cmu15-445笔记十三 MVCC
这节课主要介绍了多版本并发控制。
多版本并发控制基本思想
DBMS保持一个逻辑对象的多个物理版本:
- 当事务写一个对象时,事务创建一个新版本
- 当事务读一个对象时,事务读创建时最新的版本
MVCC解决的问题/存在的原因:
2PL协议中,一个事务更新一个对象到它提交的期间,其他的事务均无法读取对象(即其他读取这个对象的事物都阻塞在这里)。
而MVCC的基础思想是,留下数据的历史版本,这样其他的事务可以读历史版本而不是被阻塞。只读的事务就可以在无锁的情况下读它所需要的那个版本的一致性快照,不受数据库动态变化的影响。
WRITE SKEW ANOMALY 写偏斜
在快照隔离的基础下,每个事务看到的都是它开始的一致性快照。
假设当前有一黑一杯两个棋子,事务1是将所有白棋变成黑棋,事务2是将所有黑棋变为白棋。如果仅使用快照隔离,那么这两个事务最终运行结果是一黑一白两个棋子(因为这两个事务恰好各自更新了一颗棋子)。但是在可串行化的语义下,运行结果应该是全黑或者全白。
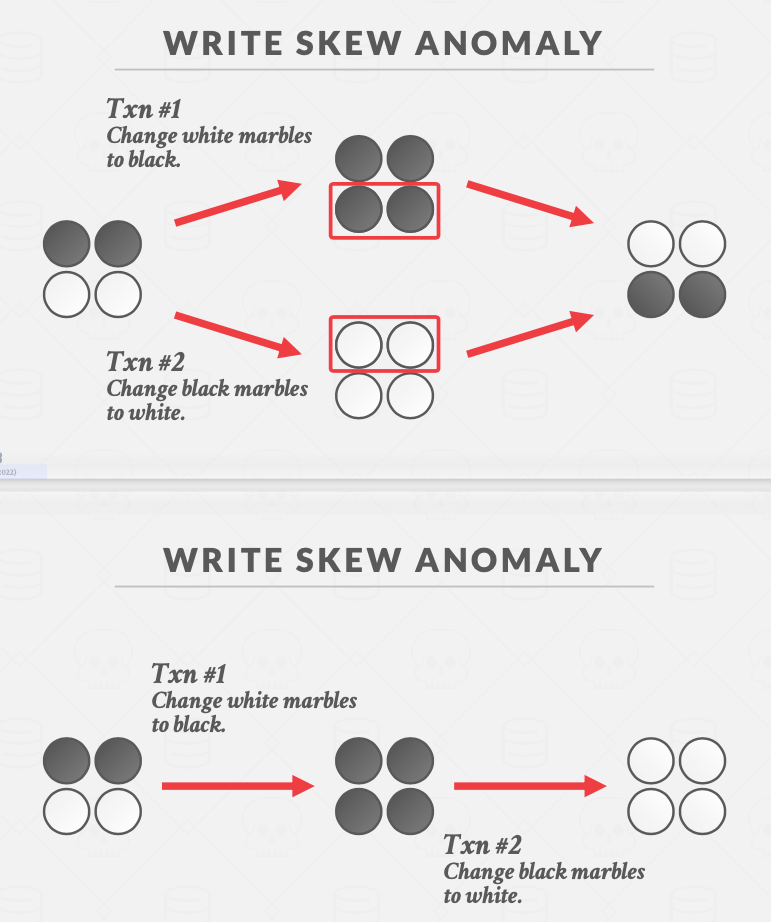
写偏斜的原因是:一个事务读出的数据作为写入的依据,而在提交前,这个读出的数据被其他事物改变。
让我们重复一下快照隔离的效果是:
一个事务读到的数据都来自于数据库某同一个时刻(时刻甲)的状态,然后所有写都发生在之后的某同一个时刻(时刻乙)。
这里的矛盾的矛盾就清楚了:
时刻甲时数据有个状态,等到了时刻乙,数据的状态可能不一样了。根据时刻甲的状态作出写的决定,这个决定到时刻乙真正写时,就未必适用了。
有点刻舟求剑的味道。
因此只依靠MVCC是不能达到调度的串行化,因此MVCC需要结合其他并发控制手段。
设计MVCC的选择
并发控制协议
版本存储
垃圾回收
索引管理
删除管理
MVCC并发控制
只使用MVCC无法做到serializable的隔离级别,因此会和如下的其他一些协议结合在一起:
- 基于时间戳:事务被赋予时间戳,然后决定串行顺序
- 乐观控制:三阶段协议,每个事务都有一个私有工作区
- 两阶段锁协议
版本存储
DBMS可以用tuple对象所包含的指针,建立一个包含各个版本的链表,因此DBMS可以在这个链表上去寻找各个版本,如果对表构建了B+树之类的索引,那么索引最后指向的是版本链表的头节点。
简单追加 append only storage
新版本的tuple被追加到表中,一个logical tuple的多个版本通过链表被连起来。
简单追加也有两种思路:
- oldest to newest 在链表末尾追加新版本
- newest to oldest 在链表头头结点插入新版本
如果把新的版本放在链表的末尾,那么经过索引查到的是最老的版本。也就是说,这么做的话,追加新版本的时候开销小,但想要读取快照,即执行查询时搜索对应版本的时候开销会大。
反之,如果把新的版本放在链表的头部,那么执行查询,搜索相应版本的时候效率会高,但追加新版本时维护链表的工作量大,因为要更新索引结构中的指针。
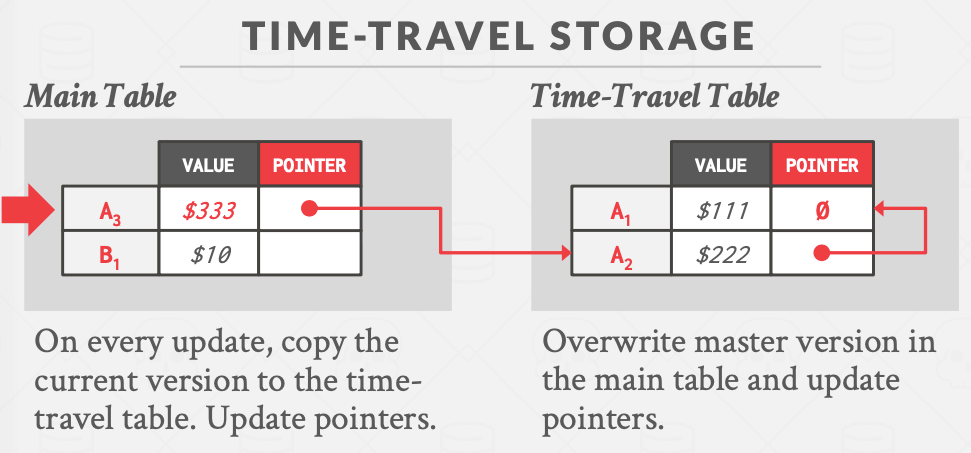
Time travel storage
单独建立一个额外的表用于存储历史数据,主表(Main Table)存储的就是当前最新的数据,历史数据在单独的Time-Travel Table(历史表)里。
当事务对数据进行更新时,也就是产生新版本时,DBMS会把旧版本的对象拷贝至历史表中,并且在历史表中维护好串联起多个旧版本的链表,之后在主表里写入新版本的数据,覆盖旧版本,然后再修改主表中相应的tuple的指针,令其指向历史表里最新的历史版本。
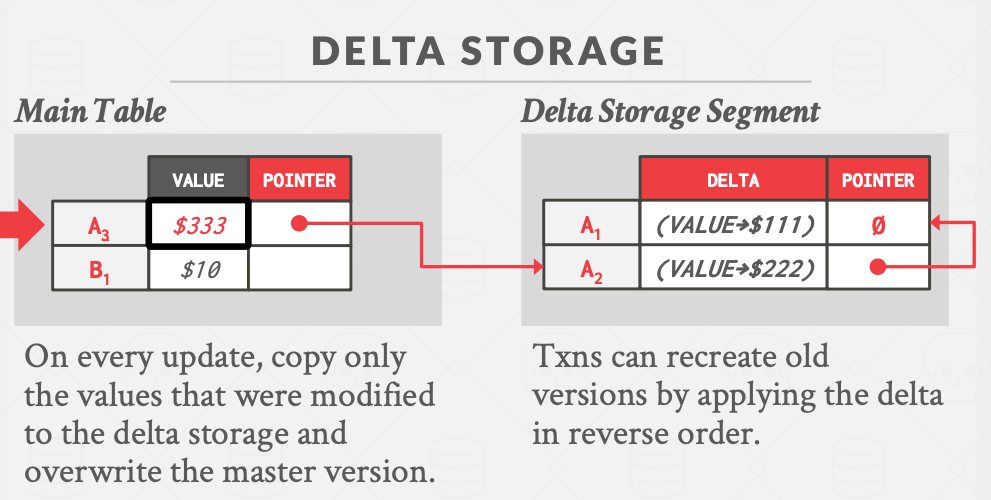
Delta Storage 增量存储
实际的数据库的表中,每个tuple不止有一个attribute,而事务对tuple的一次更新可能只是修改了众多attribute里的一个,因此在历史表里每次都追加一个完整的tuple,这未免有些浪费存储空间。因此就有了只存储每次数据更新时的增量的idea。
垃圾回收
数据库不可能无限地存储各个数据的历史版本,否则就会导致数据库爆炸,存不下那么多的数据,因此DBMS需要把那些已经没有用了,作废了的历史版本删除。
- 如果任何active状态的事务都看不到某个历史版本(比如说现在的事务的时间戳都是10以上的,但这个历史版本的时间戳/版本号是1),那么这个古老的历史版本可以把它删除
- 如果某个事务创建了某个历史版本,但这个事务后来回滚了。那么这个历史版本可以删除
在实现垃圾回收时,要解决如下两个问题:
- 如何发现无用的历史版本?
- 什么时候去删除无用的历史版本?
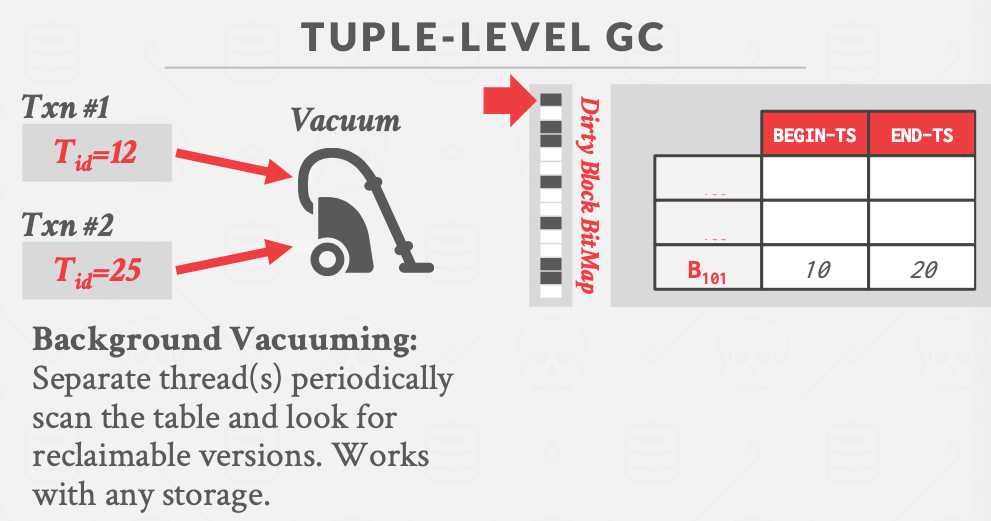
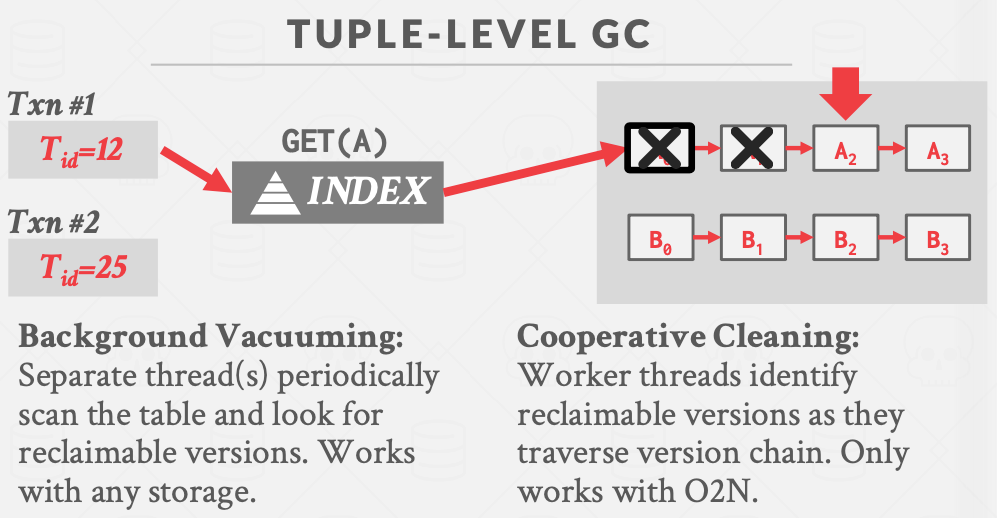
Tuple级别的垃圾回收
(1)后台清理
后台会有一个单独的线程每隔一段时间就扫描历史表(或同类的其他表),然后结合当前active的事务的时间戳去分析表中哪一个版本是无用的。
优化手段:维护一个dirty block bitmap,去跟踪自从上次垃圾回收至今表里有哪些页被事务修改过,因此下一次垃圾回收的时候,只需要扫描自从上次GC以来被修改过的页面。
(2)合作清理
事务执行SQL查询语句时需要通过索引来访问相应的tuple及其历史版本,在这个过程中可以顺便扫描tuple,把无用的历史版本删除。
这只对尾插法的版本存储有用。
这样的话就不需要额外的GC线程来完成垃圾回收,而是各个事务在执行的时候都会做一点垃圾回收的工作。
事务级别的垃圾回收
每个事务会记下来它读/写的集合,记录因为更新导致无用的历史版本,当事务提交时,将这些信息交给垃圾回收器。
垃圾回收器会检查所有正在运行的事物,判断哪些旧版本可以删除。这样,回收器就无需扫描所有tuple了。
索引管理
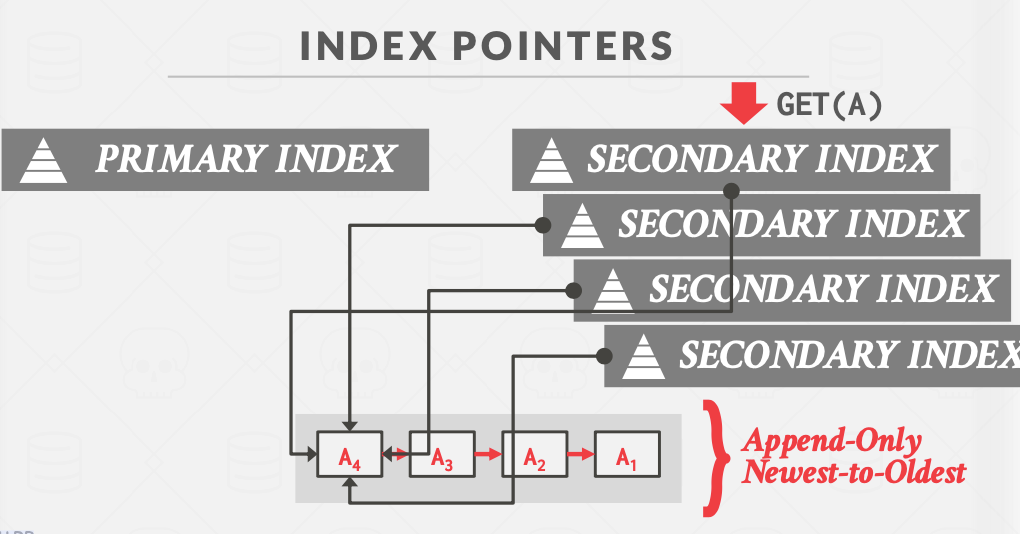
一般情况下,主键索引相对比较好处理,因为主键索引会指向版本链表的头部,而且是通过物理地址(在哪个页的哪个slot)来定位的(如下图)。
辅助索引有点难处理,辅助索引的key是建索引的attribute的值,但val有两种选择:
- 逻辑指针
- 物理指针
逻辑指针指的是val为Tuple的主键或者ID,需要再次通过主键索引找到完整的tuple。
物理指针则直接存储完整Tuple的物理地址(比如哪个页的哪个slot),但是缺点在于更新维护。一张表可能存在多个辅助索引,如果对某个tuple进行更新,不仅要维护主键索引,还要修改所有辅助索引的指针。
MVCC Deletes
当一个tuple的所有版本都不可见时,DBMS物理地将这个tuple删除。
需要一种方式来表明tuple已经逻辑删除:
- deleted flag
- tombstone tuple
可以在tuple的header中加删除标识位;或者加入一个空tuple的版本作为标志。
cmu15-445笔记十三 MVCC