cmu15-445笔记五 索引与B+树
本节课首先介绍B+树索引,然后介绍B+树的设计,最后介绍B+树的优化措施。
表索引
A table index is a replica of a subset of a table’s columns that is organized and/or sorted for efficient access using a subset of those attributes.
DBMS 可以查找表索引的辅助数据结构,以更快地查找元组,而不是执行顺序扫描。
DBMS 确保表和索引的内容在逻辑上始终同步。
B+树
B+树是一种保持数据排序并且自平衡的数据结构,允许搜索、顺序访问、插入和删除。B+树对于磁盘上读写多个页的文件具有特殊的优势。B+树从二叉搜索树演变而来,实际上是M-way的,一个内部结点可以有最多M个孩子结点。
Formally, a B+Tree is an M -way search tree (where M represents the maximum number of children a node can have) with the following properties:
It is perfectly balanced (i.e., every leaf node is at the same depth).
Every inner node other than the root is at least half full (M/2 -1 <= num of keys <= M-1)
Every inner node with k keys has k+1 non-null children.
B+树的每个节点都是一个KV数组,这个数组内部是严格按照K的大小顺序组织的,内部节点的V存储的是指向子节点的指针,叶子节点的V是存储的数据。
更具体地,叶子结点的V有两种方式存储数据:
- Record IDs:Record IDs refer to a pointer to the location of the tuple.
- Tuple Data:leaf node store the the actual contents of the tuple.
B+树的插入
首先找到需要插入到的叶子节点,然后在叶子节点里依照之前维护好的顺序将新的数据插入到正确的位置,如果这个叶子节点已经满了的话,就把它分裂成两个叶子节点。
叶子结点分裂过程:均匀地重新分配条目并复制中间键,将指向 L2 的索引条目插入到 L 的父项中(如果父结点也满了,同样进行分裂操作)
内部结点分裂过程:均匀地重新分配条目,但向上推中间键。
B+树的删除
首先找到要删除结点的叶子结点L。
- 如果L有半数以上,那么直接删除key。
- 否则从邻居中借一个数据
- 如果邻居数据不够,合并两个叶子,并删除父结点中指向L的指针。
很多的DBMS会推迟这个合并的操作,因为在很多情况下,从B+树中删掉某个数据之后还会再插入新的数据,这样刚刚合并好的节点就有可能要再进行分裂,造成很大的开销。
重复键的处理
对于重复的键,该怎么处理?有两种方法:
- Append Record ID:在原先的Key上再添加一个unique Record ID,将 <key, recordId>作为一个大键,保证大键唯一性。
- Overflow Leaf Node:在原有的叶子节点上外接一个溢出节点。
B+树设计考量
节点大小
B+树节点的大小最好和文件页的大小一致或者是其倍数,以便于管理。
(1)磁盘设备类型
磁盘越低速,B+树节点占用的存储空间应该越大,这样的话一次对单个节点的磁盘I/O就可以读取更多的数据,索引更容易命中;
越快速的设备,B+树节点占用更小的存储空间。因为B+树节点占用的空间越大,所存储的数据越多,冗余数据也越多。
换句话说,就是IO次数与索引命中之间的平衡。越快速的设备IO代价越低,那么可以减小节点大小,降低索引命中率。
(2)DBMS负载类型
B+树的节点大小的选择也和DBMS所应对的负载类型有关,如果是应对OLAP类型的负载,常常会全表扫描,会遍历B+树的叶子节点,因此不妨让每个节点大一点,这样单次I/O就能扫描更多数据。
对于OLTP这种事务型的经常进行点查询的工作负载,会经常从B+树的根节点遍历到叶子节点,我们不妨就让B+树的节点小一点,这样的话在查询过程中,在节点之间跳跃的开销就会变小
节点合并的阈值
DBMS会延迟B+树删除操作后的节点合并,从而减少重新组织B+树带来的开销
可变长度的Key的处理
如果拿字符串当作索引的Key,那么很有可能它是变长的,对于变长的Key,DBMS有如下的处理方式:
- 改为存储Key的指针:由于必须为每个键维护指针的效率低下,因此在生产中使用这种方法的唯一地方是嵌入式设备,其中的微型寄存器和缓存可能会受益于这种空间节省。
- Padding策略:固定长度策略,将不足长度的key补空字节,达到设计的固定长度。
- 键重定向(Key Map/Indirection):键替换为单独字典中键值对的索引。(这与tuple在Page里通过slot来组织的方式相似,节点里面有数组形式排布的slot,slot中存储指向对应KV的指针,这使得节点中KV的存储有很大灵活性)
节点内部搜索
在工业界的B+树实现中,一个节点里会存储成百上千个数据,假设我们之前通过索引,已经确定好了想要获取的数据就在某个特定的叶子节点当中,但是叶子节点中仍然有成百上千条数据,如何更快地从中把我们想要的那一条数据找出来仍然是不小的挑战,因此有如下的策略:
- 线性扫描,可以理解为暴力地去遍历,虽然看起来低效,但很多数据库都是这么实现的,因为相比于把叶子节点从磁盘读入缓存池用的时间,暴力扫描用的时间微不足道
- 二分查找,就是使用简单的二分查找算法,因为叶子节点中的KV都是按照K的大小有序排列的
- 插值估计:此方法利用存储在节点上的任何元数据(例如 max 元素、min 元素、平均值等),并使用它来生成键的大致位置。例如,如果我们在一个节点中查找 8,并且我们知道 10 是最大键,$10 -(n + 1)$ 是最小键(其中 n 是每个节点中的键数),那么我们知道从最大键开始搜索 2 个插槽,因为在这种情况下,距离最大键一个插槽的键必须是 9。
B+树优化
性能优化、存储空间优化
Pointer Swizzling
因为 B+Tree 的每个节点都存储在缓冲池的页面中,所以每次加载新页面时都需要从缓冲池中获取它,这需要锁存和查找。为了完全跳过这一步,我们可以存储实际的原始指针来代替页面 ID(称为“swizzling”),从而完全防止缓冲池提取。
Rather than manually fetching the entire tree and placing the pointers manually, we can simply store the resulting pointer from a page lookup when traversing the index normally. Note that we must track which pointers are swizzled and deswizzle them back to page ids when the page they point to is unpinned and victimized.
就是说缓存池已经加载了我们想要的页面,之后的访问相同页避免再次访问缓冲池(其中有锁和查找)。相比之下,我们自己建立哈希表,避免并发。
Bulk Insert 批量插入
当最初构建 B+Tree 时,必须以通常的方式插入每个键会导致持续的拆分操作。由于我们已经为叶子提供了同级指针,因此,如果我们构造一个排序的叶节点链表,然后使用每个叶节点的第一个键自下而上轻松地构建索引,则初始插入数据的效率要高得多。
这种思想和创建堆时可以选择快速建堆策略而非一个一个地插入建堆的思想相似。
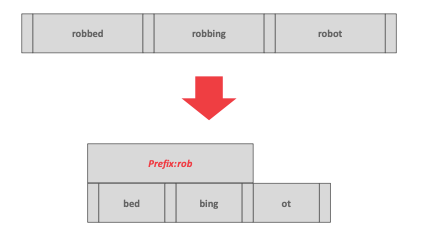
Prefix Compression 前缀压缩
在同一个叶子节点里很多Key的前缀是相同的,我们可以在叶子节点的元数据里面找个地方记录一下公共的前缀,实际存储Key的时候只需存储前缀后面不一样的内容。
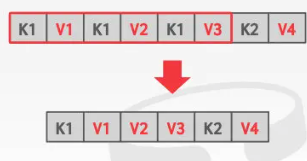
Deduplication 去重
有些时候K会有冗余的可能,多个KV的K是一样的,我们其实可以通过去掉冗余的K来减少所占用的存储空间。
Suffix Truncation 后缀截断
- 内部节点的 Key 只用于**流量导向( direct traffic )**,我们并不需要整个Key。
- 存储将探测正确路由到索引所需的最小前缀。
我的理解:相当于同层内 采用前缀压缩。
cmu15-445笔记五 索引与B+树