cmu15-445笔记七 表连接
表连接是关系型数据库的最频繁的操作之一。如何优化表连接是提高数据库性能的重点。
本节课介绍了三种Join,分别是Loop join、sort-merge join和hash join。
join的输出
连表时,有个原则,要尽量把小表(所占页数较少的表)放在左侧(此时这个小表也叫驱动表),这会减少硬盘IO次数。
join算子输出的内容由以下三个因素决定:
- SQL处理模型
- 存储模型
- 整个SQL语句所需要的数据
join算子输出的内容有如下几种:
直接输出数据
这种情况属于早物化,被join的都是完整的tuple,因此join操作结束后输出的就是完整的一行数据输出record id
这种属于晚物化,join后得到的一条数据里只含有在相对应的原始表中的record id,而不是全部的字段。这种输出方式符合列存储的思想,DBMS在对join后得到的表执行查询时无需拷贝不需要的数据。
join的开销
join操作有时可以通过笛卡尔积来完成,先对两个表进行笛卡尔积,然后用谓词来筛选,但这非常低效,因为笛卡尔积导致的中间结果非常巨大,所以说除了笛卡尔积以外,DBMS的设计者更倾向于采用下面的几种join算法:
M pages in table R, m tuples in R
N pages in table S, n tuples in S
Nested Loop Join
Nested Loop Join
1 | foreach tuple r ∈ R: |
外层循环是遍历R表的所有行,对于R表的每一行,再开一个内层循环,遍历S表的所有行,看r和s能不能连上。
它十分低效,当扫描S的整张表时,缓存池完全用不上(比如说S有3个页大,缓存池有1个页大,扫描S全表的时候会把缓存池灌满,然后不断地淘汰)
Block Nested Loop Join
1 | foreach block BR ∈ R: |
Nested Loop Join对于R表的每条tuple,都需要完整地遍历一遍S表;而Block Nested Loop Join对于R表的每一个Block才去完整遍历一次S表。可以大大减少S表的IO次数。
回到现实中,如果我们的缓冲池足够大,有B个缓冲页,那么可以拿出B-2个页给R表,1个页给S表,1个页用于输出。
1 | foreach B-2 pages pR ∈R: |
这个算法的思想就是把缓存池尽可能多地给outer table使用,从而减少遍历inner table表的次数,从而减少开销,毕竟给inner table用的缓存池再大,在遍历inner table时,都会面临缓存重刷的问题。
INDEX NESTED LOOP JOIN
1 | foreach tuple r ∈ R: |
在前面介绍的各种嵌套循环join当中,无论怎么优化都会不止一次遍历右侧的表,这本质上是因为我们没有构建相应的索引,只能通过暴力地遍历去探测有没有可以join的tuple。因此就有了如下的优化方式:我们以inner table的参与join的那一列字段为key构建索引,这称为index nested loop join或lookup join。

嵌套循环总结:
- 小表(页数少)作为外表;
- buffer尽可能给外表;
- 遍历内表(可以使用index优化)
Sort-Merge Join
Join的本意是找到两个表中符合条件的记录。sort merge join先对两个表进行排序,然后在使用游标分别遍历两个表。

merge阶段维护两个指针,它们先分别指向R表和S表的第一行数据,然后比较这两个指针所指向的两行数据的连接列字段的大小,之后如上图所示走向不同的分支。
这段伪代码其实少描述了一种情况:在某些时刻指针会有回溯操作。
总开销:sort + merge
缺点:但是这种策略存在退化的问题,和指针回溯的操作有关,极端情况就是要join的两列里所有字段的值都相等,这会退化成最原始的Nested Loop join。
使用场景:在要参与join运算的表都是已经排好序的情况下(或者是通过join key的索引来扫描表),merge join的效率是最高的,开销最低;如果我们期望join的结果是排好序的,那么merge join也非常合适,因为在这个算法内部实现里面已经完成了排序,在这种场景下使用别的join算法都还需要额外再执行一遍外排序。
Hash Join
在前面介绍index nested loop join时,是以B+树为索引来举例的,B+树点查询的时间复杂度是O(log N),随着其中存储的KV增多,点查询速度会变慢。
虽然B+树的好处是支持高效的区间查找,可以按照K递增/递减的顺序遍历叶子节点中的KV,但在index nested loop join场景下,我们要进行的是一次次的点查询,前后两次查询中的key大概率毫无关系。
与B+树索引相对的是哈希索引,不管哈希表里存储了多少KV,哈希索引的开销始终都是常熟量级O(1),点查询执行的飞快。Hash Join的策略是给outer table构建哈希索引,对inner table进行遍历。
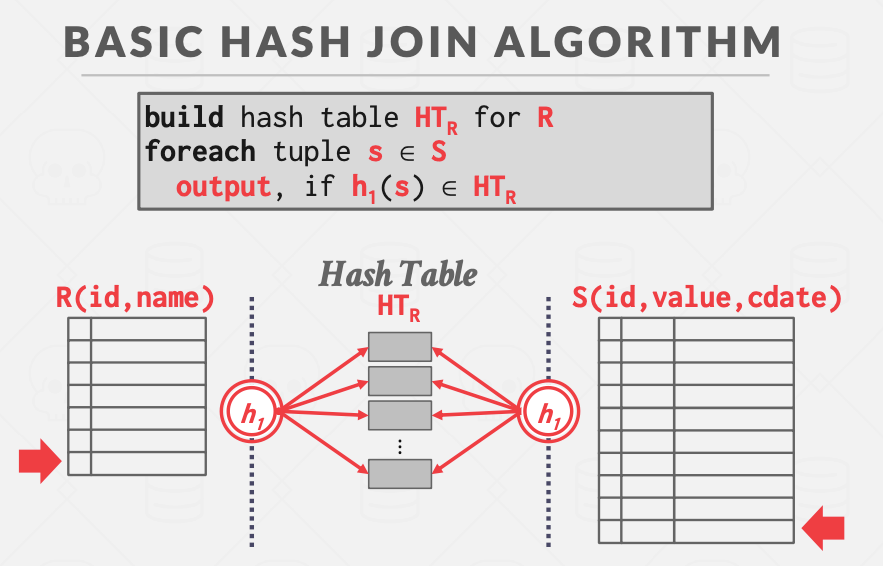
哈希表中每个KV中的Key是要join的连接列的字段,Value的选择也存在早物化/晚物化的差别。
原始的哈希join中,每次都使用inner table中一行的join key去哈希表里查询,但使用有些join key去查询的时候,根本没有对应的哈希表项,这种无效的查询增大了开销,我们不妨使用布隆过滤器,给outer table构建哈希表的时候顺便构建一个布隆过滤器,inner table在去哈希表中查询前,先去查布隆过滤器,判断本次查询在哈希表中能否找到相应的表项,如果能通过布隆过滤器断定哈希表里没有对应的表项,便可以确定这是一次无效的查询,于是让此次查询提前结束。
Grace Hash Join
如果给outer table构建的哈希表太大了(因为outer table太大),内存里放不下,那么我们就要把哈希表的部分内容驱逐到硬盘里。
做两套哈希表,也就是对前面的例子中的S表和R表都构建相应的哈希索引,并且使用相同的哈希函数。我们把哈希表存在硬盘里,查询索引时,把硬盘中两个表相对应的哈希桶都取出,之后我们对刚刚从硬盘里取出的两个哈希桶里的KV数据做nested loop join。
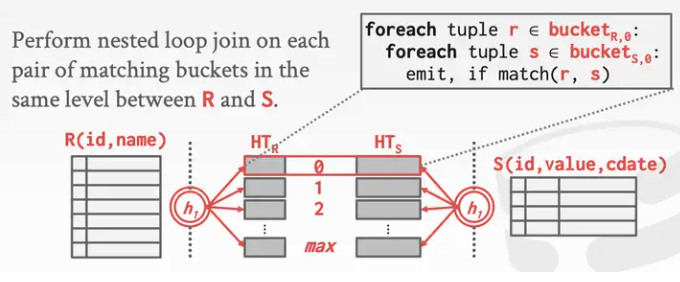
这个策略提出的基础是认为:虽然无法把整个哈希表放进内存里,但可以把哈希表的某个哈希桶放入内存,如果单个的哈希桶太大,也放不进内存,那该怎么办呢?如果使用哈希函数h1构建的哈希表里的哈希桶太大,那我们就把这个大的哈希桶存储硬盘,使用哈希函数h2,对这个哈希表再进行一次哈希操作来进行分区,递归地进行这个过程,直到切成足够小的块。
总结
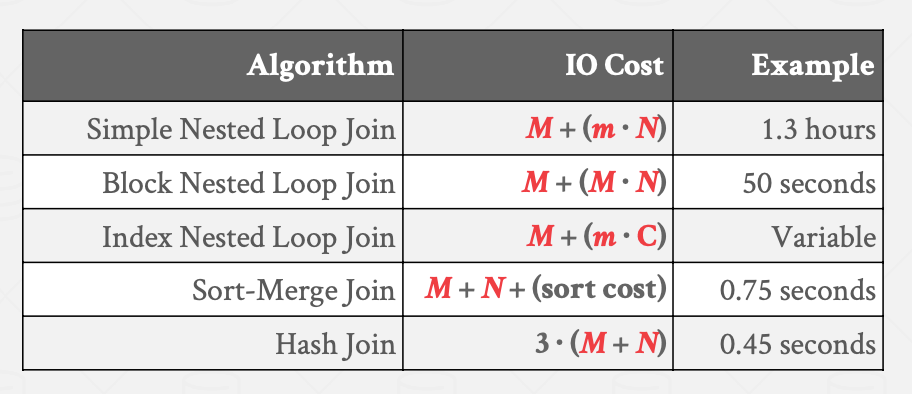
如果是面对OLAP型的负载,join两个大表,那么大多数情况下哈希join最为合适,但也有一些特例,如果数据是“倾斜的”,也就是说为其构建哈希表会导致严重的哈希碰撞,sort-merge join效率好的多,此外,如果要求join的输出结果必须有序,sort-merge join也是最优选择,DBMS的优化器会结合实际场景在sort-merge join和hash join之间做选择。
cmu15-445笔记七 表连接