MIT6824笔记十 Spanner
论文材料: https://pdos.csail.mit.edu/6.824/papers/spanner.pdf
Spanner是谷歌公司研发的、可扩展的、多版本、全球分布式、同步复制数据库。它是第一个吧数据分布在全球范围内的系统,并且支持外部一致性的分布式事务。Spanner实现了一个强大的时间API,用于实现非阻塞的读、不采用锁机制的只读事务和原子模式变更。
Spanner论文比较复杂,这里我结合课程,只重点讲述如何利用时间API完成分布式事务,包括读写事务和只读事务。
1 | http://loopjump.com/google_spanner/ |
架构
略
True Time API
分布式环境里,我们无法保证不同机器的时钟总是具有相同的值。时钟偏移为给事务带来很多困扰,比如:

假设有3台机器ABC,A的时间戳快50,BC正常。事务T1更新A和C机器上的值,事务T2更新B和C机器上的值。以2PC为例,T1在时间50开始,协调者得到A=104(实际上为54)和C=50的回复,那么协调者就会选104作为提交时间戳,发起提交请求。T2在时间60开始,协调者得到B=100和C=60的回复,那么协调者就会选100作为提交时间戳,发起提交请求。然后C机器上,就会认为T2比T1先完成,T2的改变就会被覆盖,实际上T2晚于T1。
本质问题是多机器时间drift引起的多机时钟无法同步,从而使得,由于不同事务参与的集群和他们的时钟不同,则使全部数据库的commit时间戳混乱,无法与真实事件发生顺序一致。
简单解释Spanner的TrueTime在分布式事务中的作用 - 阿莱克西斯的文章 - 知乎https://zhuanlan.zhihu.com/p/44254954
Spanner的TrueTime利用硬件和软件的优化,保证给出的时间戳在一个时间区间内TT.now() = [earliest, latest],返回最早的物理时间和最晚的物理时间。这个误差$\epsilon$非常小。
当coordinator选择好时间戳之后,会等待一个ε的时间才告诉参与transaction的partition这个时间戳来commit。
读写事务
| Client | 事务协调者(Paxos组) | Sa(A数据分片Paxos组) | Sb(B数据分片Paxos组) |
|---|---|---|---|
| 事务tid,向Sa的Paxos组leader发起数据分片A的读请求,向Sb的Paxos组leader发起数据分片B的读请求 | |||
| Sa根据2PL,leader对X加锁,Owner是Client | Sb根据2PL,leader对Y加锁,Owner是Client | ||
| Client向事务协调者发起X=X-1,Y=Y+1的操作 | |||
| 收到X和Y更新的操作,通过2PC流程,分别发送X更新操作和Y更新操作到分片A和分片B的Paxos组leader | |||
| 根据2PC流程,leader发现X已经有锁,将读锁升级为写锁,根据WAL进行事务操作的log | 根据2PC流程,leader发现Y已经有锁,将读锁升级为写锁,根据WAL进行事务操作的log | ||
| 发起prepare请求,确认Sa和Sb是否可以准备事务提交,同样需要Paxos组log、复制 | |||
| 检查已拥有锁,log记录事务状态和2PC状态,lock持有状态等信息,以及在Paxos组内同步log,确认整个Paxos组可以准备提交,leader回应OK | 检查已拥有锁,log记录事务状态和2PC状态,lock持有状态等信息,以及在Paxos组内同步log,确认整个Paxos组可以准备提交,leader回应OK | ||
| 发起commit(tid)请求,要求提交事务,同样需要Paxos组log、复制 | |||
| Paxos组实际install log,执行log记录的事务操作,leader释放锁,leaer回应OK | Paxos组实际install log,执行log记录的事务操作,leader释放锁,leader回应OK |
读写事务是直接的2PL和2PC,两阶段锁和两阶段提交。TC(Tansaction Coordinator)由参与事务的某个Paxos Group leader担任,而不是设置一个专门的Paxos Group。
过程:
- client读请求直接发到对应的replica上,写的数据buffer到client自己这里,等执行结束,要提交时,将buffer的这些数据推到对应的参与者,然后选一个参与者作为协调者执行2PC。
- 各个参与者先申请写锁,然后分配一个prepare的时间戳,然后写日志,回应协调者。
- 所有参与者回应协调者,协调者选择一个时间戳s作为提交时间戳,写commit日志(协调者不写prepare日志),然后按照commit wait规则等待TT.now(s)条件满足后,将commit应用到Paxos状态机,然后通知其他参与者进入2PC Commit阶段,
- 其他参与者明白事务确定要提交,因此写outcome日志,这个日志包含了时间戳s的值,同步该日志成功后,应用到状态机,释放锁。
外部一致性
为了实现外部一致性:如果一个事务T2在事务T1提交以后开始执行,那么T2的时间戳一定比T1大。
分配时间戳时遵循两条规则:Start和Commit Wait。
记担任协调者的leader发出提交请求的事件为$e_i^{server}$ ,在所有的锁获得以后,被释放之前,就可以为事务分配时间戳s。
- Start规则保证事务协调者分配的时间戳s不会小于TT.now().latest。TT.now().latest在$e_i^{server}$ 后计算。
- 提交等待规则,就是确保客户端看到事务提交的数据时,事务已经真正提交了,即TT.after(s)为真。
那么协调者要怎么选时间戳呢?
- s大于等于所有其他参与者的prepare时间戳;
- 大于协调者收到client commit请求时TT.now().latest(commit wait规则,先取TT.now().latest为时间戳,等待TT.now().latest为真之后才commit)
- 大于已经分配的时间戳
wound wait
读写事务内部的读操作,使用伤停等待避免死锁。
2PC+2PL的事务实现非常容易死锁,比如A:lock(a) lock(b);B:lock(b) lock(a)。
死锁处理使用伤害等待(wound-wait)的方式,新的事务会等待旧事务,而旧事务杀死新事务,事务被杀死后等待一段时间后用旧的时间戳重启,保证不会饿死也不会出现死锁。
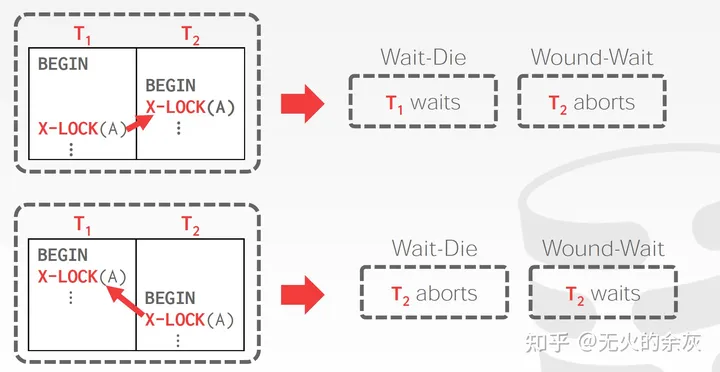
这张图很好说明了伤停等待的效果:优先保证旧事务的执行,旧事务需要新事务的资源时直接杀死新事务;新事务需要旧事务的资源时,等待旧事务完成。
Wait-die 和 wound-die都是利用时间戳进行死锁预防,判断事务的新老级别。
wait-die和wound-wait两种机制都可以避免饿死。任何时候均存在一个时间戳最小的事务,并且这个事务都不允许回滚。由于时间戳总是增长,并且回滚的事务不赋予新时间戳,被回滚的事务最终会变成最小时间戳事务,从而最终会progress。
可以发现在wait-die、wound-wait机制中,事务的时间戳相当于事务的优先级,并且时间戳越小的事务优先级越高。wait-die、wound-wait机制之所以可以保证不出现死锁是因为在各自的机制中,事务间的等待都是单向的。wait-die中只有老事务会等待新事务,wound-wait中只有新事务会等待老事务。
wound-wait机制相比wait-die引起的回滚可能更少。wait-die机制中,如果事务T1由于申请数据项的锁被事务T2持有,而引起T1回滚,则当事务T1重启时,它可能发出相同的申请序列,如果该数据项的锁仍然被T2持有,那么T1会再度死亡,因此在T1最终加锁成功前可能会多次回滚。同样的场景,在wound-wait机制中,T1会一直等待。
只读事务
Spanner实现了无锁机制的只读事务,怎么实现呢?
(1)bad implementation:always read lastet committed value
| 事务 | 时间戳10 | 时间戳20 | 时间戳30 |
|---|---|---|---|
| T1 | set X=1, Y =1, Commit | ||
| T2 | Set X=2, Y=2, Commit | ||
| T3 | Read X (now X=1) | Read Y (now Y=2), Commit |
T3观察到了来自不同事务的写入,而不是得到一致的结果。(不符合可串行化,理论上T3要么X和Y都读取到1,要么都读取到2,要么都读取到X和Y的原始值)。
(2)true idea:snapshot isolation
Spanner实现无锁机制的只读事务,主要依靠时间戳做MVCC(Multi Version Concurrence Control)。
- 为事务分配时间戳(Assign TS to TX)
- 读写事务:在开始提交时分配时间戳(R/W:commit)
- 只读事务:在事务开始时分配时间戳(R/O:start)
- 按照时间戳顺序执行所有的事务(Execute in TX order)
- 每个副本保存多个键的值和对应的时间戳(Each replica stores data with a timestamp)
| 事务(开始的时间戳) | 时间戳10 | 时间戳20 | 时间戳30 |
|---|---|---|---|
| T1 (10) | set X=1, Y =1, Commit | ||
| T2 (20) | Set X=2, Y=2, Commit | ||
| T3 (15) | Read X (X=1) | Read Y (Y=1), Commit |
这里T3需要读取时间戳15之前的最新提交值,这里时间戳15之前的最新值,只有T1事务提交的写结果,所以T3读取的X和Y都是1。因为所有的事务按照全局时间戳执行,所以保证了我们想要的线性一致性或串行化。
每个replica给数据维护了version表,可想而之,表中应该是数据的值以及对应的时间戳。
safe time机制
Spanner还使得读操作能分散到各个机器上,使得读本地副本也能读到最新commit值,依靠的就是safe time机制。
- Paxos按照时间戳顺序发送所有的写入操作(Paxos sends write in timestamp order)
- 读取X数据的T时间戳版本数据之前,需等待T时间戳之后的任意数据写入(Before Read X @15, wait for Write > @15)
- 这里等待写入,同时还需要等待在2PC中已经prepare但是还没有commit的事务(Also wait for TX that have prepared but not committed)
每个副本无论主备,都维护一个tsafe的时间戳,这个tsafe是一个副本最近更新后的最大时间戳。只有读操作的时间戳t,满足$t \le t_{safe}$时,读操作才生效。
$\begin{equation}t_{safe}=min(t_{safe}^{Paxos},t_{safe}^{TM}) \end{equation}$
$t_{safe}^{Paxos}$指已经应用到Paxos状态机的Paxos write的时间戳的安全时间戳,因为Paxos write应用到状态机是顺序应用的,因此只要维护最后一次应用的Paxos write的时间戳就可以了。
$t_{safe}^{TM}$是指所有没有提交的事务的提交时间戳下界。
总结
本文对Spanner解读有限,集中讨论了读写事务和只读事务的实现。读写事务依靠2PL+2PC,同时使用wound wait避免死锁。只读事务利用TT无锁进行,利用saft time保证在本地副本读新的操作。
MIT6824笔记十 Spanner