cmu15-445笔记九 查询优化
本节课主要关于查询优化,首先介绍了Sql语句的执行过程,然后就是两种优化方式:基于规则的优化和基于代价的优化。
SQL语句是声明式的,只说明要什么,没说明怎么做。DBMS的优化器将优化SQL的执行过程。有如下两种方式:
- Heuristics / Rules,启发式/基于规则
- Cost-based Search,基于代价
启发式方法重写查询语句,以移除低效部分。这种方法有可能需要查阅目录数据结构,但是不需要数据本身。基于代价的方法估计每种执行计划的代价,然后选择代价最低的执行。
逻辑计划是关系代数级别的,物理计划包括了各个算子的具体执行方式,即物理算子(比如说join算子是用nested-loop join还是merge/hash join来完成)。
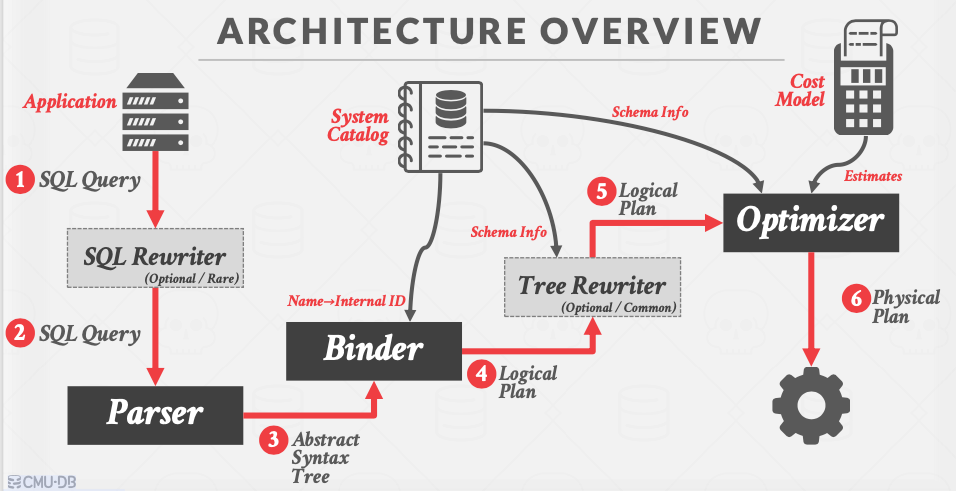
用户的业务会发出SQL查询语句,少部分DBMS会有SQL Rewriter这个组件,对字符串形式的SQL语句进行文本上的预处理(在字符串层面上做简单的优化)。
之后SQL查询语句进入Parser,Parser会把SQL语句变成抽象语法树,抽象语法树当中会涉及到库/表/列的名称,这些名称要和数据库系统元数据里面的库/表/列/索引的ID对应上,因此会有Binder(即连接器)把SQL抽象语法树中用户写的表名/列名/索引名转化成数据库内部使用的ID,并且这个步骤中会有检查:如果用户请求了一个不存在的表,那么就会直接报错。
经Binder处理过之后的抽象语法树会被送入Tree Rewriter,这个组件大多数DBMS都有,它会输出一个标准的执行计划(比如说SQL语句里有一堆join操作,一开始的抽象语法树中的join的排布可能是乱的,Tree Rewriter会把所有的join排列成左深树,这个步骤也叫正则化),这个过程中也会查一些系统的元数据,Tree Rewriter输出的原始的逻辑计划是优化器进行优化的源头。
之后基于规则的优化器(RBO, rule based optimizer)会查询一些系统的元数据来做优化,基于代价的优化器(CBO, cost based optimizer)不仅会查询元数据,还会查询相关的代价模型,根据代价模型去做优化,最后优化器会生成物理计划,被实际使用。
Relational Algebra Equivalences
关系代数表达式的等价,如果两个关系代数表达式所输出的结果集是一样的,那么它们等价。
比如说谓词下推:
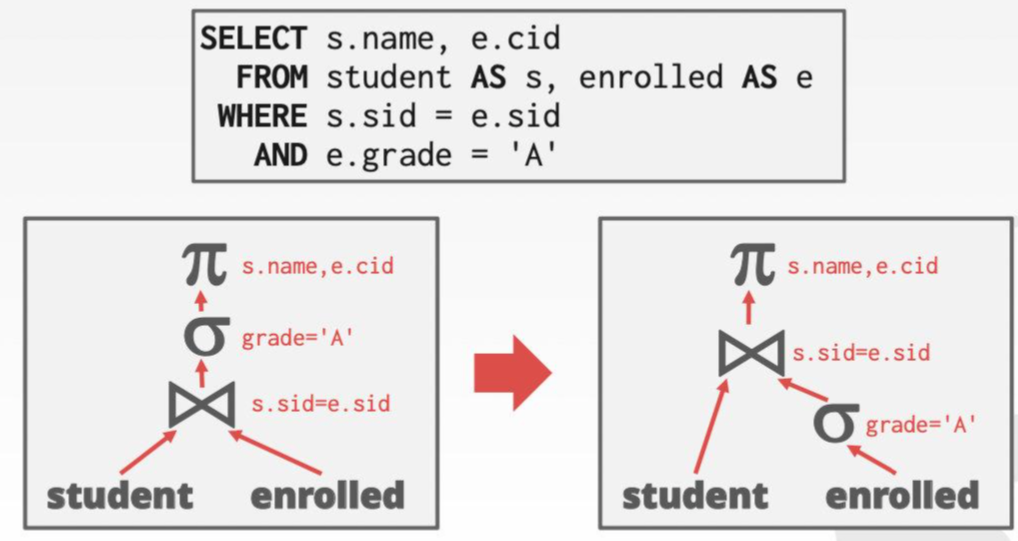

join算子具有结合率、交换率,这会被用于查询优化

投影算子也可以有一些优化点:
投影下推,从而把无关的attribute对应的列删掉,让tuple和中间结果更小;
project out all attributes except the ones requested or required(e.g. joining keys)
这些查询优化策略对于列存储的数据库不重要,因为列存储的数据库永远都是最后进行对tuple的物化。
Logical Query Optimization
Split Conjunctive Predicates分开连接谓词
将连在一起的谓词分开。图片上来看,sql语句并未改变,只不过执行时,将连续的谓词判断分为若干个判断,虽然多了若干个判断,但是方便优化器优化语句。
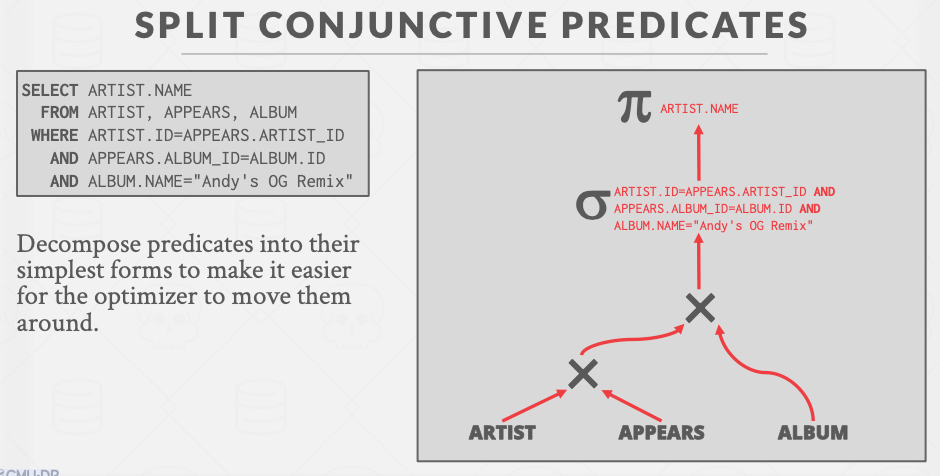
Decompose predicates into their simplest forms to make it easier for the optimizer to move them around.
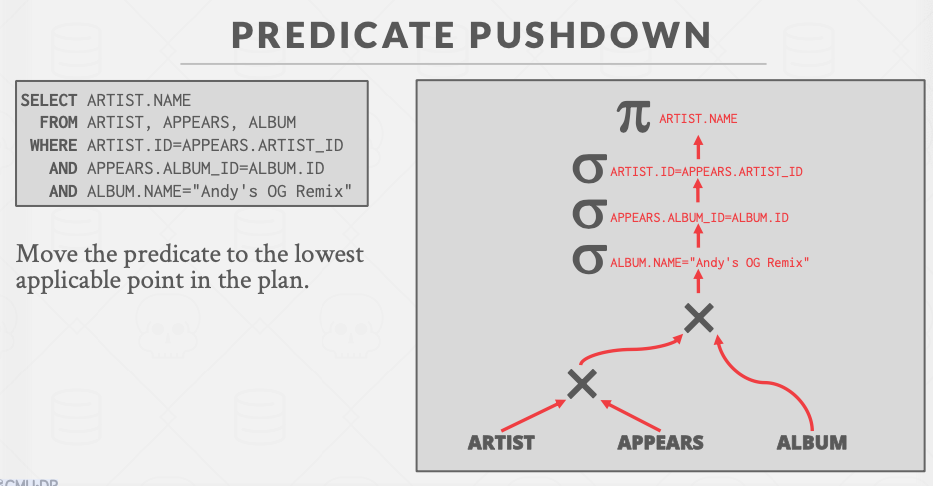
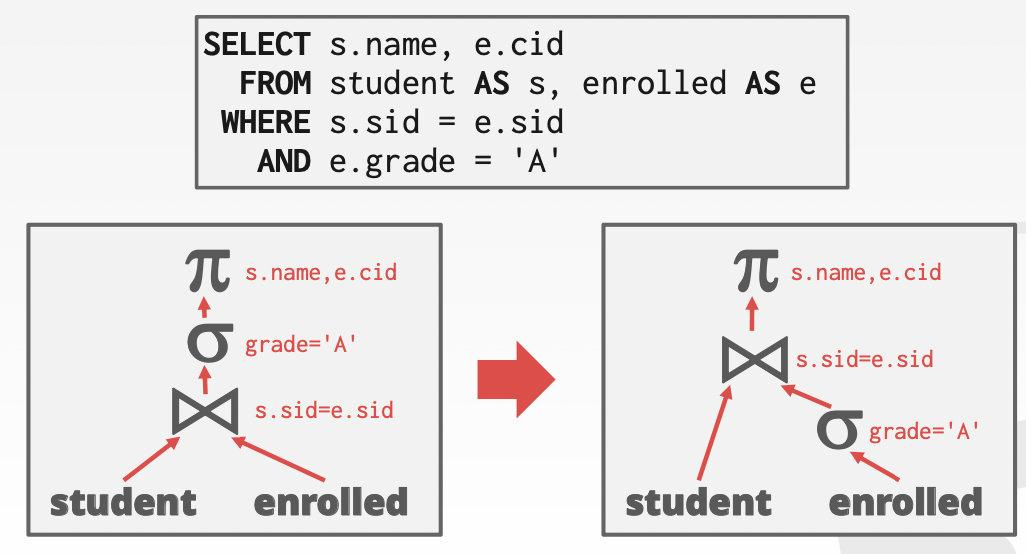
Predicate Pushdown谓词下推
谓词下推,把谓词尽量往下推,推到越接近读表越好,这便可以提前筛掉一部分的数据,减少上层算子的负担。
从图片上可以看到,enrolled表通过谓词下推后,减少了筛选上来的数据,进而减轻了连接时的数据代价。
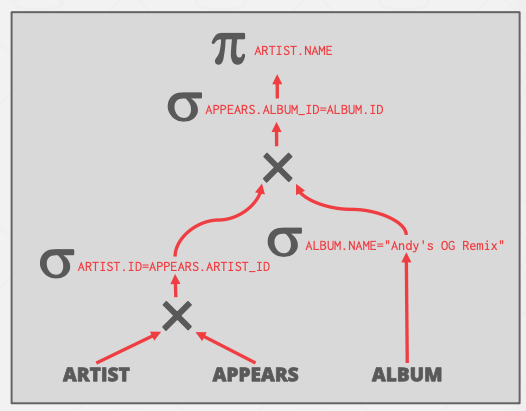
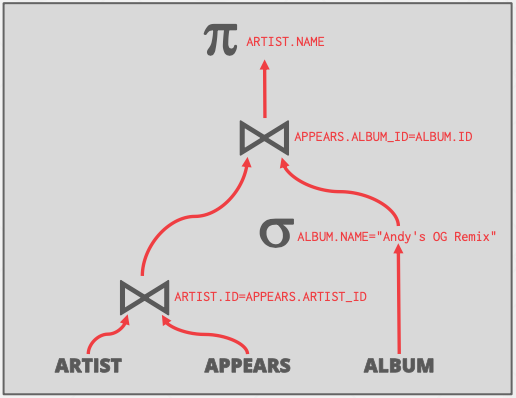
Replace Cartesian Products with Joins取代笛卡尔积
根据相应的谓词,把笛卡尔积变成join。笛卡尔积和谓词合为一个等价的join连接。比如:
如下两图所示,原本artist和appears需要先做笛卡尔积再进行谓词筛选,但是这个操作可以转化为连接。因为DBMS对于Join有多种优化方式(Loop join、sort-merge join和hash join等)。
关于join还有优化手段:应该用“小表”作为驱动表,“大表”作为被驱动表。因为nest loop join算法,把缓存池尽可能多地给outer table使用,从而减少遍历inner table表的次数,从而减少开销,毕竟给inner table用的缓存池再大,在遍历inner table时,都会面临缓存重刷的问题。
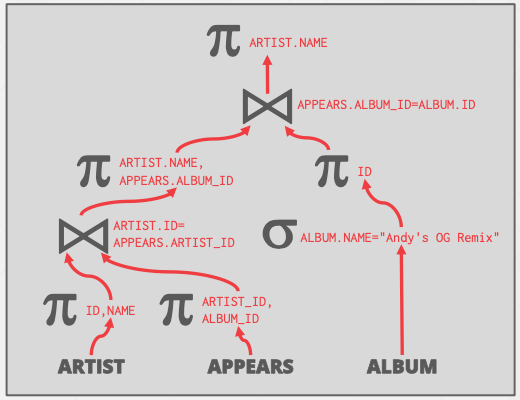
Projection Pushdown投影下推
执行过程中先执行投影算子,从而把无关的attribute对应的列删掉,让tuple和中间结果更小
Nested Queries 嵌套查询优化
SQL语句中经常会有一些嵌套的子查询,DBMS一般会用如下两大手段去优化它:
- 重写语句,取消嵌套或者扁平化
- 分解嵌套查询并将结果存储到临时表中

原始的SQL语句里的谓词既涉及到了外层的主查询,也涉及到了内层的子查询,可以发现:实际上它想做的就是join,那不妨就直接进行两个表的join,写成上图下方的形式。这样的话接下来优化器只需优化这一个SQL语句,因此也更容易生成比较高效的物理执行计划。
在一些复杂的查询当中,可能不太容易将内部的子查询和外部的主查询rewrite成一个查询,那么DBMS可以将子查询分离出来,先把子查询做完,把结果存放在一个临时的表里面,然后把这个临时的表带到主查询中。这里的解耦是指:不让子查询嵌套在主查询里面,而是把它拿出来,提前执行它。
Expression Rewriting 表达式重写
DBMS会通过人为设置的一些规则把查询语句的表达式(尤其是谓词表达式)重写,让它变得更加精简、高效。
- 去除无效谓词
- 合并谓词

Cost Estimations
基于代价的优化器会根据当前数据库的状态估算出查询计划的代价。
- 物理代价:磁盘IO、CPU周期、缓存失效
- 逻辑代价:算子开销
- 算法开销:细粒度估计单个算子的开销
为了估算查询成本,DBMS 在其内部目录中维护有关表、属性和索引的内部统计信息。不同的系统以不同的方式维护这些统计信息。大多数系统试图通过维护内部统计表来避免动态计算。然后,这些内部表可能会在后台更新。
Selection Statistics
对于每张表R,DBMS追踪表中tuple的数量$N_R$以及每个attribute A的distinct value的数量$V(A,R)$。selection cardinality选择基数由 $SC(A, R)=\frac{N_R}{V(N,R)} $ 计算得出。
一个attribute A的选择率selectivity由SC的倒数给出。形象的说,就是“谓词能选上来百分之多少的数据” 。

可以察觉到:选择率和数据出现的概率是很相似的概念。多谓词情况下,可以使用计算概率的方法,根据每个谓词的选择率计算总体的选择率。
前面所讨论的都是和select语句相关的基数的计算,对于带有join操作的语句来说,两个表join得到的结果集的规模该如何计算呢?
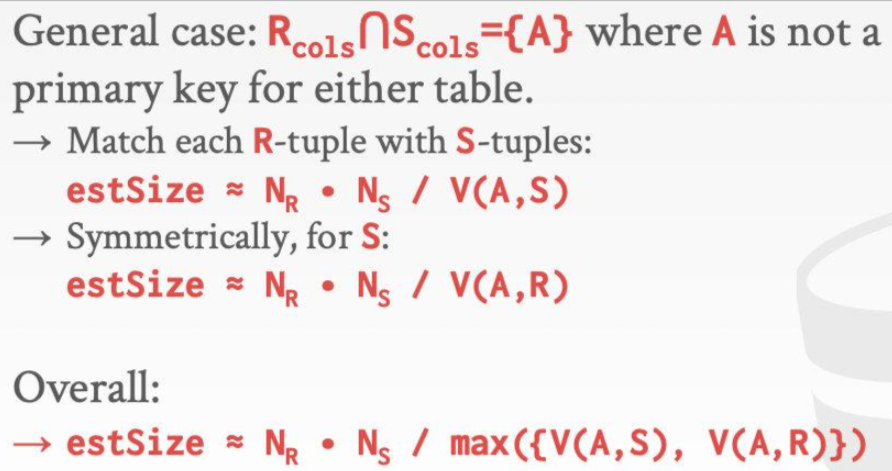
在计算选择基数的过程中,遵循了几个假设:
- 数据一致性
- 谓词独立性:The predicates on attributes are independent.
- 包括规则:连接键的域重叠,使得内部关系中的每个键将也存在于外表中。
实际应用场景并不会这么理想化,比如说:关于不同的attribute的不同谓词之间往往不是完全独立的。
Histograms
对于不均匀分布/attribute之间不独立的数据,可以利用直方图记录信息。
- 等宽直方图
- 等深直方图

Sampling
还有一种较为简单粗暴的统计方式,sampling-采样,这种策略的思想是:如果表特别大的话,我们不妨从其中随机选择一些tuple然后构成一个小表,把这个小表作为完整表的一个代表,然后下一步转而分析这个小表,将得出的统计信息用于对完整表的查询代价分析。
DBMS 可以使用采样将谓词应用于具有类似分布的表的较小副本(参见图 13)。每当基础表的更改量超过某个阈值(例如,元组的 10%)时,DBMS 就会更新样本。
sampling的问题:额外维护小表(比如说采样时提取出来的tuple如果在完整的表里被删掉了,那么我们也要对小表做相应的改动),而且每个SQL语句在完整的表上面运行之前,还要先在小表上面跑一遍以获取统计信息,这毫无疑问会带来一定的开销。
sampling的好处就是基于真实的数据去做估计。
Plan Enumeration 计划列举
基于前面介绍的各种策略,我们可以粗略地去估计谓词的选择率(selectivity),在知道了谓词的选择率之后,就可以计算出有多少数据被送入了每个算子,知道了这个数据之后就可以计算每个算子的开销,进而得出整个执行计划的开销代价,知道了计划的开销,那么优化器就可以进入下一阶段:计划列举。
对于那些仅涉及单表的查询计划,优化器做的事情非常简单,可以仅仅启发式地依据规则对逻辑计划rewrite,比如说确定访问数据的最佳方式(相关的规则可以是:“若存在这个字段的索引,那么就走索引”),而不用去量化分析查询计划的开销。只涉及单表的OLTP就可以作简单的优化:

多表查询优化
对于那些涉及到多个表的查询,不可避免地会有表与表之间的join,而inner-join运算既符合交换律,又符合结合律,因此4~5个表做join时计划列举的空间极大(join操作的顺序,join运算符左边和右边各是哪个表,这些都有极大的搜索空间,因此我们要用一些手段去降低这个搜索空间)。
IBM的System R只考虑左深树对应的join排列,即join的左子树也是一个join操作(如下图最左侧所示,因此下图的右边两个join排列都会被pass掉)。
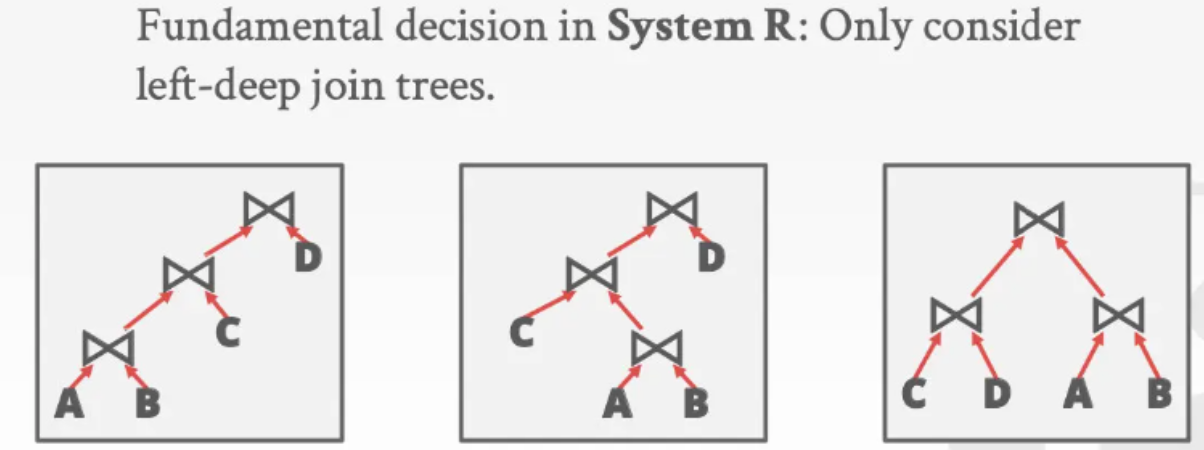
而且左深树带来了意想不到的好处:如果计划的执行模型(process model)是火山模型,那么就可以做到(假设B~D表的哈希表都做好了并且进行的是hash join):A表和B表做join得到一个tuple,吐给上层的join算子,然后上层的join算子拿这个tuple和C表做join,之后再吐给上层,和D表做join,这便实现了几乎完美的流式操作,极大程度上使中间结果集更小。
cmu15-445笔记九 查询优化