从应用角度介绍Redis常见应用面试题。
缓存 缓存穿透 (1)概念
客户端请求的数据在缓存和数据库中都不存在。如果持续发起这个请求,那么缓存会失效,好像不存在。
(2)解决方法
缓存空对象是在数据库未命中时,缓存一个null并设置一个短有效时间。
布隆过滤器则是在缓存前的一道关卡,查询数据是否存在,具体实现未知。
缓存雪崩 (1)概念
缓存雪崩就是同一时间大量key失效或者直接Redis宕机。那么这时候针对不同的key的大量请求都会要求重建缓存,数据库压力大。
(2)解决方法
为不同的key设置不同的过期时间(随机TTL)
Redis集群
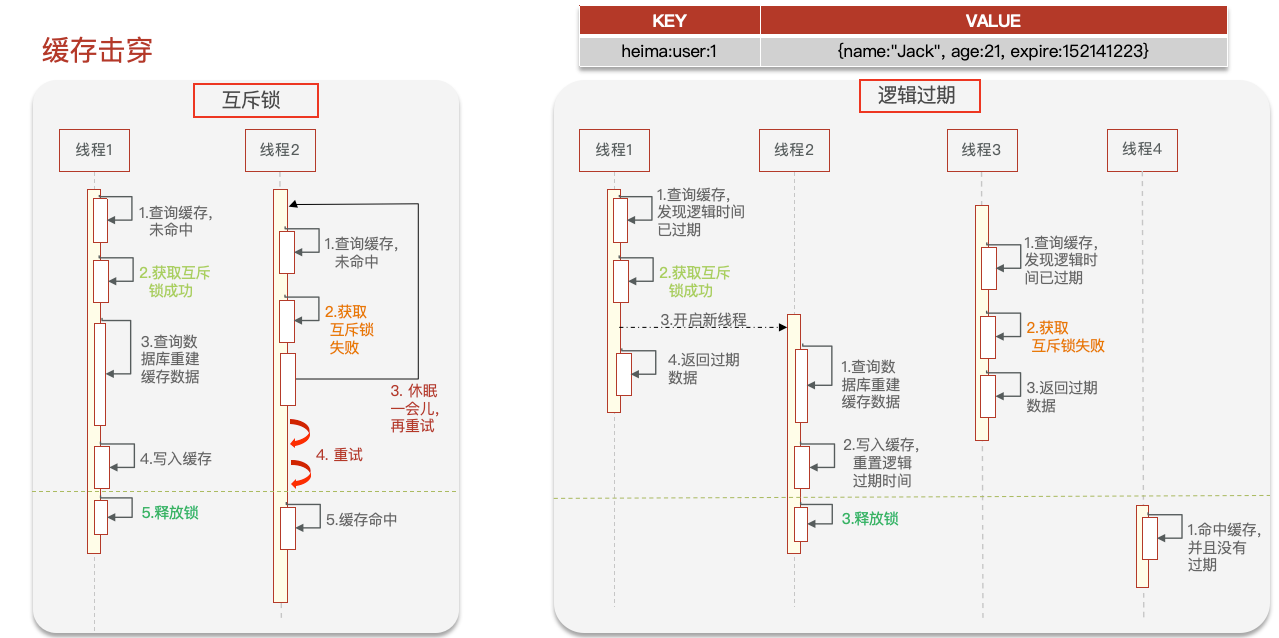
缓存击穿 (1)概念
缓存击穿也称之为热点key问题,一旦热点key失效,那么大量的请求都会打到数据库(在缓存重建时间内)。
(2)解决方法
互斥锁:为缓存重建的过程加锁,只有一个线程能拿到锁进行缓存重建,没拿到锁的线程休眠一段时间,再次查缓存,直到缓存重建完成 。
逻辑过期:不设置热点key的过期时间,由代码判断key的value中的expireTime字段是否过期。如果过期,由互斥锁保证开启一个新线程重建缓存,未获得锁的其他线程直接返回旧数据。
缓存与数据库的一致性 读操作:缓存命中直接返回;缓存未命中,则查询数据库,然后更新缓存并设置有效时间。
写操作:写数据库,然后选择主动更新缓存抑或删除缓存。
四种同步策略(数据库更新时主动更新缓存)
先更新缓存再更新数据库:第二步失败缓存库是脏数据
先更新数据库再更新缓存: 第二步失败缓存库是旧数据先删除缓存再更新数据库:第二步失败缓存库是空数据
先更新数据库、再删除缓存(推荐): 第二步失败缓存库是旧数据
更新缓存or删除缓存 更新缓存的优点是每次数据变化都能及时更新缓存,但缺点是操作消耗大,频繁更新缓存会影响服务器性能。
删除缓存优点是操作简单,惰性重建,将重建代价移动到下一次访问。
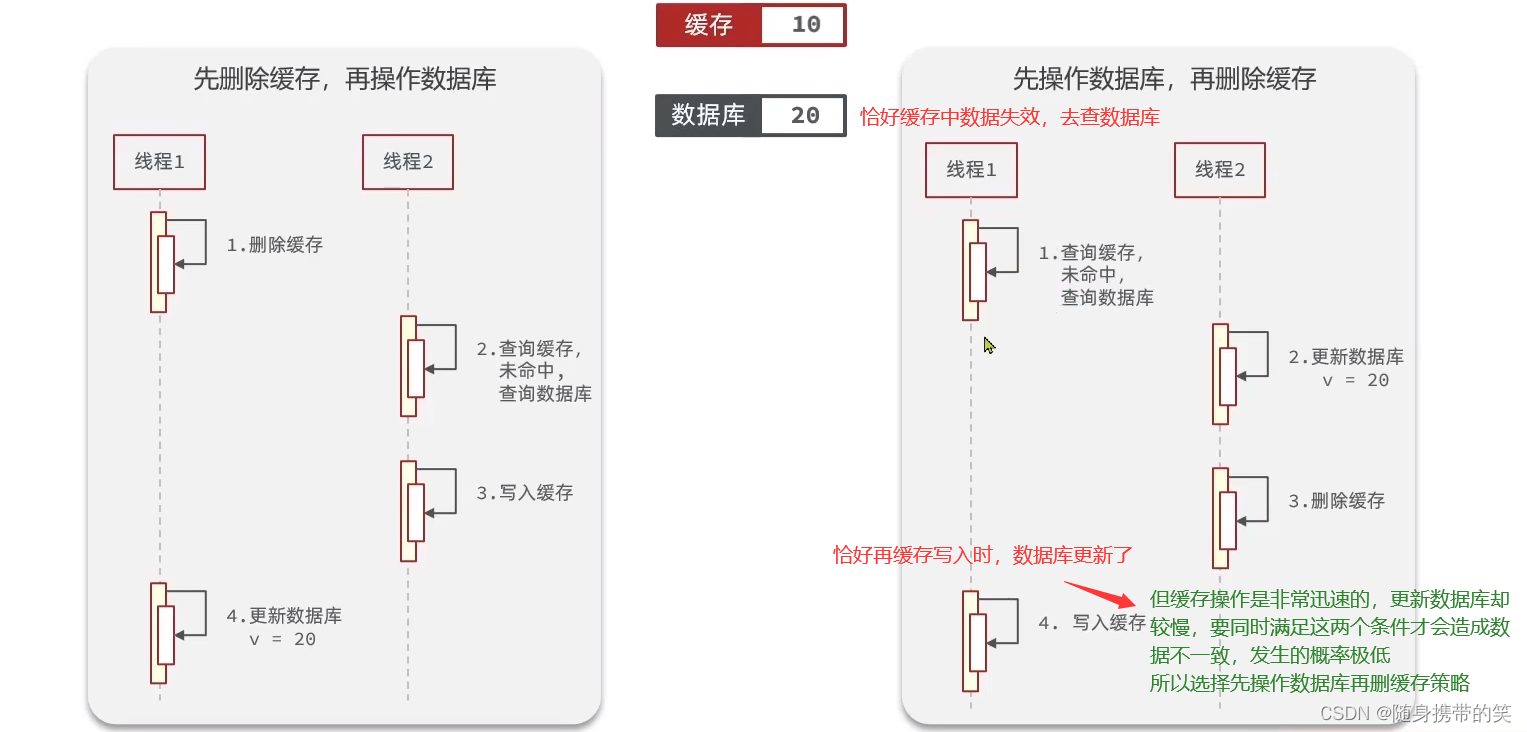
更新数据库与删除缓存的时序 先删缓存再更新数据库:线程1删除缓存后,线程2查询缓存不存在,然后重新写入缓存,此时缓存为旧数据。线程1再更新数据库为新数据。那么就出现了缓存旧数据、数据库新数据的不一致性。
先更新数据库在删除缓存:恰好缓存数据失效,线程1查缓存失效,查数据库旧数据;线程2更新数据库;线程1再更新缓存。这种不一致性出现概率低。
最优同步策略:先更新数据库、再删除缓存 所以我们得到结论:先更新数据库、再删除缓存是影响更小的方案。如果第二步出现失败的情况,则可以采用重试机制解决问题。
同步删除方案: 先更新数据库、再删除缓存。适用于不强制要求数据一致性的情景
流程:先更新数据库、再删除缓存。
问题:
并发时脏数据:在查询数据库到写缓存期间其他线程执行了一次更新删除,导致缓存的数据是旧数据
缓存删除失败:删除失败导致缓存库还是旧数据
同步删除+可靠消息方案 同步删除+可靠消息删除: 解决缓存删除失败问题,利用可靠消息多次重试删除缓存操作。
流程: 先更新数据库、再删除缓存,如果删除失败就发可靠MQ不断重试删除缓存,直到删除成功或重试5次。
问题: 消息队列中消息消费有时延,数据不一致时间较长(适用于不强制要求数据一致性的情景);MQ多次重试失败,导致长期脏数据
延迟双删:更高一致性 流程: 先删除缓存再更新数据库,然后在从数据库库更新后再删一次缓存。
为什么要延时呢?为了分布式系统下主从同步。
数据工作的大致流程:
主节点删除 redis 库数据;
主节点修改 mysql 库数据;
当前业务处理 等待一段时间,等 redis 和 mysql 主从节点数据同步;
从节点 redis 主库删除数据;
其它服务节点读取 redis 从库数据,发现没有数据,从 mysql 从库读取数据,并写入 redis 主库。
问题: 时间无法控制,不能保证在数据库从库更新后删除缓存。如果在从库更新前删除,用户再在更新前查从库又把脏数据写在缓存里了。
异步监听数据库+可靠消息删除 流程:
更新数据库后不做操作;
Canal等组件监听binlog发现有更新时就发可靠MQ删除缓存;
如果删除缓存失败,就基于手动ack、retry等机制,让消息在有限次数之内不断重试。
优点:
异步删除,性能更高;
可靠消息重试机制,多次删除保证删除成功。
问题: 要求canal等binlog抓取组件高可用,如果canal故障,会导致长期脏数据。
限流 常见限流算法:
计数器算法 比如说我要维持1秒内最多200个请求访问,那么我就设置一个计数器表示1秒内请求访问的数量,每隔一秒固定清空计数器。可以自定义窗口时间。
1 2 3 4 5 6 7 8 9 10 boolean fixedWindowsTryAcquire () { long currentTime = System.currentTimeMillis(); if (currentTime - lastRequestTime > windowUnit) { counter = 0 ; lastRequestTime = currentTime; } if (counter >= threshold) return flase; counter++; return true ; }
坏处:临界请求问题。比如0.9s有200个请求,1.1s有200个请求,那么实际在0.5到1.5s之间处理了400个请求。
滑动窗口算法 滑动窗口的思想是将一个窗口细分为若干个小窗口,每个小窗口独立负责一个时间段的请求限流,随着时间的前进,最旧的窗口丢弃,新的空窗口生成。
通过细化窗口的方式,能够将临界请求也一起细化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 private int SUB_CYCLE = 10 ; private int thresholdPerMin = 100 ; private final TreeMap<Long, Integer> counters = new TreeMap <>(); boolean slidingWindowsTryAcquire () { long currentWindowTime = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC) / SUB_CYCLE * SUB_CYCLE; int currentWindowNum = countCurrentWindow(currentWindowTime); if (currentWindowNum >= thresholdPerMin) return false ; counters.get(currentWindowTime)++; return true ; } private int countCurrentWindow (long currentWindowTime) { long startTime = currentWindowTime - SUB_CYCLE* (60 /SUB_CYCLE-1 ); int count = 0 ; Iterator<Map.Entry<Long, Integer>> iterator = counters.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry<Long, Integer> entry = iterator.next(); if (entry.getKey() < startTime) { iterator.remove(); } else { count =count + entry.getValue(); } } return count; }
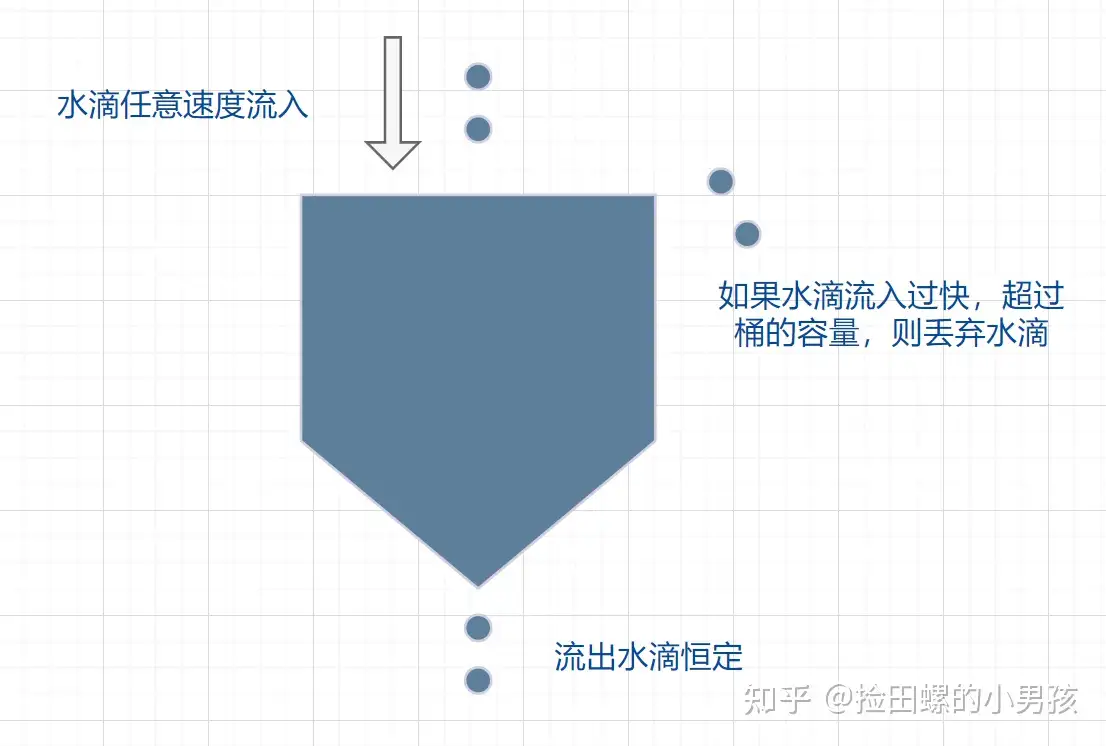
漏桶算法 漏桶算法采取一个容器存储到来的请求,以生产者消费者的思想处理请求。客户端是生产者,实际流量的产生者;服务端是消费者,负责消费容器中的请求。容器的大小是固定的,超出容器大小的请求将会被丢弃。
这样就能保证以不超过固定消费速率的方式处理请求。缺点是:消费速率固定,无法调整。如果大量请求到来,我们希望提高系统的处理效率。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private long rate; private long currentWater; private long refreshTime; private long capacity; boolean leakybucketLimitTryAcquire () { long currentTime = System.currentTimeMillis(); long outWater = (currentTime - refreshTime) / 1000 * rate; long currentWater = Math.max(0 , currentWater - outWater); refreshTime = currentTime; if (currentWater < capacity) { currentWater++; return true ; } return false ; }
令牌桶算法 令牌桶算法改良了漏桶算法,使得消费的速率能够调整。具体实现为:漏桶不再存储请求,而是存储令牌。每个请求要先获得令牌才能被处理。
此时桶的生产者和消费者倒置:由服务端以可调整的速率生成令牌,由客户端请求消费令牌。如果请求拿不到令牌,就直接放弃处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private long putTokenRate; private long refreshTime; private long capacity; private long currentToken = 0L ; boolean tokenBucketTryAcquire () { long currentTime = System.currentTimeMillis(); long generateToken = (currentTime - refreshTime) / 1000 * putTokenRate; currentToken = Math.min(capacity, generateToken + currentToken); refreshTime = currentTime; if (currentToken > 0 ) { currentToken--; return true ; } return false ; }
Redis实现限流 滑动窗口法 主要是利用Redis的ZSet数据结构来实现,每个请求的value都要保持互不相同,score为当前时间戳。利用ZSet的range,查询当前时间窗口内的请求数量,进而达到限流作用。
1 2 3 4 5 6 7 8 9 10 11 12 13 public Response limitFlow () { Long currentTime = new Date ().getTime(); System.out.println(currentTime); if (redisTemplate.hasKey("limit" )) { Integer count = redisTemplate.opsForZSet().rangeByScore("limit" , currentTime - intervalTime, currentTime).size(); System.out.println(count); if (count != null && count > 5 ) { return Response.ok("每分钟最多只能访问5次" ); } } redisTemplate.opsForZSet().add("limit" ,UUID.randomUUID().toString(),currentTime); return Response.ok("访问成功" ); }
通过上述代码可以做到滑动窗口的效果,并且能保证每N秒内至多M个请求,缺点就是zset的数据结构会越来越大。
令牌桶方法 Redis实现令牌桶,实际就是让Redis充当桶的角色。类似消息队列的意味,利用Redis的list实现令牌的队列。
1 2 3 4 5 6 7 8 9 10 11 12 13 public Response limitFlow2 (Long id) { Object result = redisTemplate.opsForList().leftPop("limit_list" ); if (result == null ){ return Response.ok("当前令牌桶中无令牌" ); } return Response.ok(articleDescription2); } @Scheduled(fixedDelay = 10_000,initialDelay = 0) public void setIntervalTimeTask () { redisTemplate.opsForList().rightPush("limit_list" ,UUID.randomUUID().toString()); }
依靠Java的定时任务,定时往List中rightPush令牌,当然令牌也需要唯一性。
全局ID生成 全局id生成器,是在分布式系统下用来生成全局唯一ID的工具,
设计思想:时间戳以秒为单位,留下1秒的时间让业务并发。这1秒的时间最多2的32次方个id。我不同的业务使用不同的key自增,业务再怎么大,一秒2的32次方个id也是够用的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Component public class RedisIdWorker { private static final long BEGIN_TIMESTAMP = 1674086400L ; private static final int COUNT_BITS = 32 ; private StringRedisTemplate stringRedisTemplate; public RedisIdWorker (StringRedisTemplate stringRedisTemplate) { this .stringRedisTemplate = stringRedisTemplate; } public long nextId (String keyPrefix) { LocalDateTime time = LocalDateTime.now(); long nowSecond = time.toEpochSecond(ZoneOffset.UTC); long timestamp = nowSecond - BEGIN_TIMESTAMP; String date = time.format(DateTimeFormatter.ofPattern("yyyy:MM:dd" )); long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date); return timestamp << COUNT_BITS | count; } public static void main (String[] args) { LocalDateTime time = LocalDateTime.of(2023 , 1 , 19 , 0 , 0 , 0 ); long second = time.toEpochSecond(ZoneOffset.UTC); System.out.println(second); } }
分布式锁 简单的分布式锁 利用setnx实现简单的分布式锁,锁名称由业务决定,并完成锁的初始化(初始化需要传入锁名称)tryLock返回加锁是否成功的判断。锁需要设置超时过期时间,避免业务阻塞造成锁无法释放。
获取锁
1 SET lock thread1 NX EX 10
释放锁
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public class SimpleRedisLock implements ILock { private StringRedisTemplate stringRedisTemplate; private String lock_name; public SimpleRedisLock (StringRedisTemplate stringRedisTemplate, String name) { this .stringRedisTemplate = stringRedisTemplate; lock_name = name; } @Override public boolean tryLock (long timeoutSec) { String key = "lock:" + lock_name; String value = Thread.currentThread().getId() + "" ; Boolean succ = stringRedisTemplate.opsForValue().setIfAbsent(key, value, timeoutSec, TimeUnit.SECONDS); return Boolean.TRUE.equals(succ); } @Override public void unlock () { String key = "lock:" + lock_name; stringRedisTemplate.delete(key); } }
加锁失败,由业务自己决定是否重试。
改进分布式锁 锁二次删除问题 考虑这么一个场景:线程获得锁后阻塞,超过过期时间,锁删除。第二个线程获得锁,但一个线程恢复后删除了第二个线程持有的锁。最后导致第三个线程又获得了锁。
改进方法:利用锁的value来判断当前持有锁的线程。每个机器上线程都要有一个全局ID。释放锁时需要判断锁是否是自己的。
加锁:指定锁的value 为线程的全局ID。
释放锁:释放锁一共有三个步骤,先获取锁的value,然后判断value是否为当前线程ID,如果是才能删除锁。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class SimpleRedisLock implements ILock { private StringRedisTemplate stringRedisTemplate; private String lock_name; public SimpleRedisLock (StringRedisTemplate stringRedisTemplate, String name) { this .stringRedisTemplate = stringRedisTemplate; lock_name = name; } private final String KEY_PREFIX = "lock:" ; private final String VALUE_PREFIX = UUID.randomUUID().toString(true )+"-" ; @Override public boolean tryLock (long timeoutSec) { String key = KEY_PREFIX + lock_name; String value = VALUE_PREFIX + Thread.currentThread().getId(); Boolean succ = stringRedisTemplate.opsForValue().setIfAbsent(key, value, timeoutSec, TimeUnit.SECONDS); return Boolean.TRUE.equals(succ); } @Override public void unlock () { String key = KEY_PREFIX + lock_name; String value = VALUE_PREFIX + Thread.currentThread().getId(); String lock_value = stringRedisTemplate.opsForValue().get(key); if (StrUtil.equals(value, lock_value)) stringRedisTemplate.delete(key); } }
释放锁原子性问题 释放锁的过程可能被阻塞(JVM的垃圾回收机制导致的短暂阻塞),因此要采用LUA脚本保证原子性。
(1)编写lua脚本
1 2 3 4 5 6 7 8 9 10 local key = KEYS[1 ]local value = ARGV[1 ]local lock_value = redis.call('GET' , key)if lock_value == value then return redis.call('DEL' , key) end return 0
(2)加载lua脚本并执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class SimpleRedisLock implements ILock { private StringRedisTemplate stringRedisTemplate; private String lock_name; public SimpleRedisLock (StringRedisTemplate stringRedisTemplate, String name) { this .stringRedisTemplate = stringRedisTemplate; lock_name = name; } private static final DefaultRedisScript<Long> LOCK_SCRIPT; static { LOCK_SCRIPT = new DefaultRedisScript <>(); LOCK_SCRIPT.setLocation(new ClassPathResource ("lock.lua" )); LOCK_SCRIPT.setResultType(Long.class); } private final String KEY_PREFIX = "lock:" ; private final String VALUE_PREFIX = UUID.randomUUID().toString(true )+"-" ; @Override public boolean tryLock (long timeoutSec) { String key = KEY_PREFIX + lock_name; String value = VALUE_PREFIX + Thread.currentThread().getId(); Boolean succ = stringRedisTemplate.opsForValue().setIfAbsent(key, value, timeoutSec, TimeUnit.SECONDS); return Boolean.TRUE.equals(succ); } @Override public void unlock () { String key = KEY_PREFIX + lock_name; String value = VALUE_PREFIX + Thread.currentThread().getId(); stringRedisTemplate.execute(LOCK_SCRIPT, Collections.singletonList(key), value); } }
至此,一个简单的不可重入的无重试机制的分布式锁就完成了。
后续改进:
可重入性(需要记录线程获锁的次数,当次数为0时释放锁)
重试机制
续约机制
主从一致性问题
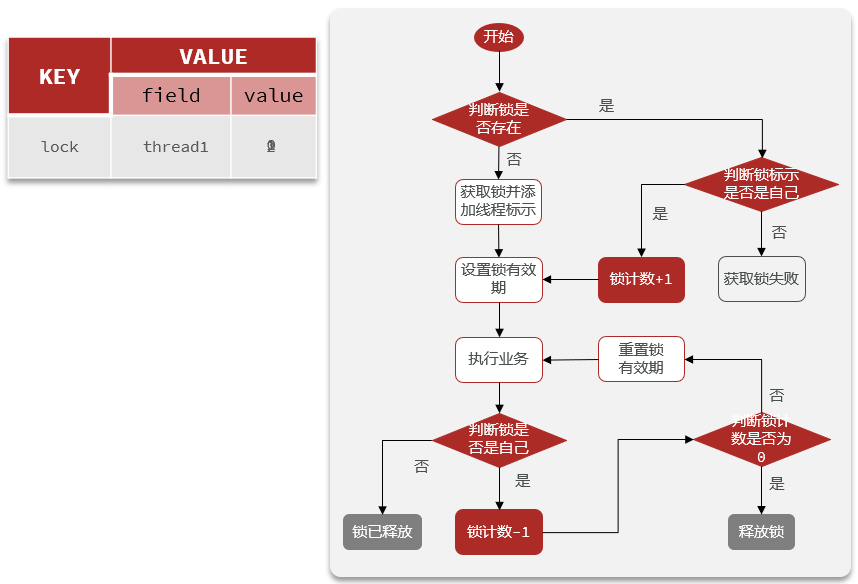
可重入分布式锁实现 可重入锁需要维护引用计数,简单的string类型无法满足需求,需要换用hash类型。
加锁:两次判断,第一次判断锁是否存在;如果不存在创建锁;如果存在,增加引用计数。
释放锁:两次判断,引用计数减1;如果引用计数为0,删除锁。
由于加锁和释放锁都是多步操作,因此均采用LUA脚本。
(1)获取锁的lua脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 local key = KEYS[1 ]local threadId = ARGV[1 ]local releaseTime = ARGV[2 ]if (redis.call('exists' , key) == 0 ) then redis.call('hset' , key, threadId, '1' ) redis.call('expire' , key, releaseTime) return 1 end if (redis.call('hexists' , key, threadId) == 1 ) then redis.call('hincrby' , key, threadId, '1' ) redis.call('expire' , key, releaseTime) return 1 end return 0
(2)释放锁的lua脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 local key = KEYS[1 ]local threadId = ARGV[1 ]local releaseTime = ARGV[2 ]if (redis.call('hexists' , key, threadId) == 0 ) then return nil end local count = redis.call('HINCRBY' , key, threadId, -1 );if (count > 0 ) then redis.call('EXPIRE' , key, releaseTime); return nil ; else redis.call('DEL' , key); return nil ; end
(3)可重入锁类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 package com.hmdp.utils;import cn.hutool.core.lang.UUID;import cn.hutool.core.util.StrUtil;import org.springframework.core.io.ClassPathResource;import org.springframework.data.redis.core.StringRedisTemplate;import org.springframework.data.redis.core.script.DefaultRedisScript;import java.util.Collections;import java.util.concurrent.TimeUnit;public class SimpleRedisLock implements ILock { private StringRedisTemplate stringRedisTemplate; private String lock_name; private long timeOutSec; public SimpleRedisLock (StringRedisTemplate stringRedisTemplate, String name) { this .stringRedisTemplate = stringRedisTemplate; lock_name = name; } private static final DefaultRedisScript<Long> LOCK_SCRIPT; private static final DefaultRedisScript<Long> UNLOCK_SCRIPT; static { LOCK_SCRIPT = new DefaultRedisScript <>(); LOCK_SCRIPT.setLocation(new ClassPathResource ("get_lock.lua" )); LOCK_SCRIPT.setResultType(Long.class); UNLOCK_SCRIPT = new DefaultRedisScript <>(); UNLOCK_SCRIPT.setLocation(new ClassPathResource ("release_lock.lua" )); UNLOCK_SCRIPT.setResultType(Long.class); } private final String KEY_PREFIX = "lock:" ; private final String VALUE_PREFIX = UUID.randomUUID().toString(true )+"-" ; @Override public boolean tryLock (long timeoutSec) { this .timeOutSec = timeoutSec; String key = KEY_PREFIX + lock_name; String value = VALUE_PREFIX + Thread.currentThread().getId(); Long result = stringRedisTemplate.execute(LOCK_SCRIPT, Collections.singletonList(key), value, Long.toString(timeoutSec)); return result!=null && result.equals(1L ); } @Override public void unlock () { String key = KEY_PREFIX + lock_name; String value = VALUE_PREFIX + Thread.currentThread().getId(); stringRedisTemplate.execute(UNLOCK_SCRIPT, Collections.singletonList(key), value, Long.toString(this .timeOutSec)); } }
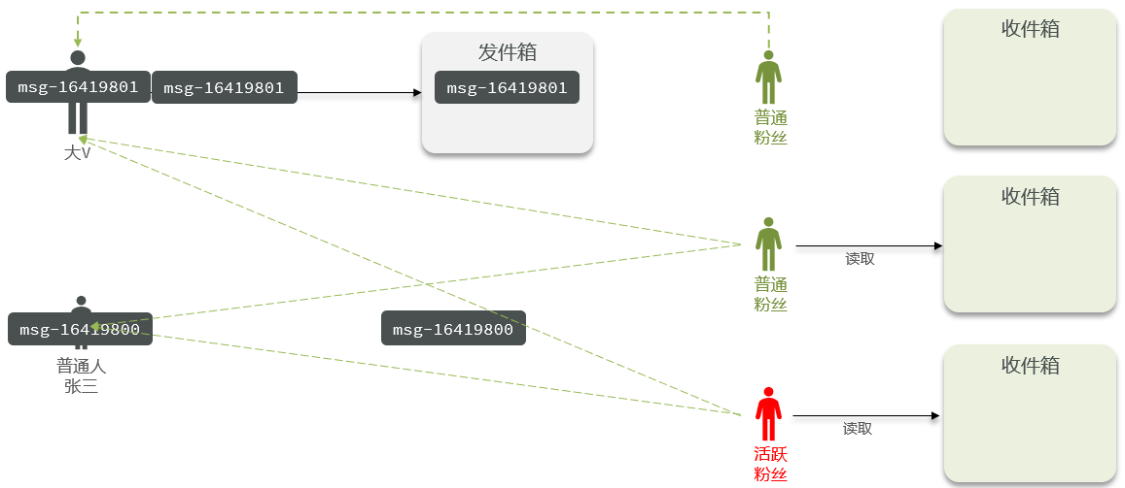
滚动推送 TimeLine推送模型 最典型的就是朋友圈,按照内容产生的时间顺序推送给关注用户。
实现模式:推模式、拉模式、推拉结合
推模式就是当前用户发布一条内容后,马上将这条内容推送到每个粉丝的收件箱。适合粉丝数少的一般人。
拉模式则相反,用户发布的内容先暂存到发件箱,当粉丝用户查看内容时,再从发件箱拉取内容到收件箱消费。适合粉丝众多的大V。
推拉模式结合适合用于大V的活跃粉丝和不活跃粉丝。活跃粉丝用推模式,不活跃粉丝用拉模式。
Redis实现推模式 推模式包括推送加收取。推送:将内容id推送的粉丝的收件箱;拉取:从个人收件箱拉取推文id。
可以利用set维护用户关注表,查找出所有粉丝ID。收件箱利用ZSet,每个推文加上时间戳。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public Result saveBlog (Blog blog) { UserDTO user = UserHolder.getUser(); blog.setUserId(user.getId()); save(blog); List<Follow> follows = followService.query().eq("follow_user_id" , user.getId()).list(); follows.forEach( follow -> { stringRedisTemplate.opsForZSet().add(FEED_KEY+follow.getUserId(), blog.getId().toString(), System.currentTimeMillis()); } ); return Result.ok(blog.getId()); }
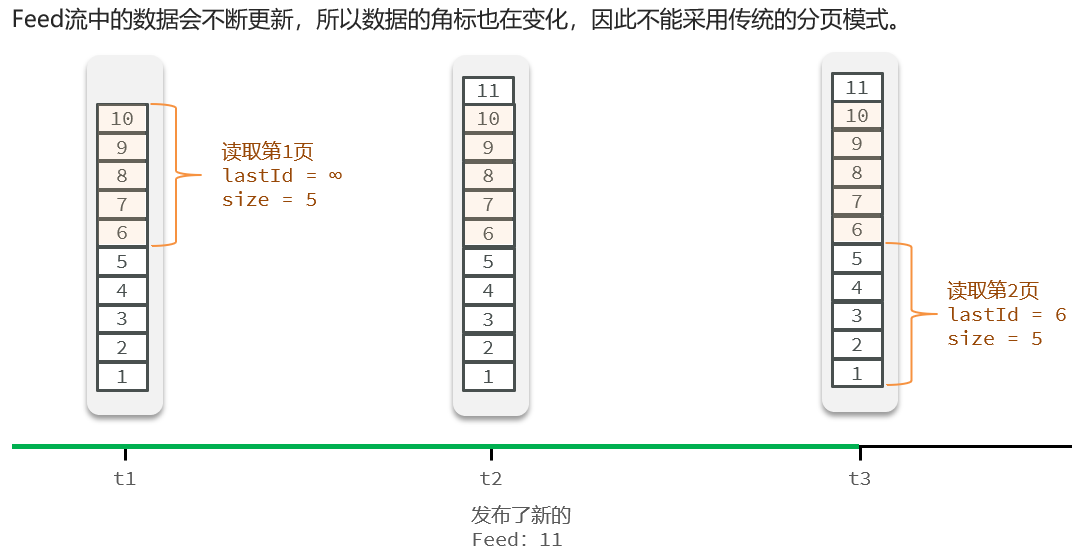
滚动分页查询:回想起朋友圈,可以一直往下滚动,浏览旧时间的朋友圈内容。如果想消费最新内容,往上滑刷新,就得到了最新内容。
实现:对推文进行时间戳进行降序排序,记录每次读的最后一条推文的时间戳位置。下次读从上次记录到的位置开始。如果是刷新的情况,则从头开始读(新的推文一定在头部,因为时间戳较大)。
这在Redis的ZSet对应的命令如下:
1 ZREVRANGEBYSCORE key Max Min LIMIT offset count
ZSet+Reverse+RangeByScore,按照分数降序排序。Max则是要读取的最大分数,Min是要读取的最低分数。offset就是偏移量,count就是读取的数据条数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 @Override public Result queryBlogOfFollow (Long lastId, Integer offset) { Long userId = UserHolder.getUser().getId(); Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet() .reverseRangeByScoreWithScores(FEED_KEY + userId, 0 , lastId, offset, 2 ); if (typedTuples==null ||typedTuples.isEmpty()){ return Result.ok(); } List<Long> ids = new ArrayList <>(typedTuples.size()); long minTime = 0 ; int ofset = 1 ; for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) { String idStr = typedTuple.getValue(); ids.add(Long.valueOf(idStr)); long time = typedTuple.getScore().longValue(); if (time == minTime){ ofset+=1 ; }else { minTime = time; ofset=1 ; } } String idStrs = StrUtil.join("," , ids); List<Blog> blogs = query().in("id" , ids).last("ORDER BY FIELD(id," + idStrs + ")" ) .list(); blogs.forEach(blog->{ queryUserByBlog(blog); isBlogLiked(blog); }); ScrollResult scrollResult = new ScrollResult (); scrollResult.setList(blogs); scrollResult.setOffset(ofset); scrollResult.setMinTime(minTime); return Result.ok(scrollResult); }
其中第一次查询时,lastId传当前时间戳;此后第二次查询,lastId为上次查询的最小时间戳,
偏移量是为了记住同一时间发布的推文数量,假如上次查询的最小时间戳一共有5条推文,那么下次查询必须从第6次推文读起。