cmu15-445笔记二 存储模型
存储-1
How the DBMS represents the database in files on disk.
DBMS是怎么在底层表示数据的?
本节融合了三节课内容,主要是数据库底层存储的表现,讨论了页中tuple的存储模型,包括两种类型基于tuple和基于log。讨论了具体的数据表示,系统元数据。最后介绍OLTP和OLAP,对应的行存储和列存储优缺点。简单介绍了数据压缩方法。
存储硬件认知
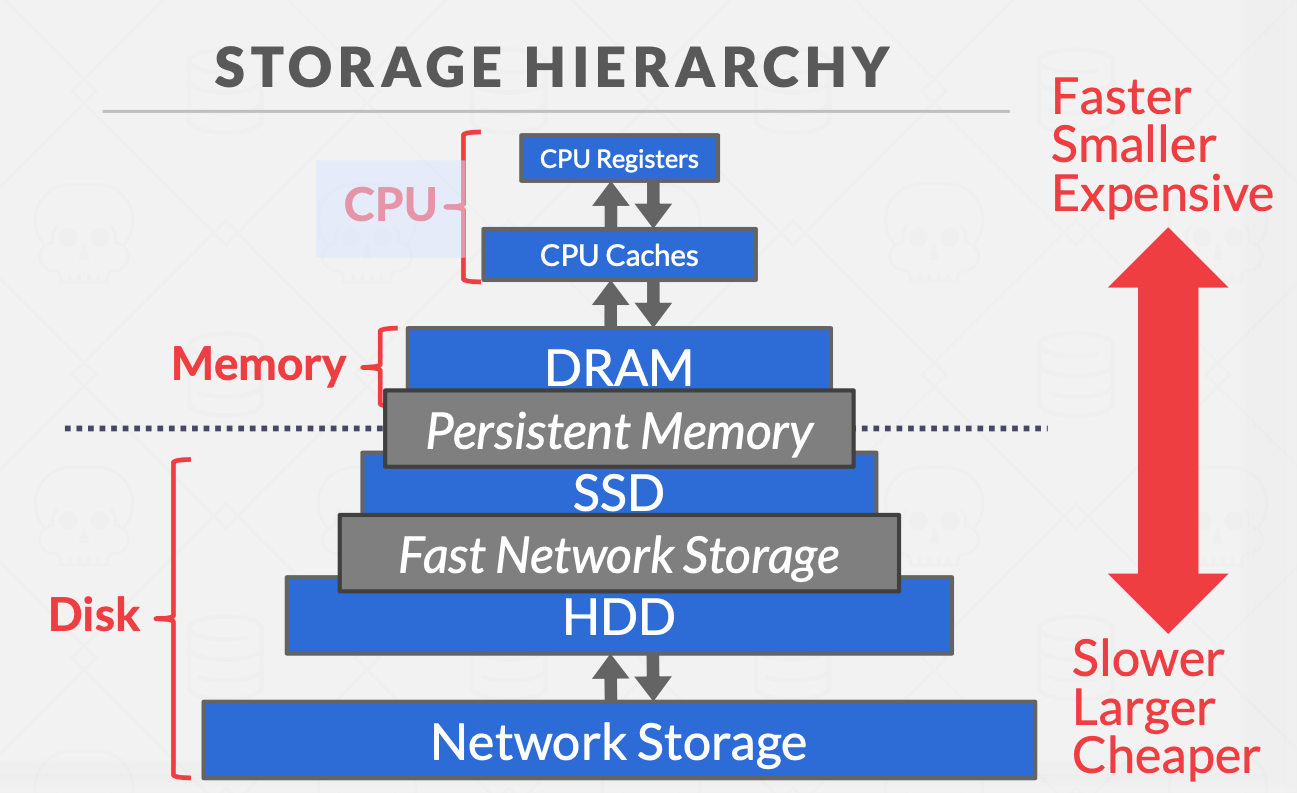
在非易失性存储上进行随机读写通常慢于顺序读写。
DBMS will want to maximize sequential access.
→ Algorithms try to reduce number of writes to random pages so that data is stored in contiguous blocks.
→ Allocating multiple pages at the same time is called an “extent”.
基于磁盘的DBMS存储模型
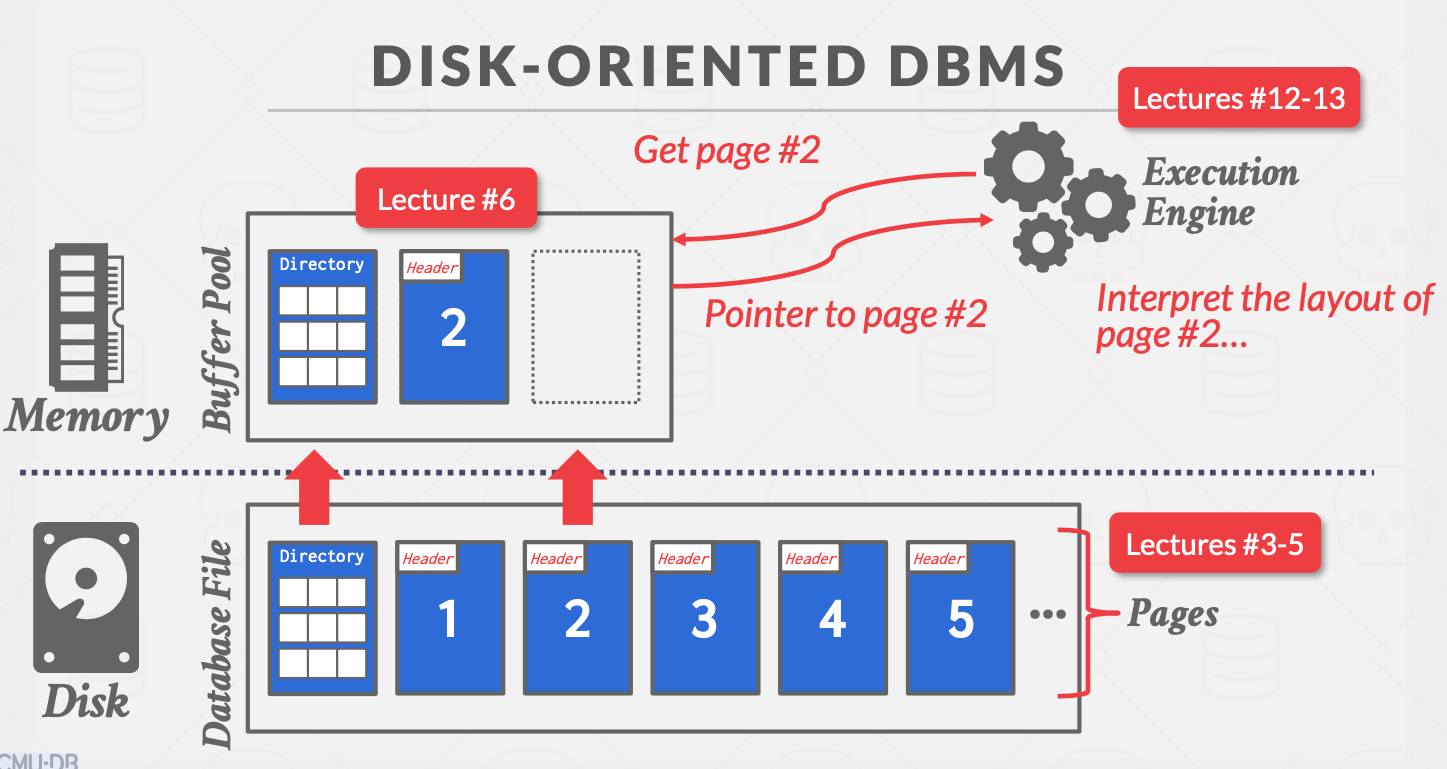
其实这里与OS的VMM无异,BufferPool就是磁盘的缓存,以页为单位进行读取、淘汰。
为啥不让OS做这个事情呢?当然也有一些基于OS的解决方案。
- OS不懂事务,脏页随时可能被刷回硬盘
- DBMS需要合适页替换策略
- DBMS需要合适的多线程控制
数据库底层存储表现
数据库以合适的格式存储在一个或多个文件中,OS不知其内容。
通常有一个storage manager管理文件,将文件视作页的集合。
页是固定大小的块,每个页都有唯一的标识。页大小不固定,4KB-16KB不等。
Heap File
Heap FIile就是存储页的集合,把若干个页放一起作为一个文件管理。当有多个文件时,通过页ID找页的过程就不是那么直观了,我们需要页目录。

页目录需要追踪页的位置、空闲页等
Page模型
一个页分为页头和数据两部分。页头包括了页的元信息:页大小、校验和、数据库版本、事务可见性等;数据体则是存储一大堆的tuple。
数据体该怎么组织?两种方式:
- Tuple-oriented
- Log-structured
Tuple-oriented Storage
(1)Tuple-oriented Strawman Idea
基于元组的存储,将一堆tuple放在一起。只能应对固定长度的tuple,无法很好应对删除操作(破坏顺序,内存碎片)。

(2)slotted pages 基于槽的元组存储
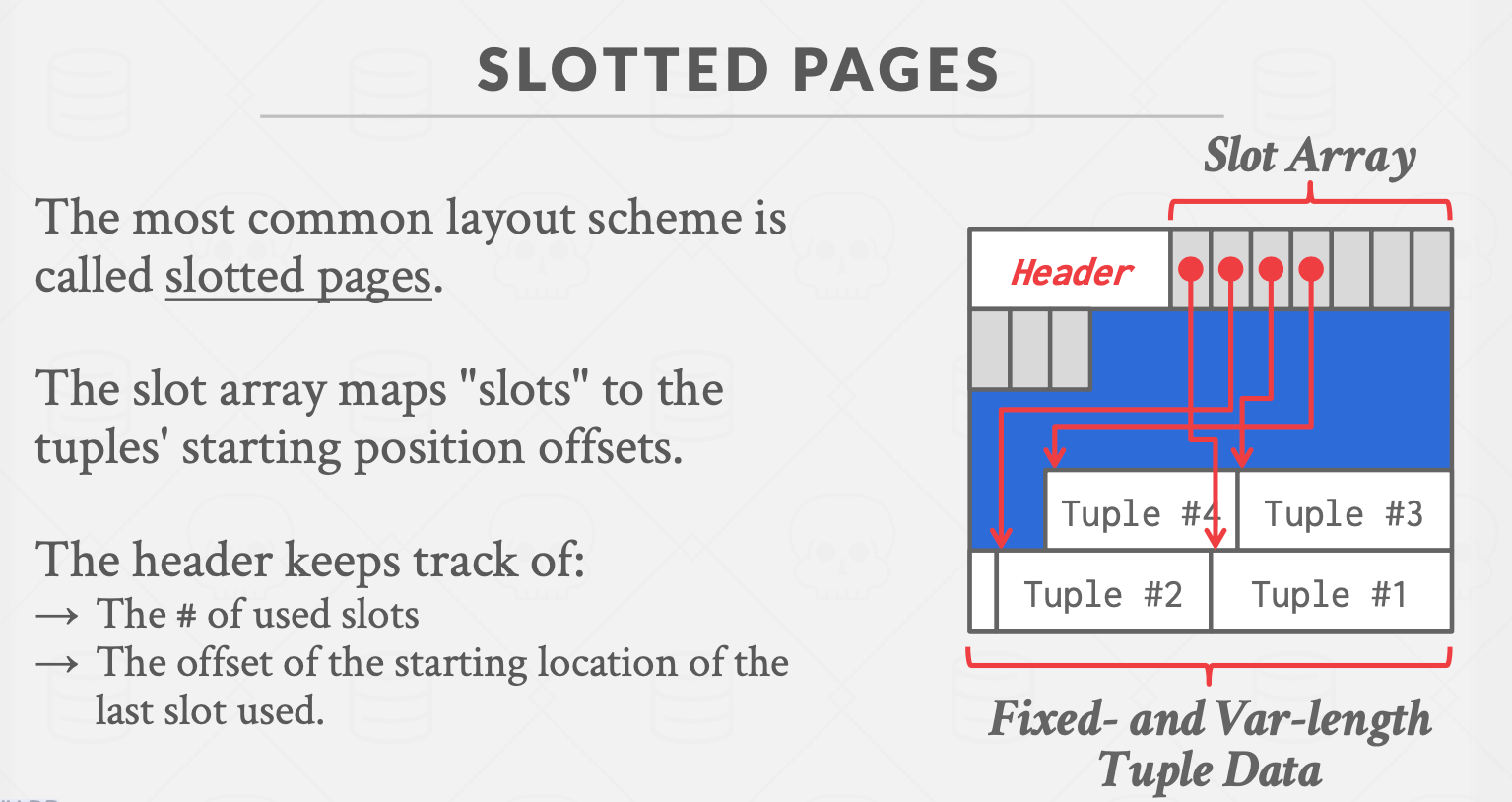
在data区域的最前面有一个slot数组,其中的每个元素和一个tuple构成一对一的映射关系,每个slot记录对应的tuple的位置。
slot是从页的data区域的最前面往后存,tuple是从data区域的最后面往前存。
删除操作后,需要对元组进行规整操作。
Tuple模型

Each tuple is prefixed with a header that contains meta-data about it.
→ Visibility info (concurrency control)
→ Bit Map for NULL values.
Tuple的头会记录事务可见性以及NULL的位数组。为什么要记录NULL的位数组?因为Tuple里的attribute是没有分隔符,紧挨在一起存储。表的类型要么在Page Header,要么在tabel层面存储,DBMS解析每个字段格式,然后根据字段格式再逐位解析数据。NULL值不会存储,一方面节省空间,另一方面避免避免误读。
以下来源于next course,但是内容相关,就放在一起了。
Log-structured storage
log-structured还是page里data部分组织tuple的内容,对比于tuple-oriented storage,log-structured只存储日志而不是数据本身。
DBMS将tuple的change log以append的方式存储,一页存满就刷回磁盘。
日志的格式为:操作+tuple ID+value,由此可见,tuple必须具有唯一ID。
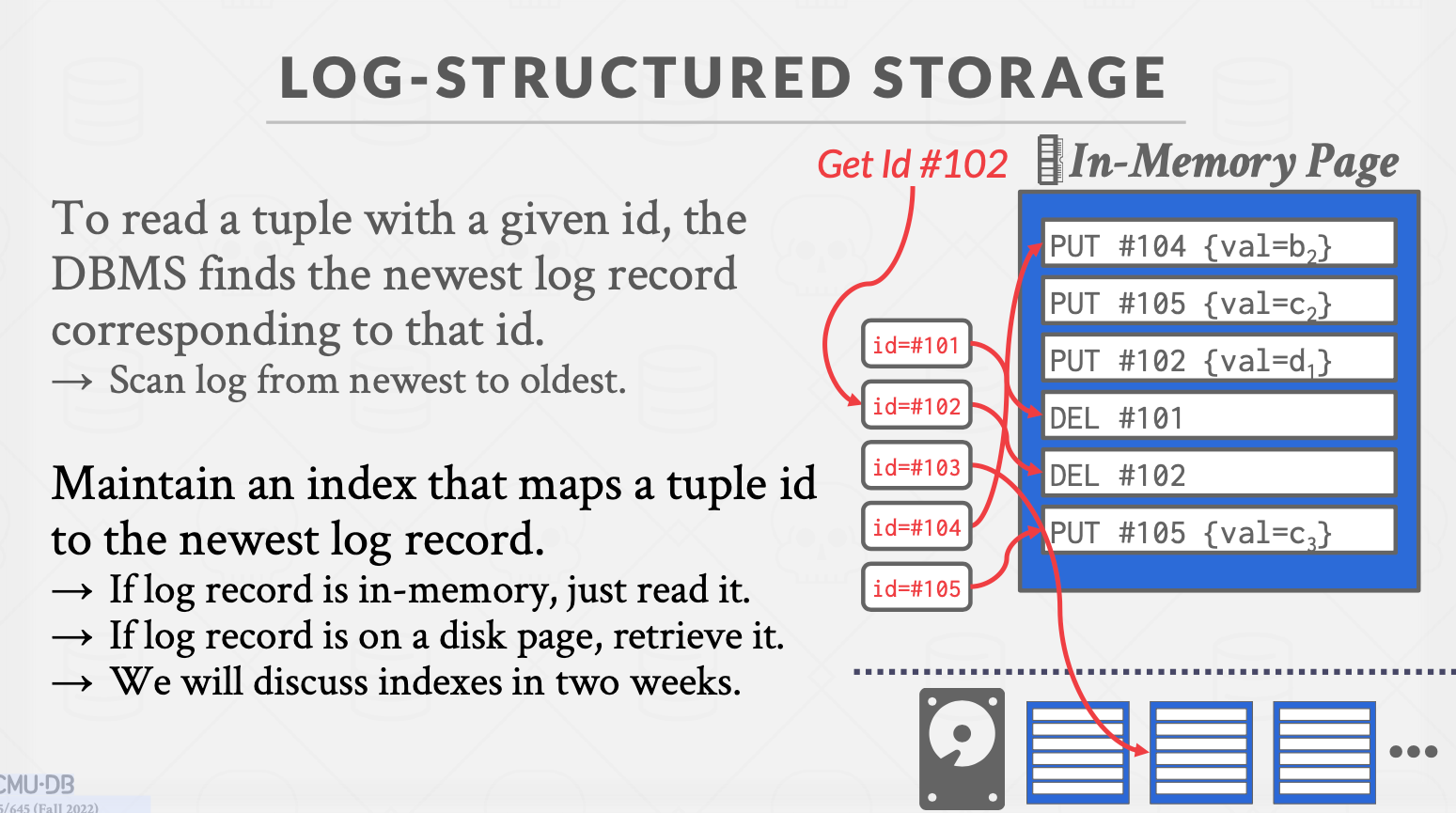
读操作需要回放日志,比如我们要读ID为101的记录的值,就必须从磁盘中取出涉及第一条ID101的日志所在页,然后逐条应用日志,最终得到值。
由此可见,这种操作开销很大。通常有一个索引,记住每个tuple的最新修改在哪一个位置。
由于日志页会越来越大,通常需要进行日志压缩操作,即将若干个页里冗余的操作合并在一起。合并后还可以根据Tuple的ID进行排序,以便进行更好的读取。那么,这就是Sorted String Tables(SSTables)的思想。

压缩日志的方法也不止一种,首先是层级压缩(Level Compaction)。单page压缩、双page压缩、四page压缩,一层一层向下合并。压缩完读数据,从第0层开始读,层层往上。
优点
数据的修改、删除、插入非常快。
基于log存储只需要执行顺序的添加写。而基于tuple的存储,需要先读取相应数据页,再修改数据,最后写回磁盘。
缺点
→ Write-Amplification
写放大,对于一个元组的修改却需要写多次。
→ Compaction is Expensive
日志合并过程代价是昂贵的。
Data Representation
小数的准确存储
浮点数并不是精确存储,对此,DB采取的措施为字面值,即利用字符串表示数字。

长字段存储
超长字段,比如字符串类型存储一部小说,那么这个字段长度可能超出一页的大小。
为了解决这个问题,DB采用引用+溢出页方式管理。字符串内容存储在溢出页中,字段值存储溢出页地址。
如果一个溢出页不够存储,那么采用溢出页链表形式。第二种方式采用外部文件,external file。
System Catalogs
System Catalogs,即DBMS的目录,用于存储DBMS的元数据,比如说表结构,列的结构,索引,视图,用户,权限,内部的统计信息,数据库的元数据都是以表的形式存在的。
- 表、列、索引、视图
- 用户、权限
- Internal statistics其他统计数据
You can query the DBMS’s internal INFORMATION_SCHEMA catalog to get info about the database.
Database workloads
OLTP,在线事务/交易处理,支持快速的操作,读写数据量很小的tuple,而且一般是高并发的,像微信支付这样的场景,同时发生很多交易,但每笔交易涉及的数据量都很小
OLAP,在线分析处理,OLTP这种workload一般来自用户,OLAP则来自于提供相应软件服务的公司本身,比如说微信支付要统计当天有多少笔交易,交易的平均金额是多少,交易总额是多少,这一般对应着复杂的SQL语句,要读大量的数据
第三种,HTAP,则是前两者的混合,意味着可以同时应对这两种类型的workload的数据库架构
OLTP更倾向于写,OLAP更倾向于读。
在不考虑HTAP的情况下(目前工业界HTAP的实践并不多),软件公司会将OLTP和OLAP这两类工作负载分开处理,用小数据库的集群处理OLTP,用分库分表的策略将工作负载分开,等到需要统计分析数据(即OLAP对应的场景)时,对这个集群执行ETL操作(提取数据->做变换->加载),把得到的数据转存到大的数据仓库里,让数据仓库应对OLAP的负载;
行存储
数据库的关系模型和SQL语句并没有要求或者限制数据库底层的数据存储方式,只要通过层层的向上封装能满足它们想提出的抽象即可,即“SQL想查出来一行一行的数据,但数据库不一定在磁盘上一行一行的存”,我们可以修改底层的存储方式,进而更好的应对OLTP/OLAP。
Ideal for OLTP workloads where queries tend to operate only on an individual entity and insert- heavy workloads. 行存储有利于OLTP,因为OLTP的查询通常针对的是一个实体,并且写频繁。比如修改一个用户的用户名,密码等。
Advantages
→ Fast inserts, updates, and deletes.
→ Good for queries that need the entire tuple.
Disadvantages
→ Not good for scanning large portions of the table and/or a subset of the attributes.
对于大量数据针对几个字段的查询不友好。因为基于行存储的引擎需要将所有行读出,解析大量无关字段。
列存储
列存储的情况下,一个字段的所有记录值被连续存储。一个tuple就是存储数据表里的一列数据,实际存储中,数据库不同的页存储不同字段/列。
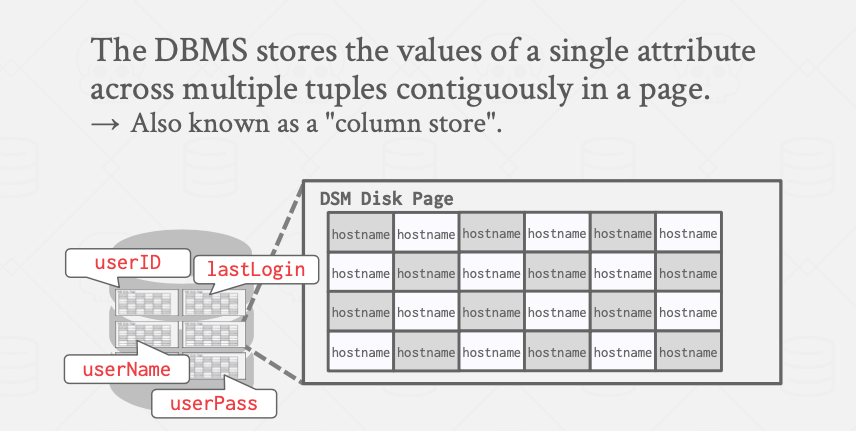
列存储的整行读
- 基于固定偏移
- Embedded Tuple Ids
第一种方法,找到每个字段第offset个值,然后拼起来,得到一行数据。
Advantages
→ Reduces the amount wasted I/O because the DBMS only reads the data that it needs.
→ Better query processing and data compression (more on this later).
适合大量读
Disadvantages
→ Slow for point queries, inserts, updates, and deletes because of tuple splitting/stitching.
插入行记录更费劲了,因为字段被分裂存储到各个表中。
数据压缩
数据压缩可以节省空间。基于columns的数据压缩方法。
- Run-length Encoding 将单列中相同值的运行压缩为三元组
- Bit-Packing Encoding 当属性的值始终小于该值声明的最大大小时,请将其存储为较小的数据类型。比如64位只存8位,前56位均为0.
- Bitmap Encoding 为属性的每个唯一值存储单独的位图,其中矢量中的偏移量对应于元组。比如男女属性用bit表示。
- Delta Encoding 记录同一列中彼此跟随的值之间的差异。类似差分
- Incremental Encoding 避免在连续元组之间重复公共前缀/后缀的增量编码类型。这最适用于排序数据。
- Dictionary Encoding 构建将可变长度值映射到较小的整数标识符的数据结构。将这些值替换为字典数据结构中的相应标识符。(应该是额外表存储映射关系。用序号代替商品类型,避免长字段商品类型重复,节省空间)
cmu15-445笔记二 存储模型