实验P1
实验一要求实现一个缓冲池实例,包括动态扩张的哈希表、基于LRU-K的替换器。
动态哈希表的难点在于理清数据结构,数据插入与扩容过程,不要求缩容。
LRU-K的实现比较坑,如果没有理解替换器与缓冲池整体的关系,也就很难理解各个函数的实现。
建议看教材:Database System Concepts 里面讲得比较清晰。
Extendible hash table
原理
Extendible Hashing is a dynamic hashing method wherein directories, and buckets are used to hash data. It is an aggressively flexible method in which the hash function also experiences dynamic changes.
Frequently used terms in Extendible Hashing:
- Directories: These containers store pointers to buckets. Each directory is given a unique id which may change each time when expansion takes place. The hash function returns this directory id which is used to navigate to the appropriate bucket. Number of Directories = 2^Global Depth.
- Buckets: They store the hashed keys. Directories point to buckets. A bucket may contain more than one pointers to it if its local depth is less than the global depth.
- Global Depth: It is associated with the Directories. They denote the number of bits which are used by the hash function to categorize the keys. Global Depth = Number of bits in directory id.
- Local Depth: It is the same as that of Global Depth except for the fact that Local Depth is associated with the buckets and not the directories. Local depth in accordance with the global depth is used to decide the action that to be performed in case an overflow occurs. Local Depth is always less than or equal to the Global Depth.
- Bucket Splitting: When the number of elements in a bucket exceeds a particular size, then the bucket is split into two parts.
- Directory Expansion: Directory Expansion Takes place when a bucket overflows. Directory Expansion is performed when the local depth of the overflowing bucket is equal to the global depth.
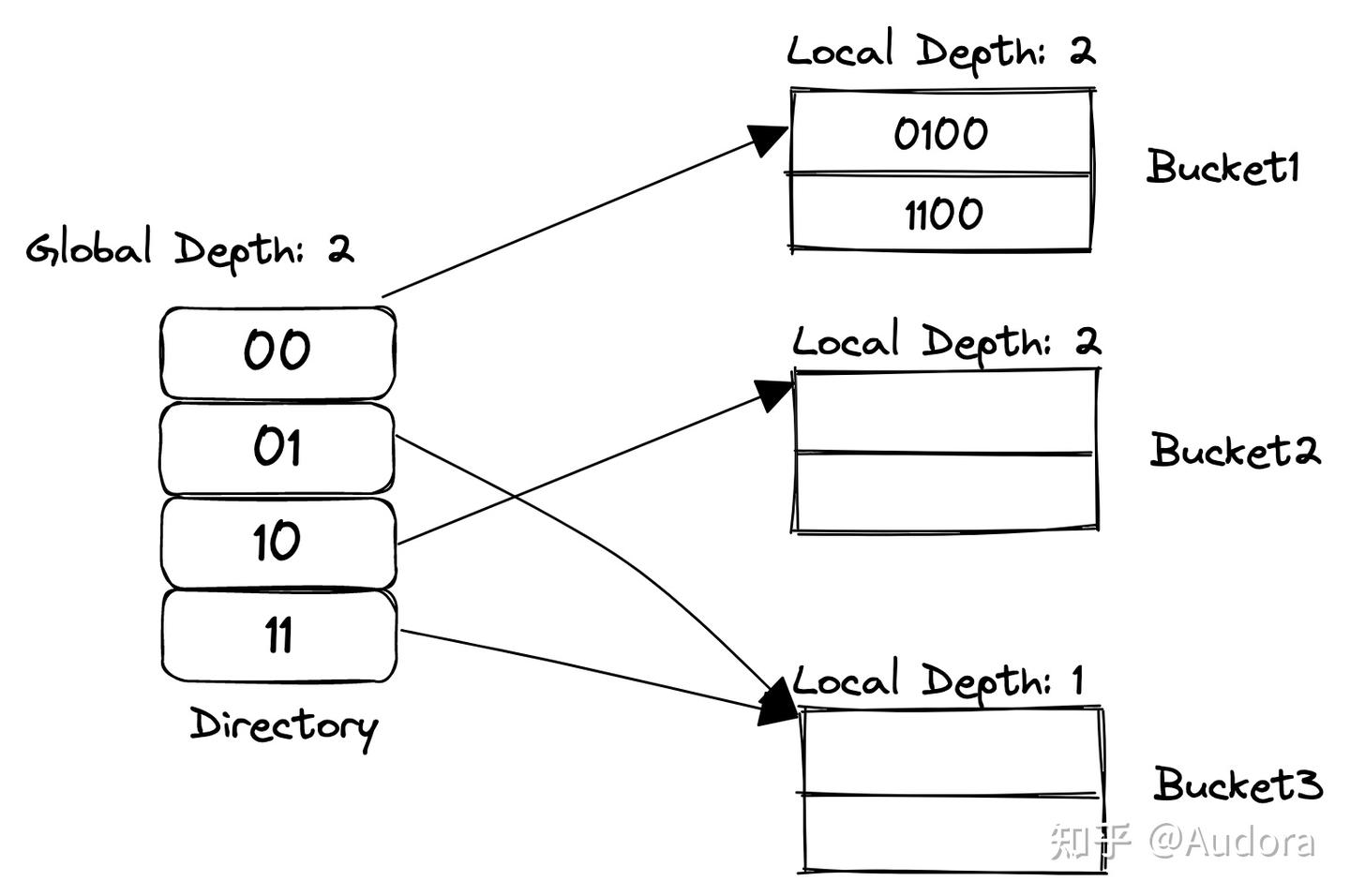
Extendible Hash是动态扩容的哈希表,有两个重要概念:directory和bucket。bucket直译为桶,directory直译为目录。桶是一个固定数量的容器,目录就真的是目录(看作存储桶指针的线性表,表动态增长)。
(1)查找过程
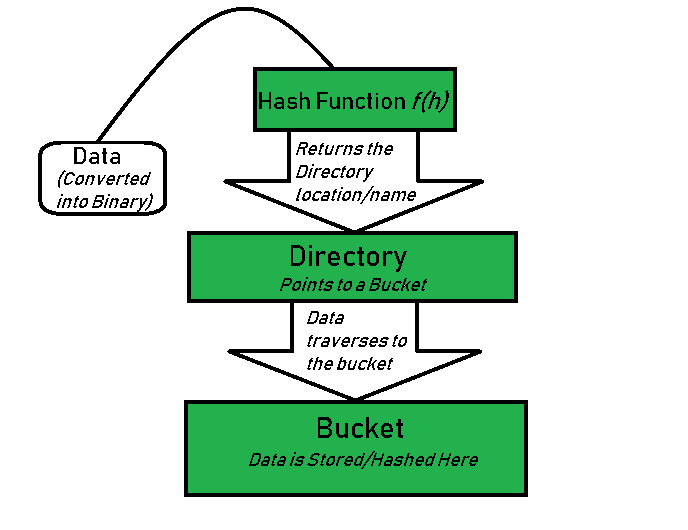
首先,通过hash function找到Directory的Index,然后找到对应的Bucket,Bucket就是个链表,顺序查找。
(2)插入过程
extendible hash table的bucket是固定大小的,当Bucket满时只会创建新桶,而不是扩容桶大小。新桶会链接到目录(directory)上,当目录条目满时,触发目录的扩容。这就是extendible hash table的主要扩容逻辑。
当然,实现上有global depth和local depth来加速判断目录是否需要扩容。具体地,当前bucket有$2^{global-local}$个指针指向它,当 global==local时,只有一个指针,这时候桶满扩容的同时需要目录扩容。
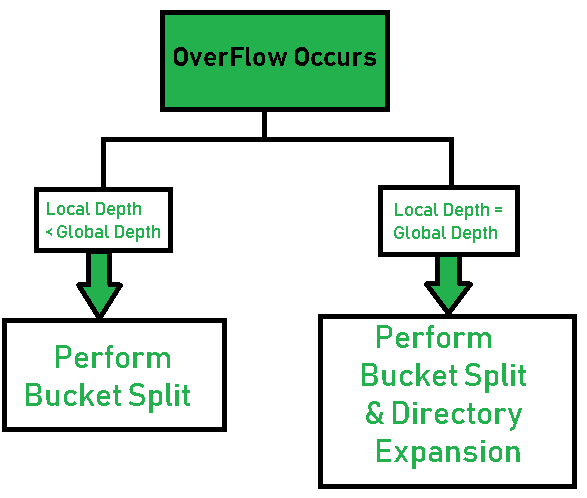
有两种扩容情况:
- local depth < global depth
- local depth == global depth
第一种情况只涉及bucket split,第二种情况涉及bucket split 和 directory expansion。
bucket split过程:增加local depth,然后创建两个新桶,根据新的local depth将原桶的数据分配(采取位运算)到新的两个桶中。最后调整directory的指针,即将指向原桶的指针分配(采取位运算)给新的两个桶。
directory expansion过程:将directory扩容至原先两倍,扩容采取复制的办法。这样指向每一个桶的指针就会变为原先的两倍。
(3)初始情况
global depth=0, local depth =0,directory大小为1,即只有一个桶。
注意点
实验要求的insert接口,对于相同的Key时,能够做到修改值而不是返回错误。这点如果没有确认,线上测试的InsertAndReplace测试项就会不通过。
即使桶分裂、目录扩张后,新的桶可能还是满的(数据的低N位为止都相同),需要递归插入。
递归时需要先释放锁,避免死锁(锁不可重入)。
1 | template <typename K, typename V> |
LRU-K Replacer
原理
核心概念:Backward K-distance ,Backward k-distance is computed as the difference in time between current timestamp and the timestamp of kth previous access。
我们有磁盘页的集合$N={1,2,3,..,n}$,然后给定磁盘页访问的时间序列 $r_1, r_2,…r_t$,其中$r_t = p$表示在t时刻访问页号为p的磁盘页,那么页号p的Backward K-distance 可以表示为 $b_t(p, K)$。
$b_t(p, K) = x$ ,如果 $r_{t-x}=p$,并且在时刻t-x到t中,p出现了K次。
$b_t(p, K) = +\infin$ , 如果在 1,2,3..t 时刻中,p出现不足K次。
LRU-K算法就是在驱逐页面时,选择具有最大Backward K-distance的页。如果有多个页的Backward K-distance都是正无穷,那么可采取其他页面替换算法,比如LRU算法,驱逐最近不常使用的页面。
xv6的缓存实现
在我自己的想法中,Replacer用来记录每个page的访问情况,然后调用eviect决定哪个page应该牺牲。在xv6操作系统的文件块缓存中,它是这么设计的:
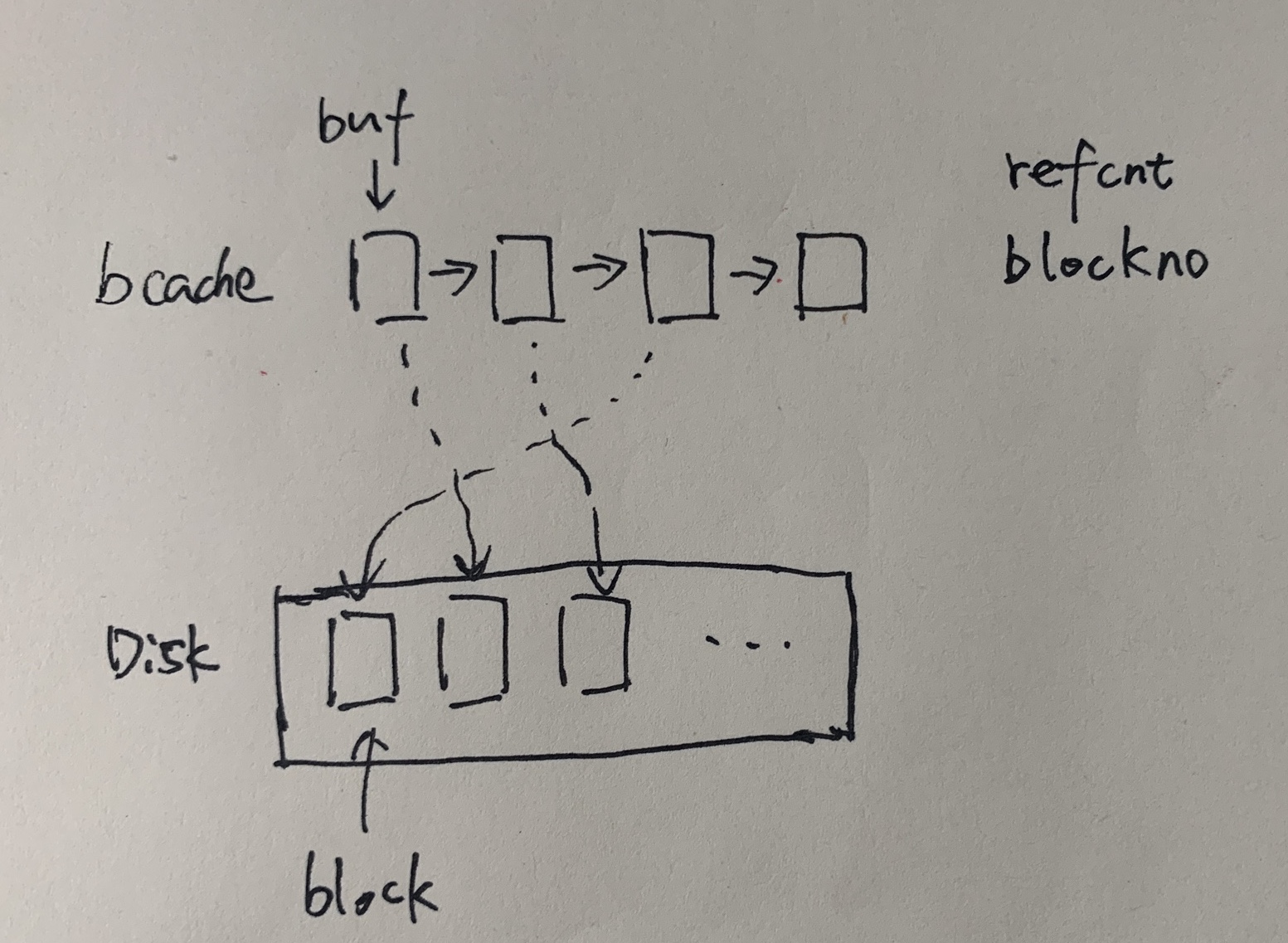
磁盘可以想象成块数组,每个块block有唯一的ID。bcache作为缓存,存储的是一个buf的链表。这个buf有两个属性,分别是refcnt引用计数和blockno对应的块ID。通过bcache拿块的过程就是顺序访问链表,查找有无对应ID的buf,如果没有,选择一个空白的buf,然后从磁盘上加载对应块的内容。如果没有空白的buf,就得牺牲一个refcnt为0的块。链表采用LRU算法组织,链表头部是经常使用的节点。引用计数refcnt维护了当前正在使用块的线程数量,线程get一个块会增加引用计数,release一个块会减少引用计数。当引用计数为零时,会将buf移动到链表头部,方便LRU算法。
1 | // Look through buffer cache for block on device dev. |
实验中的缓冲池实现
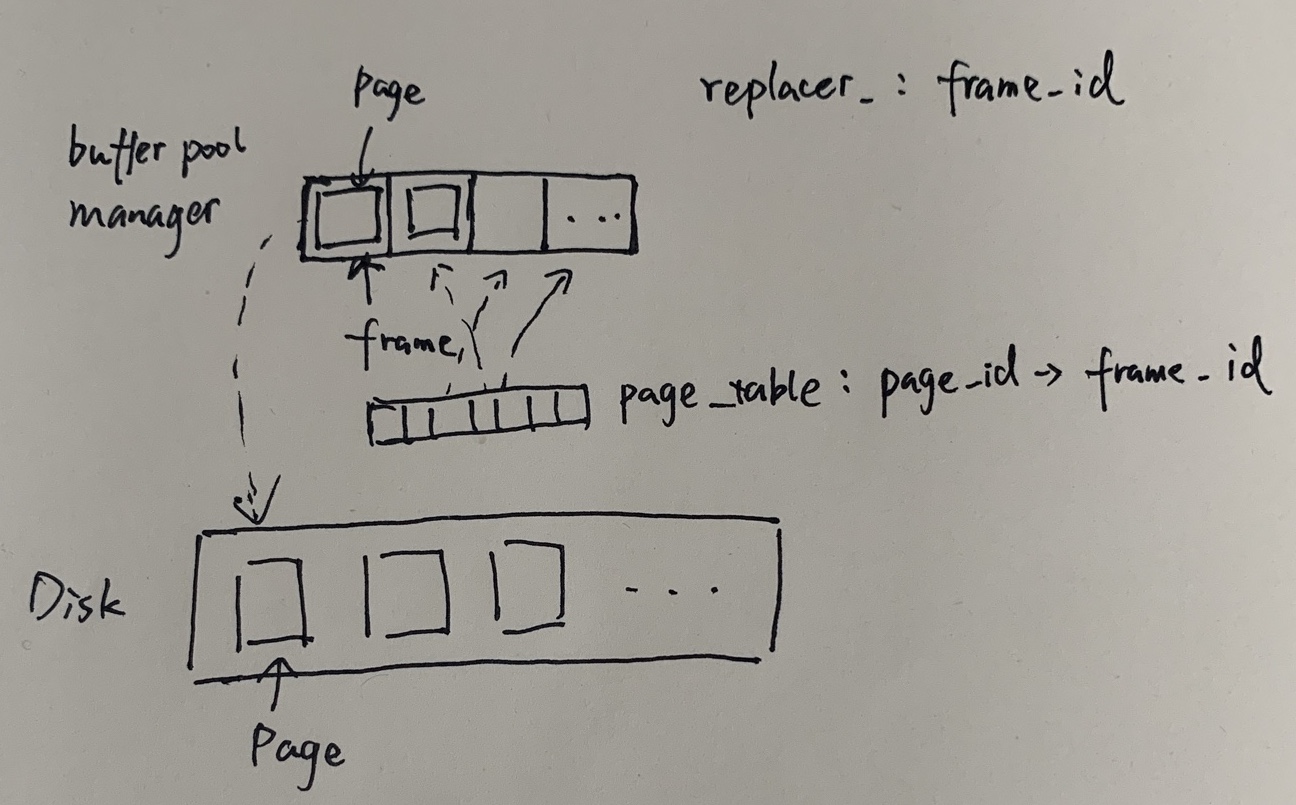
实验中的replacer设计弯弯绕绕,一开始我还没明白为什么replacer管理的是frame而不是page。首先从buffer pool manager来看,它有一个pages_数组作为缓存,有一个哈希表page_table_记录page在哪个frame里。这个frame说白了就是slot,再看实现,其实就是0到$len(pages_)$的整数。
真的是好家伙,比方说数组大小为10,那么replacer就管理这10个整数的出现频次,所以才会有Remove方法出现。
- remove:Remove an evictable frame from replacer, along with its access history.
为什么有remove方法?evit不就好了,而且为什么要清除一个page的access历史?
- RecordAccess: If frame id is invalid (ie. larger than replacer_size_), throw an exception.
为什么一个大于size的frame id会违法?这在当时我是想不通的,frame id不是随机出现的page id吗?结果就是frame id只是个整数,数组的索引不能越界的限制。
这一切的一切,全都源自于buffer pool manager(bpm)和replaces的分离式设计!这使得引用计数的维护和牺牲页面两个功能分开了!由于replacer并不知道一个frame被用了多少次,所以不得不靠bpm来主动设置一个frame的evictable属性,避免页面被提前换出。
注意点
(1)timestamp的实现
只需要在access的时候自增timestamp变量。
(2)pin frame的实现
利用一个数组记录相应frame是否固定或者将pin与frame组成一个新结构体。这是因为固定的frame解除固定后,还需要被正常追踪LRU-K。
(3)大小的追踪(replacer_size不是max_size)
- 可驱逐的帧数量 replacer_size_
- 不可驱逐的帧数量 curr_size_ 减去 replacer_size_
- 最大追踪的帧数量 max_size_ (curr_size_ 小于等于 max_size_)
The size of LRUKReplacer is represented by the number of evictable frames. The LRUKReplacer is initialized to have no frames in it. Then, only when a frame is marked as evictable, replacer’s size will increase.
实验踩坑
(1)线上测试,我用自己实现的根据backward K距离牺牲页面的算法不通过。网上查看,一些是依据前第k次的时间戳排序,一些人直接将访问次数达到K次的的frame用LRU算法实现(连一个帧的access history都不需要存储,只需要记录访问次数)。
我修改代码为后一种方式后通过了在线测试,真是魔幻!
(2)死锁问题
void LRUKReplacer::RecordAccess(frame_id_t frame_id) 中调用 auto LRUKReplacer::Evict(frame_id_t *frame_id) -> bool
由于两个函数都是一个大锁保护,造成死锁。
解决方法:利用一个Internal函数,解除锁的依赖。
1 | auto LRUKReplacer::Evict(frame_id_t *frame_id) -> bool { |
Buffer pool instance
原理
首先,从Buffer pool的使用者上来看,Buffer pool最主要的功能就是查找页FetchPg(page_id_t page_id)和新建页NewPg(page_id_t *page_id)。上层使用者希望通过一个page id得到对应的页内容,或者希望插入一些新数据(需要得到一个空页)。
从Buffer pool里面来看,有一块连续的地址空间Page *pages_;用来存Page,但是Page在这块空间可能是分散存放的(写回一个脏页时,该位置上的Page不再使用,可以被覆盖。Buffer pool不作内存整理)。对应的,有一个ExtendibleHashTable<page_id_t, frame_id_t> *page_table的哈希表,维护着page id 与 page index(page 在数组中的位置)的映射。这个page index表现为frame id。怎么理解呢?帧(frame)相当于快递盒子,页(page)作为物品放置于快递盒子中。缓冲池管理固定个数的盒子,比如10个盒子。于是有一个空闲链表std::list<frame_id_t> free_list 追踪空盒子。
- 通过页找到帧
PageTable - 通过帧找到页
pages_[frame_id]
当所有盒子都满了时,由LRUKReplacer *replacer_决定哪一个盒子应该置空,盒子本身是重复使用的。LRUK算法根据最近K次使用盒子时间来决定哪个盒子应该置空。
实现注意点
(1)基本逻辑
FetchPg的逻辑
首先在缓冲池pages_里查找,如果找到了,更新访问记录并返回。如果未找到,那么我们需要一个帧来装这个页,优先从空帧中找,否则需要牺牲一个帧。然后通过DiskManager装载Page的内容,最后更新访问记录并返回。
NewPg的逻辑
首先需要找到一个帧来装载Pg。从空帧链表中找或者牺牲一个帧。然后通过AllocatePage()分配一个新页,将页装在帧上,更新访问记录并返回。
(2)牺牲帧时的操作
牺牲得到帧里面的页可能是Dirty的,需要写回到磁盘,同时解除页与帧的映射关系。
(3)Unpin时,页的diry设置
1 | pages_[frame_id].is_dirty_ = pages_[frame_id].is_dirty_ || is_dirty; |
不可能从脏页变成干净页。只有刷新页的时候才会设置干净页。
(4)小心维护引用计数和Replacer的分离设计
引用计数和Replacer相互分离,需要额外通过设置evictable属性避免引用计数大于零的页面被驱逐。
1 | auto BufferPoolManagerInstance::FetchPgImp(page_id_t page_id) -> Page * { |
这个后果就是:这两个语句需要绑定在一起。
1 | pages_[frame_id].pin_count_++; |