cmu15-445笔记十二 并发控制:乐观控制
这节课主要介绍了乐观并发控制:时间戳顺序并发控制、OCC协议。最后还介绍了幻相,幻相引起的原因、解决方式。
二阶段锁协议属于一种悲观的并发控制方法:总是假设未来可能出现数据竞争,因此总是给共享的对象上锁。
也存在一些乐观的并发控制方法,比如说基于时间戳顺序的并发控制(Timestamp Ordering),它的基本原理是,给每个事务一个时间戳,根据事务的时间戳来决定它们的顺序以及出现冲突操作时该如何处理。
时间戳赋予
- 可以通过系统时钟,但有些时候这会出问题,因为系统时钟不是完全精确的,它会每隔一段时间和服务器通信,进行同步,因此在同步的时候就会出现“时间突然被调慢了一分钟”这种情况,这就可能导致系统时间校准之前到达的事务和系统时间校准的之后到达的事务的时间戳顺序发生了混乱
- 由于系统时钟并不完全可靠,因此在很多单节点的数据库中使用Logical Counter(逻辑计数器),第一个到达的事务标记为1号,第二个到达的标记为2号…,通过简单的计数完成时间戳的排列,从而避免系统时钟的跳变
- 对于分布式系统来说,Logical Counter很难校准(因为在各个节点之后依赖于网络的通讯比较慢,如果A节点和B节点相距很远的话,有可能某一时刻到达A节点的事务和到达B节点的事务对应同一个counter,因为它们之间不会立即获取到对方的counter更新)。因此就有了系统时钟和逻辑计数器混合使用的时间戳确定办法,具体的实现方法在本课程中并未提及
Basic Timestamp Ordering(T/O) Protocol
基础的T/O协议中,事务在读/写对象的时候是不加锁的
数据库中的所有对象(一般就是指tuple这种对象)上面要附带两个时间戳,一个读时间戳(上一次读这个对象的事务的时间戳/事务号),一个写时间戳(上一次写这个对象的事务的时间戳/事务号)。
每次读/写数据的时候都要检查时间戳(比较当前事务的时间戳和操作过当前正在进行读/写的对象的事务的时间戳),要求是“不能操作未来的数据”。

基于时间戳协议的读流程:比较事务的时间戳和对象写时间戳,如果当前时间戳小于上次写的时间戳,则放弃事务进行。否则读对象,然后更新读时间戳,最后拷贝一份(可重复读)。

基于时间戳协议的写流程:比较事务的时间戳与对象的读时间戳和写时间戳,需要当前时间戳均大于二者。然后更新写时间戳,最后拷贝一份。
托马斯写规则
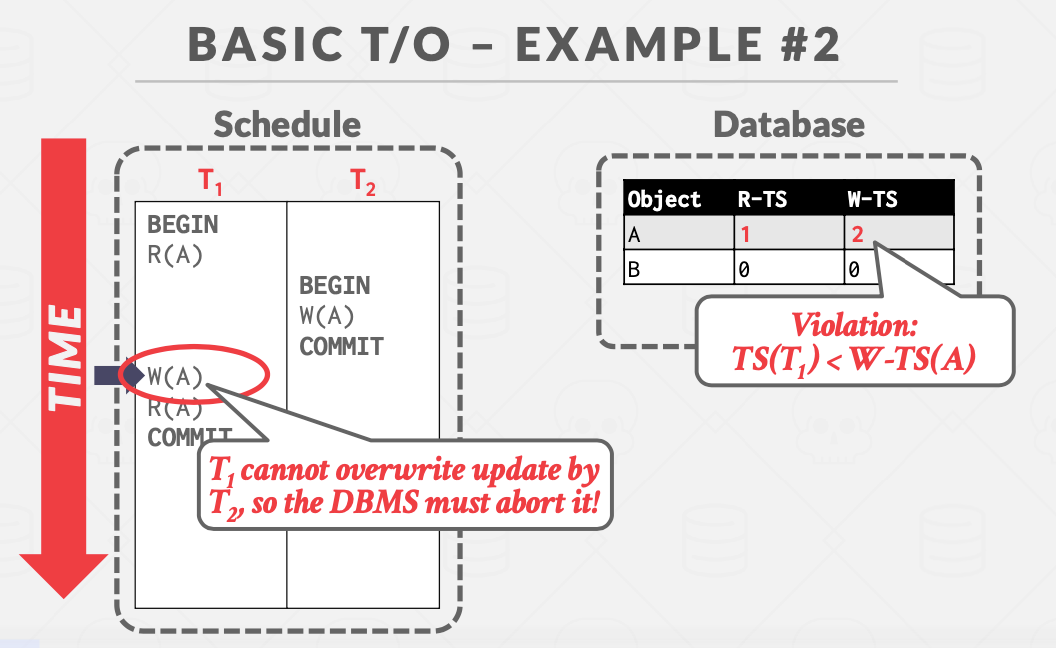
在基于时间戳的写流程中,如果事务的时间戳小于对象写时间戳,事务被迫abort。但是,这个过程表明,有未来的事务正在写这个共享对象。当前事务的写会被覆盖,那么其实也没事。

TO 缺点
如果不考虑托马斯写规则带来的优化,基础T/O协议会生成冲突可串行化的执行调度,它的优点是没有采用锁,因此不可能构成死锁。
长事务饥饿问题:较长的事务(比如说有几百条SQL语句)有可能会饥饿,因为很有可能它执行了一段时间之后,想要访问的数据都是被比它更“年轻”的事物修改过的,那它只能abort,重启之后又迎来同样的结局。
性能问题:事务在读任何数据的时候都要往本地拷贝一份同时还可能更新时间戳
Optimistic Concurrency Control
OCC是基于事务之间发生冲突的概率低,并且事务都比较短这个假设提出的优化策略,它希望通过无锁化来对事务之间无冲突的场景做出优化。
基本策略
每个事务都有一个自己的工作区,任何读对象都会拷贝到这个工作区,对对象的更改也在这个工作区。
等到事务即将commit的时候,DBMS会将要提交的数据更新和其他事务要提交的更新进行比较,如果它们之间没有冲突的话,DBMS会一次性地把事务所做的所有更新都提交,如果出现了冲突,那么事务会abort。

三个阶段:
读阶段
这个阶段之所以称为读阶段,是对于数据库来说的它是一直只被读的。在OCC策略下,即便是写语句,也是读数据库到工作区进行更改,所有写操作在事务完成时才进行。
验证阶段
事务执行完了准备提交时,把它完成的数据更新和其他事务相比较。如果校验通过,那么就转至下一个阶段,否则abort并重启事务。
Checks other txns for RW and WW conflicts and ensure that conflicts are in one direction (e.g., older→younger).
写阶段
把事务本地所记录的更新提交到数据库中。
实现OCC的DBMS一般会在写阶段锁全表,除了当前事务以外没有其他线程可以修改数据库,也就不能多个事务并发地写,虽然这牺牲了并发性,但由于前面已经准备好了要写的数据,所以写操作的时间并不长,因此开销可以接受。
验证阶段
(1)后向校验
与已经发生过的事务校验
(2)前向校验
即向未来的事务校验,与当前正在进行的事务进行对比。
每个事务的时间戳在校验开始时赋予。假设当前$TS(T_i)<TS(T_j)$,那么必须满足以下条件:
Ti completes all three phases before Tj begins its execution. 即本身就是可串行的,Ti在Tj开始前就结束了。
Ti在Tj的写阶段开始前就结束了,并且Ti的写集合与Tj的读集合交集为空(Ti修改过的对象Tj没读过)。
Ti先于Tj完成读阶段,Ti修改过的对象Tj没读过,Ti修改过的对象Tj没修改过。
缺点
性能问题,它还是会和基础T/O一样要求事务把要读写的数据拷贝到本地
校验这个步骤的逻辑很复杂,容易构成性能瓶颈
写阶段是串行的,不能并发,也容易成为瓶颈
OCC中如果校验阶段失败的话,那么前面所做的全部操作就都会前功尽弃,不像二阶段锁有死锁检测,这样可以在事务进行到一半的时候abort
幻觉现象
到现在为止我们讨论的事务都是基于读写操作,如果引入删除操作,那么就会发生新的问题。
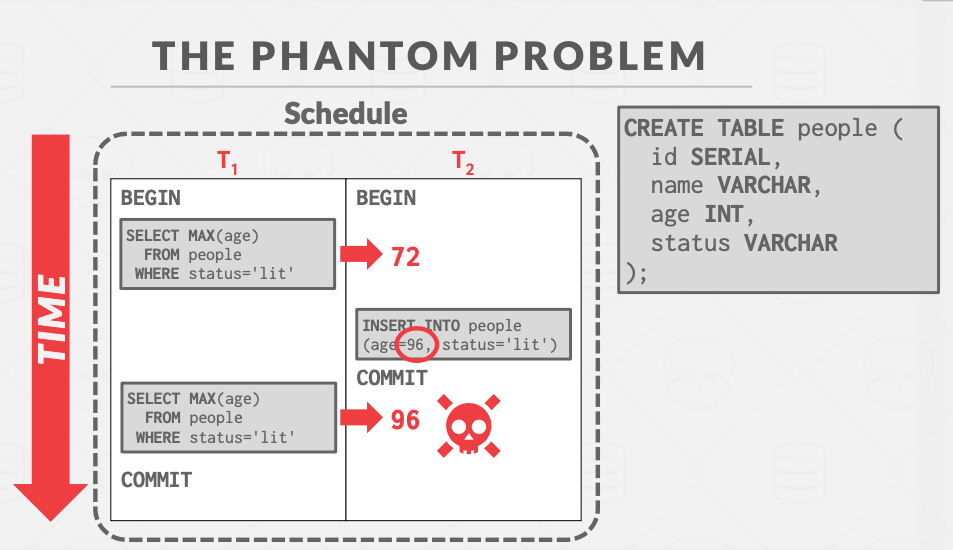
如果一个事务开启期间,另外一个事务插入了一条数据,那么当前事务读取的count/max/min就会前后不一致。
为什么会发生?因为前面所讨论的事务并发控制(二阶段锁和OCC)只对存在的数据有用,插入时的新数据并不存在于数据库中。
Re-Execute Scans
记录下来事务所有可能出现幻读的地方(像查最大值,平均值,最小值这些涉及到范围扫描的操作),为了防止察觉不到有其他事务在扫描完成后再向表里插入新数据,在事务提交之前会再执行一遍前面所记录的所有扫描。
Example: Run the scan for an UPDATE query but do not modify matching tuples. 比如说重新执行一遍更新语句,但不真正执行更新,只核对扫描的数据条目。
Predicate Locking
谓词锁。
对于含有where clause的SQL语句:给select语句对应的谓词加共享锁,给update/insert/delete语句对应的谓词加独占锁。
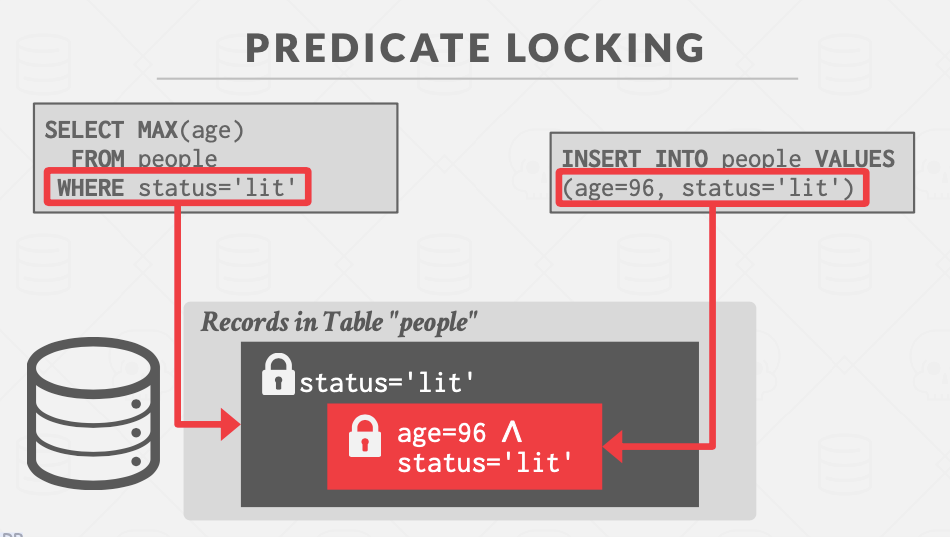
Never implemented in any system except for HyPer (precision locking).
Index Locking
基于索引的锁。
如果对谓词里的attribute已经构建了索引的话,那么DBMS可以给相关的索引页上锁。如果没有构建相关的索引,就使用表锁这种宽范围的锁。
基于索引的锁有多种模式:
(1)Key-Value Lock
锁住索引中的单一键值,如果键不存在则需要虚拟键。

(2)Gap Locks
间隙锁,锁住当前key到下一个key的间隙。

(3)Key-Range locks
范围锁,锁住一个范围内的键值。对于无穷大等键需要虚拟键。

没有索引时
If there is no suitable index, then the txn must obtain:
→ A lock on every page in the table to prevent a record’s status=’lit’ from being changed to lit.
→ The lock for the table itself to prevent records with status=’lit’ from being added or deleted.
锁住条件出现的每一个页面,避免插入或删除。
弱隔离级别
前面从2PL到T/O这些策略都是为了实现串行化这样一个最高的事务隔离级别,实际的业务场景里有些业务可以忍受非串行化的执行调度,而且非串行化时性能会更好,因此也存在一些比串行化更弱的隔离级别。
更低的隔离级别下事务之间会互相暴露,这也会引发一些问题:
- 脏读(当前事务读的数据是其他事务修改过的但这个修改还没被提交)
- 不可重复读(前后两次读同一个对象得到的数据不同,因为被其他事务修改过了)
- 幻读(前后两次读同一个谓词下的数据集合,读到的数据规模不一样)
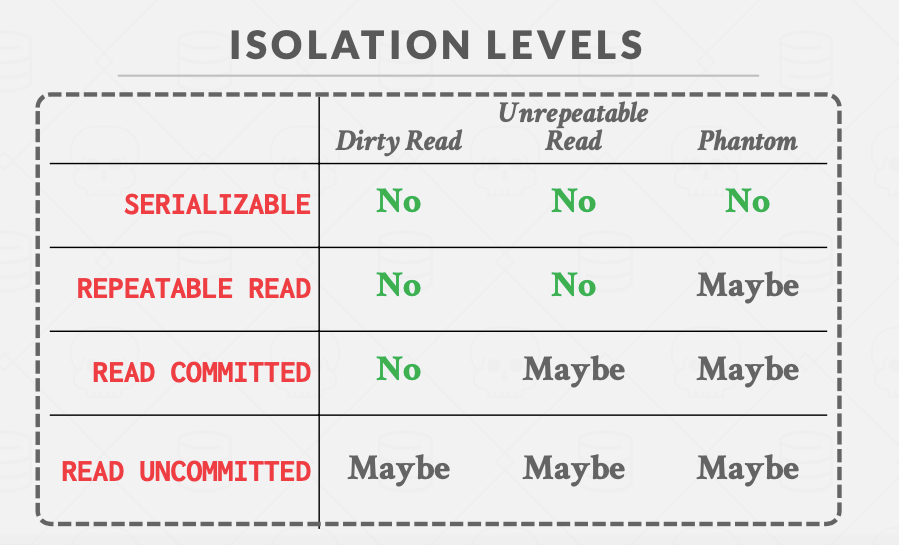
各个隔离级别的实现方法:
SERIALIZABLE: Obtain all locks first; plus index locks, plus strict 2PL.
REPEATABLE READS: Same as above, but no index locks.
READ COMMITTED: Same as above, but S locks are released immediately.
READ UNCOMMITTED: Same as above but allows dirty reads (no S locks).
cmu15-445笔记十二 并发控制:乐观控制