cmu15-445笔记四 哈希表
哈希表具有无法比拟的常数查询性能,是数据库的常用查询数据结构。
本节课探讨了静态哈希与动态扩容的哈希。动态扩容包括链式哈希、extendible hash以及线性哈希。
哈希表能较好应对多次点查询,但无法较好应对范围查询。
哈希表的设计要求
怎么组织数据结构?要存储哪些信息?如何保证并发安全?
设计点:
- 哈希函数 Trade-off between being fast and collision rate
- 哈希模型 如何应对哈希冲突?大空间vs多指令?
Hash Functions
DBMS期望的哈希函数,可以被快速完成,并且不容易发生哈希冲突。
We want something that is fast and has a low collision rate.
Static Hashing Schemes
LINEAR PROBE HASHING
线性指针探测。发生哈希冲突时,检测下一个地址是否冲突,不冲突直接落座,否则继续检测下一个。
缺点:删除数据时不能直接删除,因为现在哈希出的位置与元素的位置不是严格对应的,可能出现哈希在一个空位置上,而那个位置的元素被删除(实际经删除元素线性探测才能找到对应元素)。
删数据的应对方法:
- 每次删除数据时rehash一次(nobody do this)
- Tombstone法(墓碑),采用删除标志位。
问题:采用线性探测发生碰撞时,怎么才能知道往后面找多少个元素呢?
Non-Unique Key

非唯一键是可能会相同的,这时候怎么办呢?
- 链表连接唯一键
- 冗余键
第一种方法,我只存非唯一键去重后的集合,将同一个键的值放在一起,然后用引用的方式将键与多个值连接在一起。
第二种方法,将值与键当做一个复合大键,相当于扩张键的大小,这样每个键就不一样了。
ROBIN HOOD HASHING
罗宾汉散列,采用劫富济贫的思想。具体来说:
- 每个key记录它与最佳位置偏移量,无冲突时偏移量为零。
- 插入时,如果发生哈希冲突,则比较两个key的偏移量。偏移量大的key占据该槽位,偏移量小的key让出位置并与下一个地址的key比较。
这样做不会让某个槽位的偏移量太大,在该哈希策略的执行过程当中,会将开放寻址时被遍历到的槽块的后缀值平均化,不使它们之间的方差太大。
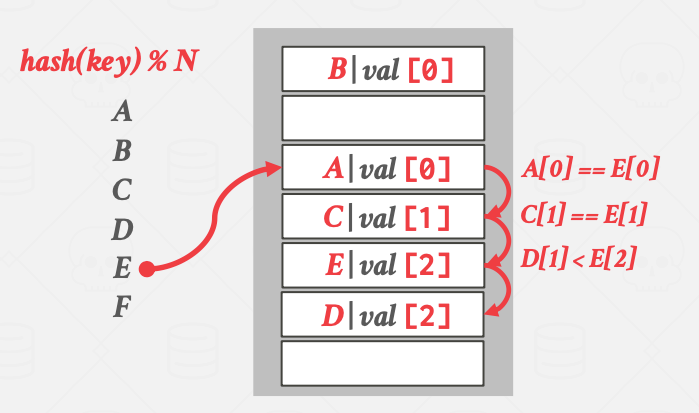
CUCKOO HASHING
杜鹃鸟哈希,杜鹃鸟会将蛋下在其他鸟巢中。具体而言:
- 采取多个哈希表,每个哈希表的哈希函数不同;
- 插入时,检查每个哈希表,选择空闲的一张表的一个位置插入;如果没有空闲位置,那么随机牺牲一个key。被牺牲的key再重新去其他表找位置。
静态哈希总结
静态哈希表最大的问题是存储的key有限,槽数固定。但DBMS无法提前获知key的数量,因此有了动态哈希。
Dynamic Hashing Schemes
CHAINED HASHING
这就是指传统的拉链法解决哈希冲突。这里哈希槽可以放多个元素,称之为哈希桶。一个桶满了再链接一个桶。
Go语言中的哈希表也是基于此方法来实现的,Go的map的每个哈希槽指向的第一个哈希桶中有八个空位,是通过一个结构体来实现的,结构体中有一个成员是拥有八个空位的数组,如果这八个空位被用完了,就会将这个桶链接到一个溢出桶。
Extendible Hashing
拉链式的哈希表的哈希槽的数目固定,发生的哈希冲突越多,哈希桶就越往链表退化。
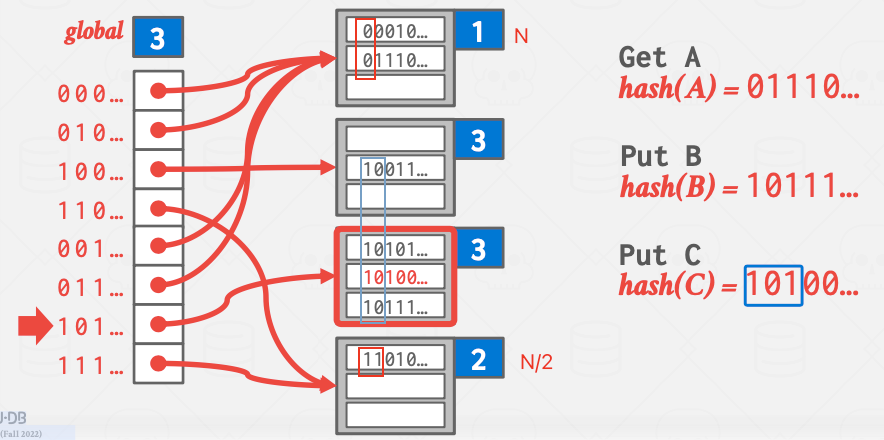
Extendible Hashing(EH)比较复杂,从图中看主要分为两个部分,左边为directory,右边为hash bucket。EH维护两个变量(位计数),为directory维护global depth,为每个hash bucket维护local depth。dirctory可以有多个位置指向同一个hash bucket。
- global depth 用来在directory中查找key对应的bucket
- local depth 在同一个bucket内的所有元素的前local detph位数字相同
(1)查找过程
假设我们要找key=0110,现在global depth=3,取前3位得到011,由图中的值对应bucket是第一个。
(2)插入扩容过程
由key找到对应bucket的过程与查找相同。不同的是,我们还为bucket维护一个bucket max size,当插入某个bucket发现已经满了时,就触发扩容机制,拆分当前桶并rehash桶内元素。
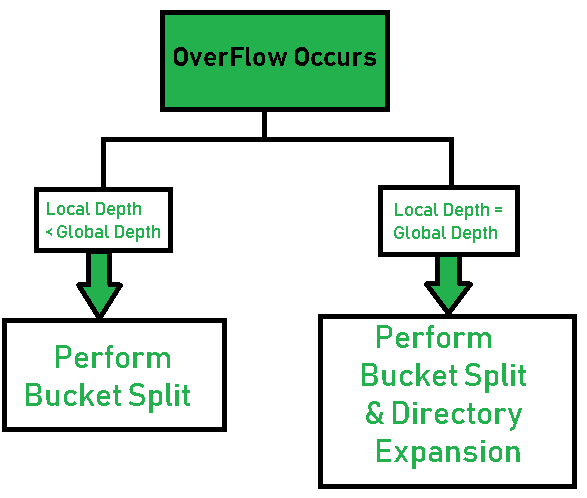
有两种扩容情况:
- local depth < global depth
- local depth == global depth
第一种情况只涉及bucket split,第二种情况涉及bucket split 和 directory expansion。
bucket split过程:增加local depth,然后创建两个新桶,根据新的local depth将原桶的数据分配(采取位运算)到新的两个桶中。最后调整directory的指针,即将指向原桶的指针分配(采取位运算)给新的两个桶。
directory expansion过程:将directory扩容至原先两倍,扩容采取复制的办法。这样指向每一个桶的指针就会变为原先的两倍。
(3)特点
- 每个bucket有若干个指针指向它,具体地,当前bucket有$2^{global-local}$个指针指向它;
- 每个bucket的大小固定;
- data overflow的过程只需要rehash单个桶内的数据,其他桶保持不变。
推荐阅读:https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/
Linear Hashing
线性哈希,线性地一点一点地扩容。
利用一个指针追踪下一个即将要分裂的哈希槽,采用多个哈希函数要决定具体的槽位。
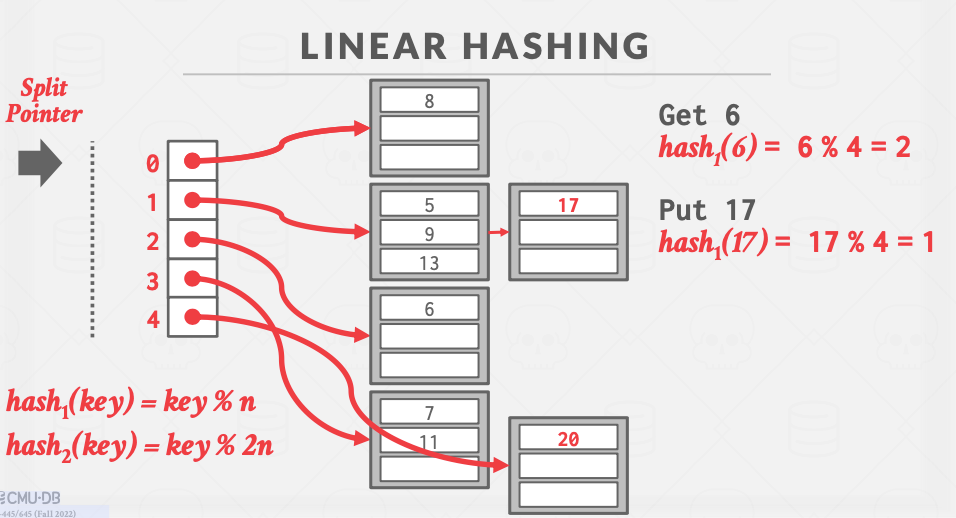
这个过程比较晦涩。具体而言,我们有一个split pointer指向要分裂的槽,初始值 split = 0。哈希表大小n=4。从图中可以看出,当插入17时发生了溢出,此时进行扩容。
split=0,对0号桶进行扩容。0号桶内有8和20两个元素。8%8=0,那么8仍然留在0号桶内。20%8=4,那么20被安置在4号桶内。然后split移到下一个桶,即split=1。0号哈希槽最先开始“分家”,每执行完“分家”操作一次,split pointer指向下一个哈希槽,然后下一次扩容操作又被触发时,就又对此时的split pointer指向的哈希槽执行同样的“分家”操作。这样的每次往下移动一格的行为是线性变化的,因此该策略得名线性哈希。
最终,当split pointer使得最初的所有哈希槽都被“分家”了之后,那这也就完成了Extendible Hashing做的扩容。split pointer会移回最初的起点0号槽,进行下一轮循环,hash1函数不再被使用,hash2函数作为唯一的哈希函数存在。最后的效果与4个哈希槽扩容成8个哈希槽相同。
总结
哈希表是可以在理想情况下完成O(1)复杂度查询的数据结构,这是它在查询这方面巨大的优点,其他的数据结构很难企及,因此它在DBMS中应用广泛,并且哈希表的设计要在速度和灵活性之间做trade-off。
但哈希表对于范围查询(比如说查id=3~10000)没有任何优势,因为原始Key连续的一组KV数据经过哈希运算之后,在哈希桶/哈希槽中的存放就不在连续,这也是“散列表”为何得名,因此往往不用于实现DBMS的索引,这个会由B+ Tree实现。
cmu15-445笔记四 哈希表