cmu15-445笔记六 排序与聚集
本节课介绍了排序与聚集。由于数据库中的数据量巨大,排序与聚集无法在内存中完成,因此有了相应的基于外存的算法。
排序
排序的好处:
- ORDEY BY
- GROUP BY
- JOIN
- DISTINCT
外部归并排序
如果要排序的数据不能全部装载到内存中,那么外部归并排序(external merge sort)是常用的排序方法。这种方法将数据分为若干个块,对每个块排序,然后合并已排序的块。
- 排序:在内存中排序一块数据,然后将排序好的块写回磁盘。
- 归并:将已排好序的几个块合并为一个更大的有序块。
一个sorted run就意味着一次排序,排序后的结果是一列键值对,即KV。V有两种形式,分别为早物化/晚物化。早物化的V是Tupl本身,晚物化的V是Record ID。晚物化能够解决早物化时Tuple过大引起的内存开销问题。
2路归并排序
排序阶段:读取硬盘上的一个页,排序 ,然后写回硬盘。
归并阶段:在内存上开辟3个页,读取2个已排序的页,然后归并到第三个页,当第三个页满时,将其写回磁盘。继续merge,直至完成。
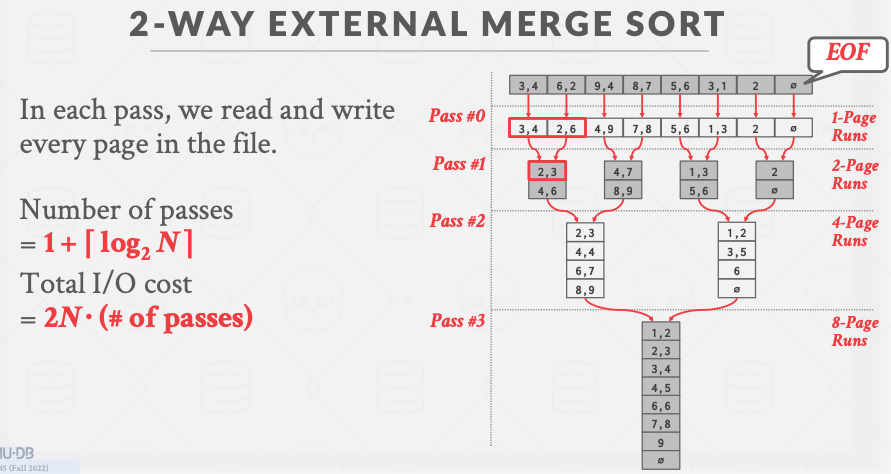
Passes我愿称之为轮数,一共要运行 $1+\lceil \log_2N \rceil$ 次。由于每个pass都需要读写全部的page,所以总的IO是 $2N\times(# passes)$
2阶外排序的情况下,只需要缓存池有3个页大即可,两个用于存储待排序的输入数据,另一个用于存放排序后的中间结果。如果内存充足,可以作优化:
- Double Buffering Optimization:将下次要读的数据提前读入内存。
- General External Merger Sort:通用的N阶外排序。
N阶外归并排序
The generalized version of the algorithm allows the DBMS to take advantage of using more than three buffer pages.
假设待排序的数据有N个页大小,缓存池有B个页大小,runs称之为一次排序的页的集合。
排序阶段:一次性读取B个页排序(这B个页就是一个run)。
合并阶段:读取B-1个已排序好的页,然后合并这B-1个页。
Passes:$1+\lceil \log_{B-1}{\lceil N/B\rceil} \rceil$
Total IO: $2N\times(# passes)$

使用B+树
于B+树的叶子节点本身就是天然有序的,所以当我们使用B+树来作为我们感兴趣的KV的索引时,就无需排序了,B+树分为聚簇和非聚簇的,聚簇的B+树与早物化的概念相似。
聚集
将来自多个tuple的单个attribute坍缩为一个实值。DBMS需要快速地找到多个具有相同attribute的tuples。两种方法:排序和哈希。
排序聚集
实现order by,distinct。
The DBMS first sorts the tuples on the GROUP BY key(s). It can use either an in-memory sorting algorithm if everything fits in the buffer pool (e.g., quicksort) or the external merge sort algorithm if the size of the data exceeds memory. The DBMS then performs a sequential scan over the sorted data to compute the aggregation. The output of the operator will be sorted on the keys.
对Group By的key进行排序,然后就能快速找到相同key的Group。通常来说,这样的Sql还需带有Order By以最大效率利用排序。
哈希聚集
如果我们仅仅是想实现某类数据的聚集(比如GroupBy或Distinct),不需要在此基础上再进行排序(因为排序往往都会有不小的开销),那可以使用哈希聚集。
如果数据量比内存大,可以使用外部哈希聚集策略。
partition阶段:一个partion就是拥有相同哈希值的kv。parition会因内存不够存储到磁盘上。
假设我们有B个缓冲页,B-1个缓冲页用于partion,1个页用于数据输入。
rehash阶段:为每个pation构建一个内存的hash table(不同于第一阶段的哈希表),然后计算aggregation。具体而言,遍历这个哈希表的每个桶,得到具有符合条件的tuple。这里假设每个partion都能放入内存。
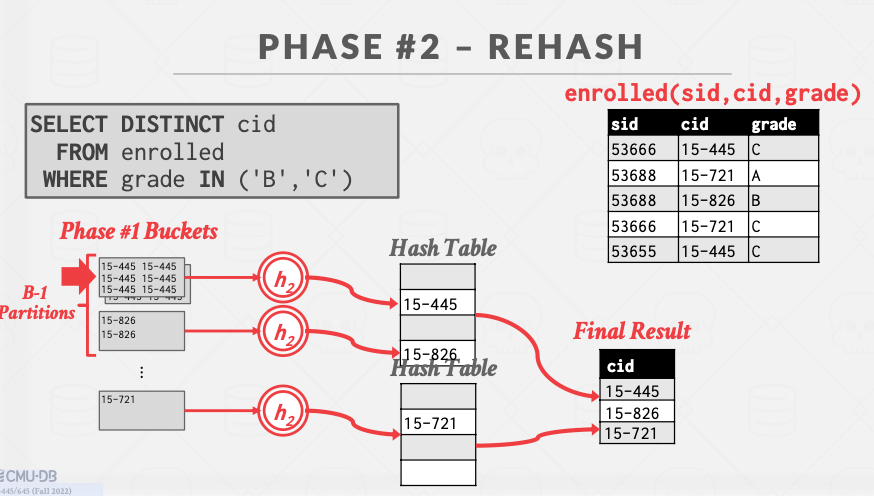
前面讨论的都是去重,很多聚集操作并不是以去重为终点,而是在去重之后再进行一些计算得出一些额外的统计值,这种情况下,在rehash阶段,还需额外记录一些动态变化的临时结果。
During the ReHash phase, the DBMS can store pairs of the form (GroupByKey→RunningValue) to compute the aggregation. The contents of RunningValue depends on the aggregation function. To insert a new tuple into the hash table:
- If it finds a matching GroupByKey, then update the RunningValue appropriately.
- Else insert a new (GroupByKey→RunningValue) pair.
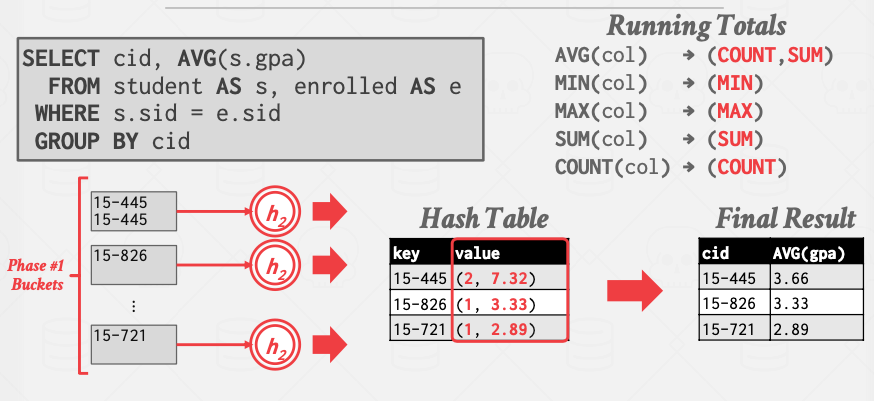
计算AVG就是以count, sum的形式。
cmu15-445笔记六 排序与聚集