。这里的其他所有文件系统操作都会一起commit。有的时候这被称为group commit,因为这里将多个操作像一个大的transaction一样提交了,这里的多个操作要么全部发生了,要么全部没有发生。
1 | // called at the start of each FS system call. |
首先,如果log正在commit过程中,那么就等到log提交完成,因为我们不能在install log的过程中写log;其次,如果当前操作是允许并发的操作个数的后一个,那么当前操作可能会超过log区域的大小,我们也需要sleep并等待所有之前的操作结束;最后,如果当前操作可以继续执行,需要将log的outstanding字段加1,最后再退出函数并执行文件系统操作。
1 | void end_op(void) { |
最后再看end_op的前半部分。在最开始首先会对log的outstanding字段减1,因为一个transaction正在结束;其次检查committing状态,当前不可能在committing状态,所以如果是的话会触发panic;如果当前操作是整个并发操作的最后一个的话(log.outstanding == 0),接下来立刻就会执行commit;如果当前操作不是整个并发操作的最后一个的话,我们需要唤醒在begin_op中sleep的操作,让它们检查是不是能运行。
所以,即使是XV6中这样一个简单的文件系统,也有一些复杂性和挑战。
崩溃恢复过程
崩溃恢复的过程也很简单,只需要读log里未提交的日志就行。那什么是真正的提交节点呢?在commit函数中已经指示了,write head就是那么一个节点。
1 | static void commit(){ |
write_head将n不为0的head写入log区。下次开机启动时,扫描log区的head,查看其n字段是否为0.
1 | static void recover_from_log(void){ |
Path name 命名空间
我们知道,inode代表文件,但是为了便于使用,我们还管理一个命令空间。命名空间是以”/“为起点的树,每个目录下有”.”代表自身,有”..”代表上一级目录。怎么实现呢?
一般来说,根目录是固定在磁盘上某个块上的,比如1号块。遍历路径逻辑就是从根目录开始读取目录条目,然后逐个查找。
1 | if(*path == '/') |
xv6没有对目录查找进行优化,只是简单的线性查找。
1 | static struct inode* namex(char *path, int nameiparent, char *name){ |
File descriptor layer
Unix 界面的一个很酷的方面是 Unix 中的大多数资源都表示为文件,包括控制台、管道等设备,当然还有真实文件。文件描述符层是实现这种通用性的层。
具体来说,就是用一个file结构体来包裹文件、管道、设备。
1 | struct file { //万物皆文件,就是这里了 |
进程有一个打开文件的数组,数组下标就是文件描述符。
1 | struct proc { |
当我们使用文件描述符进行读写时,实际上是通过文件描述符作为索引得到file结构体,再通过file结构体进行相应type的读写。
ftable
1 | // file.c |
xv6对于file结构体的使用,也采用了一个池化的思想。
1 | struct { |
1 | // Allocate a file structure. |
让我们看看打开文件的过程:open系统调用,如果传入的是 O_CREATE 标志,说明要新创建文件。
1 | uint64 sys_open(void){ |
再看看create函数,其实就是找到父级目录,然后分配inode结构体,增加目录项。
1 | //creates a new name for a new inode |
再回到sys_open,这里才是分配fd的地方:先分配file结构体,然后分配fd文件描述符。
1 | if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){ |
分配文件描述符的过程就是遍历文件的openfiletable,找到未使用的下标。这样我们就能理解一个进程打开的文件描述符是有限的这句话。
1 | // Allocate a file descriptor for the given file. |
总结
通过这一章的学习,xv6的架构基本已经完成。我们学习了文件块在磁盘上的组织,读取磁盘块时的LRU缓存,为文件系统操作系统持久化的日志块,为用户提供友好的命名空间以及文件描述符,这都是unix很精髓的一部分。
文件系统的学习,主要有以下几个思想吧:
- 文件系统的设计(磁盘块具体存储分布、Inode文件、file统一文件)
- 缓存池化思想(bcache、itable、ftable)
- 日志持久化思想(transaction)
当然,文件系统还需应对并发处理,这里讲得内容很少。其中一个点是磁盘读取时用了sleeplock而不是spinlock,这是因为磁盘读取通常是一个持续时间较长的操作。更多关于加锁控制,比如ilock加锁,namex不加锁等等有具体的原因,这点也需要继续深入。
同时xv6的很多实现都可以继续优化,比如目录项查找以及日志性能等。这些下一章会讲。
推荐阅读:https://www.cnblogs.com/KatyuMarisaBlog/p/14385792.html
MIT6.S081 xv6book chapter8
https://xyz.desirer233.fun/2024/01/18/MIT6.S081/book/chapter8/