cmu15-445笔记八 Sql执行
本节介绍了SQL的执行流程,首先有查询计划,接着是查询计划的执行方式,然后是单表的访问方法。最后介绍了修改性的SQL语句的注意点以及表达式求值的优化。
Query Plan

DBMS 将 SQL 语句转换为查询计划。查询计划中的运算符排列在树中。数据从这棵树的叶子流向根部。树中根节点的输出是查询的结果。
Processing Models
处理模型定义了系统执行查询计划的方式。不同的工作负载场景有不同的处理模型。
- 迭代模型
- 物化模型
- 向量模型/批模型
Iterator Model
迭代模型又称火山模型、流式模型。每个算子/操作符要实现一个Next()方法,每次调用它时操作符会返回一个tuple或者null。null表示tuple已经遍历完毕。
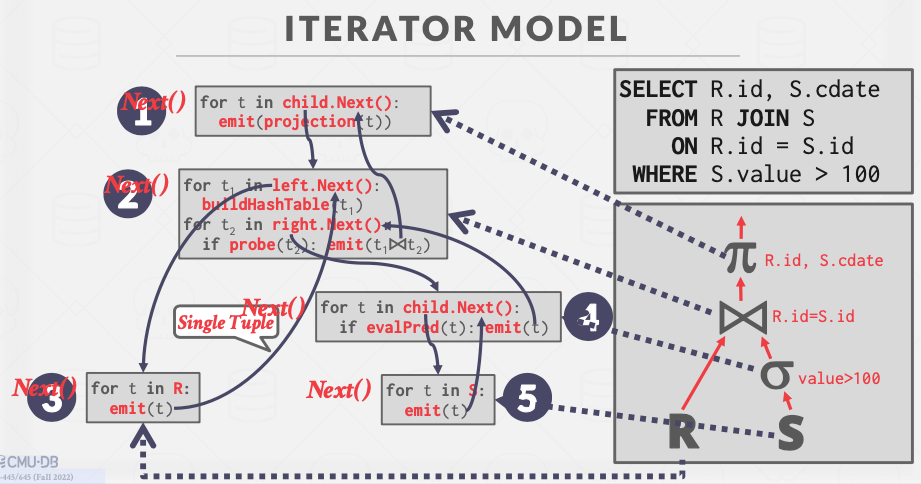
位于根节点的投影算子的实现方式就是循环地调用其子节点的Next()方法,然后将所有返回的tuple经过投影处理后输出。
Join算子执行方法就是哈希join,先循环地调用其左子节点的Next()函数,用所有返回的tuple(它们合起来就是outer table)去构建哈希表(此时等待join算子的Next函数返回的投影算子处于阻塞状态),之后循环地调用其右子节点(筛选算子)的Next方法,每次调用时,右子节点吐出一个tuple,然后拿着join算子拿着这个tuple的join key去刚刚构建的哈希表里查询,查看能否成功匹配,如果可以的话,那就返回一条join后的结果,即向其父算子(投影算子)吐一条数据。
火山模型便于实现对输出的控制,比如说SQL语句中有”limit 100”这样的关键字,限制只输出100条数据 ,在火山模型下我们只需先流式地输出100条,然后让顶端的算子停止输出。我们不需要额外控制最底层的table reader(也就是读表的算子),只需要在操作符树的顶端控制数据的出口。但火山模型在性能上也有一些问题,每一条数据的传输都依赖函数调用,虽然函数调用的开销远小于硬盘IO,但如果要上千万条这样大量的数据向上流动,函数调用的次数将非常多,这会降低性能。
Materialization Model
算子一次性读入全部要处理的数据,将得到的结果一次性地输出。
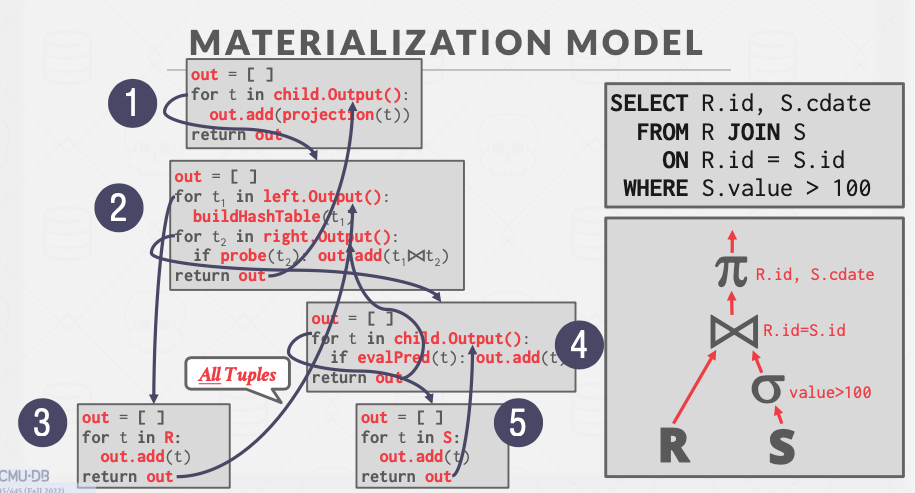
每个查询计划运算符都实现一个 Output 函数:
- 操作员一次处理其子级的所有元组。
- 此函数的返回结果是运算符将发出的所有元组。
当操作员 完成执行后,DBMS 永远不需要返回它来检索更多数据。
此方法更适合 OLTP 工作负载,因为查询通常一次只能访问少量元组。因此,用于检索元组的函数调用较少。具体化模型不适用于具有大型中间结果的 OLAP 查询,因为 DBMS 可能必须在运算符之间将这些结果溢出到磁盘。
Vectorized/Batch Model
火山模型每获取一条数据就要经过一系列的函数调用,物化模型每次函数调用可以获取很多数据,它们有各自的优点和缺点,向量化模型是这二者中和的产物,向量化模型中,每个算子也有Next函数,但它返回的不是一条数据,而是一批数据(tuple batch),这样可以减少函数调用的次数,从而降低开销。
这种模型对经常进行大数据分析的OLAP型数据库比较友好,既能做到向上层算子返回的数据量不是太大,又可以控制函数调用的次数与开销。
执行方向
Approach #1: Top-to-Bottom
- Start with the root and “pull” data from children to parents
- Tuples are always passed with function calls
Approach #2: Bottom-to-Top
- Start with leaf nodes and “push” data from children to parents
- Allows for tighter control of caches / registers in operator pipelines
DBMS计划执行/函数调用的方向分为两种,一种是让父算子调用子算子,自顶向下,另一种是子算子完成操作之后调用父算子,自底向上,但不论如何,数据流的方向始终是从操作符树的叶子节点流向根节点。
Access Methods
访问方法是 DBMS 访问存储单表中的数据的方式。
通常,有两种方法可以访问模型:通过顺序扫描从表或索引中读取数据。
Sequential Scan
顺序扫描运算符循环访问表中的每个页面,并从缓冲池中检索它。当扫描遍历每页上的所有元组时,它会评估谓词,以决定是否将元组发出给下一个运算符。
DBMS 维护一个内部光标,用于跟踪它检查的最后一页/插槽。
顺序表扫描几乎始终是 DBMS 执行查询的最低效率方法。有许多优化可用于帮助加快顺序扫描速度:
- Prefetching:提起加载下一页,避免IO的等待
- Buffer Pool Bypass:在local memory中进行顺序扫描的页加载,避免buffer pool的sequentail flooding
- Parallelization:多线程并行顺序加载
- Late Materialization:晚物化,DBMS 可以延迟将元组拼接在一起,直到查询计划的上半部分。这允许每个操作员将所需的最少信息传递给下一个操作员 运算符(例如,记录 ID,与列中记录的偏移量)。
- Heap clustering:
Data Skipping类策略
- Zone Maps:预先计算页面中每个元组属性的聚合。 然后,DBMS 可以通过首先检查Zone Map来决定是否需要访问页面。比如事先统计记录最大值为400,那么val > 600的查询语句就不必执行了。
- Approximate Queries:对整个样本的子集执行查询以生成近似估计。
Index Scan
利用索引查询。
There are many factors involved in the DBMSs’ index selection process, including:
- What attributes the index contains
- What attributes the query references
- The attribute’s value domains
- Predicate composition
- Whether the index has unique or non-unique keys
索引的选择有很多的策略与trade-off,在Lec13查询优化具体讲述。
Multi-Index Scan
对查询使用多个索引时,DBMS使用每个匹配的索引计算记录 ID 集,根据查询的谓词组合这些记录 ID 集,并检索记录并应用可能保留的任何谓词。DBMS 可以使用位图、哈希表或 Bloom 筛选器通过集交集计算记录 ID。
Modification Queries
修改性的Sql(INSERT、UPDATE、DELETE)需要检查约束与维护索引。
- For UPDATE/DELETE, child operators pass Record IDs for target tuples and must keep track of previously seen tuples.
UPDATE/DELTE查询语句执行时,子算子会把要处理的tuple的id传递给上层负责完成更新/删除操作的父算子,然后父算子通过id找到相应的tuple,然后执行对应的操作。此外,负责更新/删除的算子必须要记住在执行本次的查询语句时操作了哪些数据。
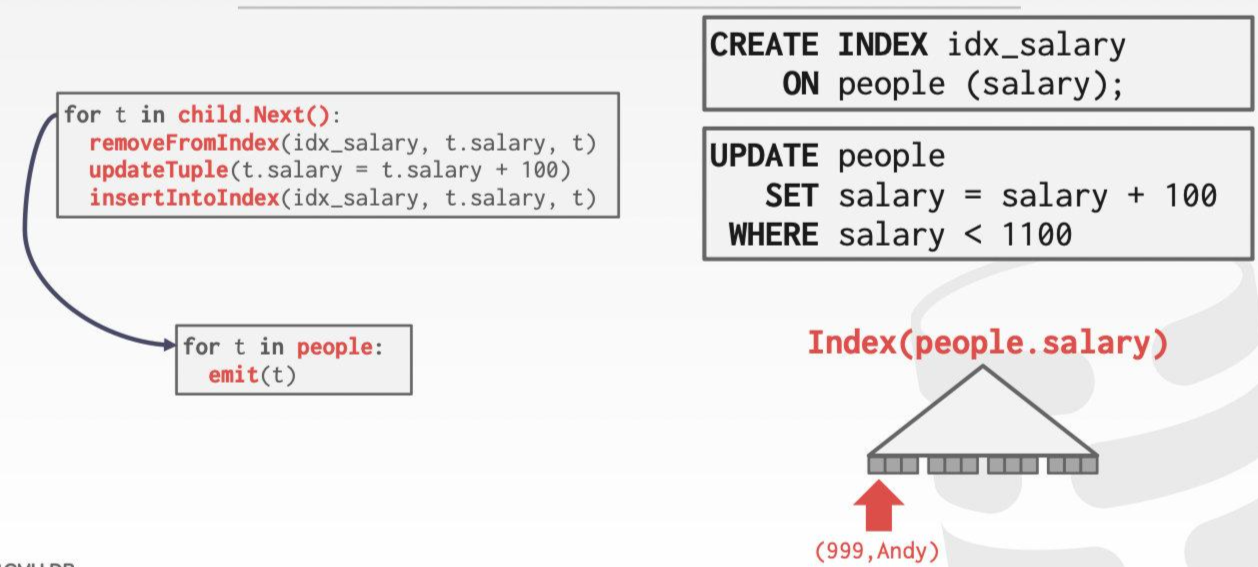
就比如图中update的执行,由下层算子传来要执行的记录ID。假设salary=900的这条记录先被删除,然后执行加100变成1000,最后被插入索引中。但是1000仍然小于1100,这条记录会被再次扫描到,update应该记住它看过这条记录,跳过执行。
There are two implementation choices on how to handle INSERT operators:
- Choice #1: Materialize tuples inside of the operator.
- Choice #2: Operator inserts any tuple passed in from child operators.
插入语句根据是否物化有两种选择:
一种是它不管物化,只管插入子操作符传递来的完整tuple,并维护索引;
第二种是它来物化,并维护索引。
Expression Evaluation

解析SQL语句构建条件树,但是一种情况:
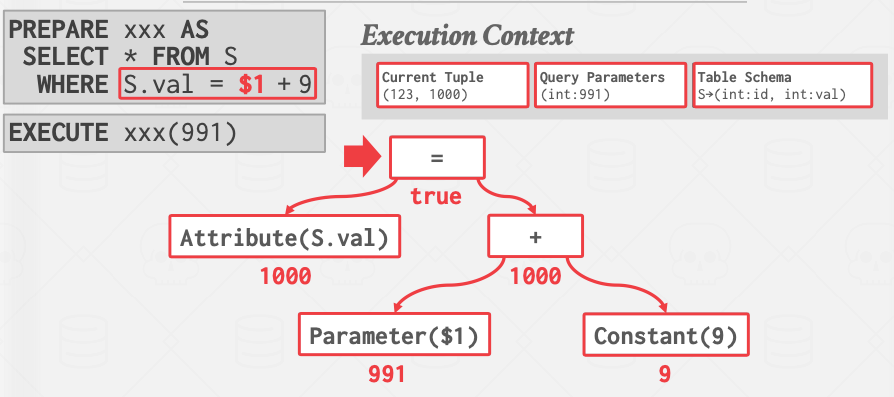
加法会被多次计算(对于S表的每个Tuple都会计算一遍),这种情况下存在对应的优化策略:在执行SQL语句的查询计划前,先把语句中的常数提前算出来。
这和Java的高级技术JIT(即时编译技术)有相似之处,和JIT(Just in Time)对应的是AOT(Ahead of time)
在Java的JIT技术中,JVM虚拟机会将被频繁执行的热点代码段(比如说JVM能检测出来有些循环被执行了好多好多次,那这就可以被标记为热点代码段)中的字节码转化成二进制代码,下次再运行到这个热点代码段的时候就直接运行二进制代码,不经过中间那层虚拟机,从而提升了效率
JIT技术是在代码被执行的时候动态地判断出哪段代码是频繁被执行的,而AOT技术是在代码被执行之前就进行这样的判断。
cmu15-445笔记八 Sql执行