MIT6824笔记八 Aurora
本节介绍了一个事务的基本实现方式以及Aurora。
对于Aurora,值得注意的是6个副本3个中心的设计,以及Quorum的读写思想。还有就是违背抽象,设计耦合的日志专用存储能极大提升性能。
论文指路:https://pdos.csail.mit.edu/6.824/papers/aurora.pdf
故障可恢复事务
认识事务
Atomic事务是指将多个操作打包成原子操作,并确保多个操作顺序执行。
Isolation我们希望数据库顺序执行事务里的操作,并且不允许其他任何人看到执行的中间状态。
Consistency同时,考虑到故障,如果在执行的任何时候出现故障,我们需要确保故障恢复之后,要么所有操作都已经执行完成,要么一个操作也没有执行。
Duration如果一个事务提交了,用户期望事务的效果是可以持久保存的,即使数据库故障重启了,数据也还能保存。
事务实现
通常来说,事务是通过对涉及到的每一份数据加锁来实现。
在硬盘中,除了有数据之外,还有一个预写式日志(Write-Ahead Log,简称为WAL)。预写式日志对于系统的容错性至关重要。
当你在执行一个事务内的各个操作时,例如执行 X=X+10 的操作时,数据库会从硬盘中读取持有X的记录,给数据加10。但是在事务提交之前,数据的修改还只在本地的缓存中,并没有写入到硬盘。
在允许数据库软件修改硬盘中真实的data page之前,数据库软件需要先在WAL中添加Log条目来描述事务。在提交事务之前,数据库需要先在WAL中写入完整的Log条目,来描述所有有关数据库的修改,并且这些Log是写入磁盘的。
在提交并写入硬盘的data page之前,数据库通常需要写入至少3条Log记录:
- 第一条表明,作为事务的一部分,我要修改X,它的旧数据是500,我要将它改成510。
- 第二条表明,我要修改Y,它的旧数据是750,我要将它改成740。
- 第三条记录是一个Commit日志,表明事务的结束。
通常来说,前两条Log记录会打上事务的ID作为标签,这样在故障恢复的时候,可以根据第三条commit日志找到对应的Log记录,进而知道哪些操作是已提交事务的,哪些是未完成事务的。
如果数据库成功的将事务对应的操作和commit日志写入到磁盘中,数据库可以回复给客户端说,事务已经提交了。而这时,客户端也可以确认事务是永久可见的。
接下来有两种情况:
如果数据库没有崩溃,那么在它的cache中,X,Y对应的数值分别是510和740。最终数据库会将cache中的数值写入到磁盘对应的位置。所以数据库写磁盘是一个lazy操作,它会对更新进行累积,每一次写磁盘可能包含了很多个更新操作。这种累积更新可以提升操作的速度。
如果数据库在将cache中的数值写入到磁盘之前就崩溃了,这样磁盘中的page仍然是旧的数值。当数据库重启时,恢复软件会扫描WAL日志,发现对应事务的Log,并发现事务的commit记录,那么恢复软件会将新的数值写入到磁盘中。这被称为redo,它会重新执行事务中的写操作。
Aurora
Amazon Aurora 是专为云构建的一种兼容 MySQL 和 PostgreSQL 的关系数据库,Amazon Aurora 的速度可达标准 MySQL 数据库的五倍、标准 PostgreSQL 数据库的三倍。
参考:https://zhuanlan.zhihu.com/p/338582762
背景
Amazon有装满了服务器的数据中心,并且会在每一个服务器上都运行VMM(Virtual Machine Monitor)。
(1)EBS(Elastic Block Store,弹性块存储)
Web服务所在的EC2(Elastic Cloud 2)实例会与数据库所在的EC2实例交互,完成数据库中记录的读写。但是如果数据库所在的服务器宕机了,并且数据存储在服务器的本地硬盘中,那么就会有大问题,因为数据丢失了。所以,为了向用户提供EC2实例所需的硬盘,并且硬盘数据不会随着服务器故障而丢失,就出现了一个与Aurora相关的服务,并且同时也是容错的且支持持久化存储的服务,这个服务就是EBS。
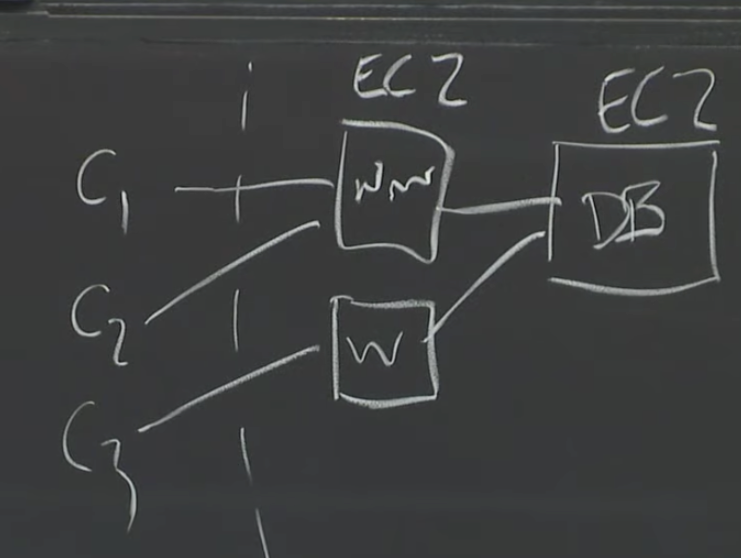
在实现上,EBS底层是一对互为副本的存储服务器。一个EBS volume看起来就像是一个普通的硬盘一样,但却是由一对互为副本EBS服务器实现,每个EBS服务器本地有一个硬盘。
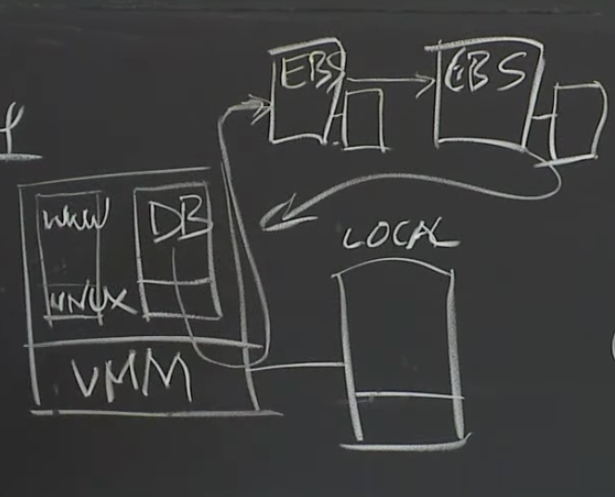
所以,现在你运行了一个数据库,相应的EC2实例将一个EBS volume挂载成自己的硬盘。当数据库执行写磁盘操作时,数据会通过网络送到EBS服务器。这两个EBS服务器会使用Chain Replication进行复制。
问题一:网络传输大。如果你在EBS上运行一个数据库,那么最终会有大量的数据通过网络来传递。
问题二:EBS的容错性不是很好。为了降低使用Chain Replication的代价,Amazon总是将EBS volume的两个副本存放在同一个数据中心,如果整个数据中心挂了,那就没辙了。
(2)Amazon RDS(Relational Database Service,关系型数据服务)
在MySQL基础上,结合Amazon自己的基础设施,Amazon为其云用户开发了改进版的数据库,叫做RDS。RDS是第一次尝试将数据库在多个AZ之间做复制,这样就算整个数据中心挂了,你还是可以从另一个AZ重新获得数据而不丢失任何写操作。
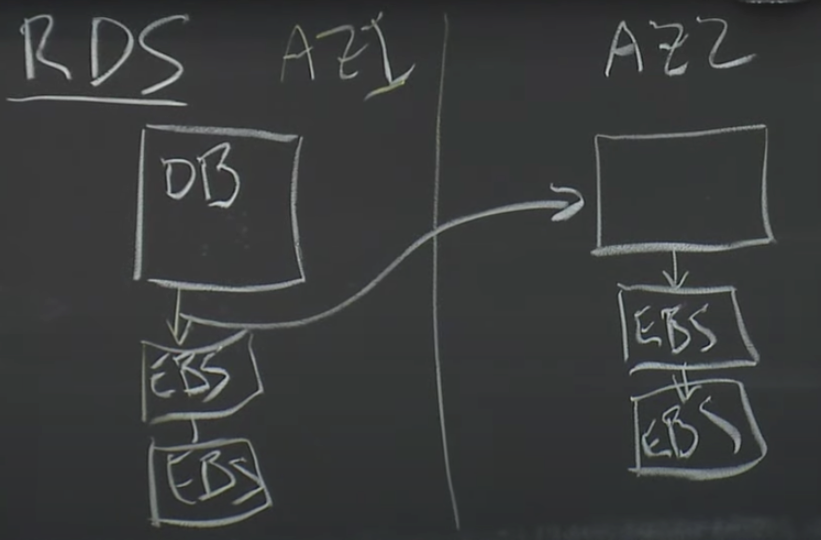
通过EBS存储DB的data page&log。再通过网络传输data个另一个DB。
这个数据库将它的data page和WAL Log存储在EBS,而不是对应服务器的本地硬盘。当数据库执行了写Log或者写page操作时,这些写请求实际上通过网络发送到了EBS服务器,所有这些服务器都在一个AZ中。
每一次数据库软件执行一个写操作,Amazon会自动的将写操作拷贝发送到另一个数据中心的AZ中。
每一次写操作,例如数据库追加日志或者写磁盘的page,数据除了发送给AZ1的两个EBS副本之外,还需要通过网络发送到位于AZ2的副数据库。副数据库接下来会将数据再发送给AZ2的两个独立的EBS副本。之后,AZ2的副数据库会将写入成功的回复返回给AZ1的主数据库,主数据库看到这个回复之后,才会认为写操作完成了。
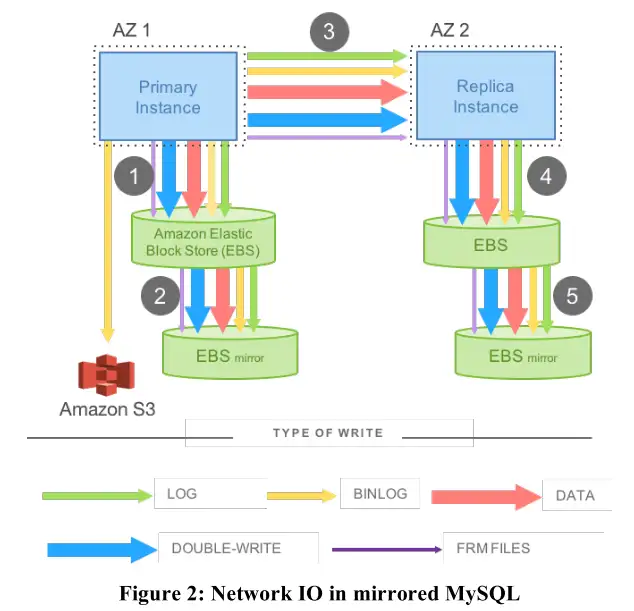
RDS的写操作代价极高,因为需要写大量的数据。这意味着,哪怕是只写入这两个数字,当需要更新data page时,需要向磁盘写入多得多的数据。通过网络来传输8k字节的page数据时,RDS的架构很明显太慢了。
学生提问:为什么会慢呢?
Robert教授:在这个架构中,对于数据库来说是无感知的,每一次数据库调用写操作,更新自己对应的EBS服务器,每一个写操作的拷贝穿过AZ也会写入到另一个AZ中的2个EBS服务器中,另一个AZ会返回确认说写入成功,只有这时,写操作看起来才是完成的。所以这里必须要等待4个服务器更新完成,并且等待数据在链路上传输。
性能低:这种Mirrored MySQL比Aurora慢得多的原因是,它通过网络传输了大量的数据。并且具有大量串行操作。
Aurora架构

整体上来看,我们还是有一个数据库服务器,但是这里运行的是Amazon提供的定制软件。
第一个是,在替代EBS的位置,有6个数据的副本,位于3个AZ,每个AZ有2个副本。所以现在有了超级容错性,并且每个写请求都需要以Quorum方式发送给这6个副本。
第二个是,这里通过网络传递的数据只有Log条目。后果是,这里的存储系统不再是通用存储,而是专门理解MySQL Log条目的存储系统。
Quorum复制思想
Aurora使用的是一种经典quorum(法定人数机制)思想的变种。通常来说,Quorum系统就是简单的读写系统,支持Put/Get操作。
有N个副本;
写请求,至少确保写操作被W个副本确认,W小于N。
读请求,至少需要从R个副本得到所读取的信息。
Quorum系统要求,发送写请求的W个服务器,必须与任意接收读请求的R个服务器有重叠。这意味着,R加上W必须大于N( 至少满足R + W = N + 1 ),这样任意W个服务器至少与任意R个服务器有一个重合。
读请求
这里还有一个关键的点,客户端读请求可能会得到R个不同的结果,现在的问题是R个结果中,哪一个是正确的呢?不能使用投票法决定,因为返回的R个结果可能只有一个结果是正确的。
在Quorum系统中使用的是版本号(Version)。每一次执行写请求,你需要将新的数值与一个增加的版本号绑定。之后,客户端发送读请求,从Read Quorum得到了一些回复,客户端可以直接使用其中的最高版本号的数值。
优点
(1)相比Chain Replication,这里的优势是可以轻易的剔除暂时故障、失联或者慢的服务器。发N个只需要等最快的R或W个回复。
实际上,这里是这样工作的,当你执行写请求时,你会将新的数值和对应的版本号给所有N个服务器,但是只会等待W个服务器确认。类似的,对于读请求,你可以将读请求发送给所有的服务器,但是只等待R个服务器返回结果。因为你只需要等待R个服务器,这意味着在最快的R个服务器返回了之后,你就可以不用再等待慢服务器或者故障服务器超时。这里忽略慢服务器或者挂了的服务器的机制完全是隐式的。在这里,我们不用决定哪个服务器是在线或者是离线的,只要Quorum能达到,系统就能继续工作,所以我们可以非常平滑的处理慢服务或者挂了的服务。
(2)Quorum系统可以调整读写的性能。通过调整Read Quorum和Write Quorum,可以使得系统更好的支持读请求或者写请求。
对于前面的例子,我们可以假设Write Quorum是3,每一个写请求必须被所有的3个服务器所确认。这样的话,Read Quorum可以只是1。所以,如果你想要提升读请求的性能,在一个3个服务器的Quorum系统中,你可以设置R为1,W为3,这样读请求会快得多,因为它只需要等待一个服务器的结果,但是代价是写请求执行的比较慢。
当R为1,W为3时,写请求就不再是容错的了,同样,当R为3,W为1时,读请求不再是容错。
Aruora的读写存储服务器
对于Aurora来说它的写请求只会在当前Log中追加条目(Append Entries),不会覆盖数据。
Aurora使用Quorum只是在数据库执行事务并发出新的Log记录时,确保Log记录至少出现在4个存储服务器之后才能提交事务(Aurora的Quorum系统中,N=6,W=4,R=3)。所以,每个新的Log记录必须至少追加在4个存储服务器中,之后才可以认为写请求完成。
数据分片
目前为止,我们已经知道Aurora将自己的数据分布在6个副本上。但是如果只是这样的话,我们不能拥有一个大于单机磁盘空间的数据库。为了能支持超过10TB数据的大型数据库,Amazon将数据按照10GB为单位分割存储到多组存储服务器上。
即把整个DB volume切分成 10GB 的chunk,每个chunk六个副本存储在三个AZ上。Aurora还需要一个成员组管理服务,用来记录各个chunk所在服务器,常见方式是租约机制的一致性共识协议,比如Paxos。
(2)故障恢复
每个存储服务器有几TB的磁盘,上面存储了属于数百个Aurora实例的10GB数据块。当一个存储服务器故障时,它还带走了其他数百个数据库的10GB数据。如何做崩溃恢复?
从存储服务器的副本拷贝吗?如果网卡是10Gb/S,通过网络传输10TB的数据需要8000秒。
Aurora实际使用的策略是:对于每一个数据块,从Protection Group中挑选一个副本,作为数据拷贝的源。这样,对于100个数据块,相当于有了100个数据拷贝的源。之后,就可以并行的通过网络将100个数据块从100个源拷贝到100个目的地,时长相当于只拷贝一个数据块。
只读数据库
对于Aurora来说,通常会有非常大量的只读数据库查询。读请求,可以发送给多个数据库。
当客户端向只读数据库发送读请求,只读数据库需要弄清楚它需要哪些data page来处理这个读请求,之后直接从存储服务器读取这些data page,并不需要主数据库的介入。之后它会缓存读取到的page,这样对于将来的一些读请求,可以直接根据缓存中的数据返回。Aurora的主数据库也会将它的Log的拷贝发送给每一个只读数据库来更新自身缓存。
这的确意味着只读数据库会落后主数据库一点,但是对于大部分的只读请求来说,这没问题。因为如果你查看一个网页,如果数据落后了20毫秒,通常来说不会是一个大问题。
总结
事务性数据库是如何工作的、怎么与后端存储交互的(性能、故障修复等)
Quorum思想,通过读写Quorum的重合,可以确保总是能看见最新的数据,但是又具备容错性。
数据库和存储系统可以耦合开发。通常来说,存储系统是非常通用的,并不会为某个特定的应用程序定制。因为一个通用的设计可以被大量服务使用。但是在Aurora面临的问题中,性能问题是非常严重的,它不得不通过模糊服务和底层基础架构的边界来获得35倍的性能提升,这是个巨大的成功。
MIT6824笔记八 Aurora