cmu15-445笔记十三 日志
这节课主要介绍基于日志的事务实现。
故障级别
(1)事务级别故障
又分为逻辑错误和内部状态错误。逻辑错误是事务回滚(包括用户主动回滚和OCC校验阶段冲突回滚等),内部错误比如说事务死锁(死锁检测,牺牲等待环中的一个事务)。
事务级别的故障是数据库正常运行所不可避免的,因此这也是数据库开发者所必须考虑的。
(2)系统级故障
这又分为软件异常和硬件异常,软件异常可能是DBMS或者OS的bug,硬件故障可能是断电、CPU故障。硬件故障不包括存储介质故障。
(3)存储介质故障
这类故障一般是无法修复的,数据库开发者无需考虑这些。
Buffer Pool Policies
DBMS需要保证,一旦一个事务提交了,那么这个事务的改变就是永久的。而事务一旦回滚,没有任何部分改变持久化。
DBMS需要特定的缓存池管理方案来实现如下的Undo/Redo操作,从而保证事务的原子性和持久化:
- Undo:撤销事务不完全的改变
- Redo:重做已经提交事务的改变
根据事务对于硬盘的更改,由以下几种语义:
- Steal:事务未提交时,允许其修改硬盘上的数据
- No-Steal:事务未提交时,不允许其修改硬盘上的数据
- Force:事务提交时,所做的更改必须全部落到硬盘上
- No-Force:事务提交时,不要求所做的更改必须全部落到硬盘上
No-Steal+Force
这种语义下,未提交的事务只能操纵缓冲区,然后在提交时,一次性地将所有更改写回磁盘。
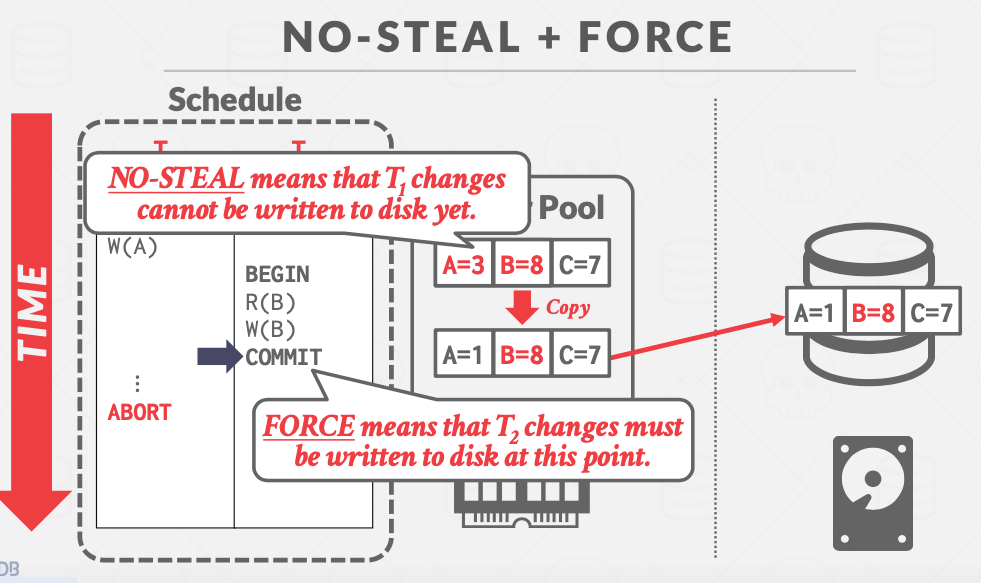
优点:实现容易
- 不需要实现undo,因为未提交的事务的更改不会反映到磁盘上(只有缓冲区被污染,还原即可)
- 不需要实现redo,因为提交的事务的更改必定反映在磁盘上
缺点:
- 事务的更改都存在缓冲区,严重占用缓冲区空间。如果有一部分被修改过的页提前被踢出缓存池,那么就破坏了事务的原子性。特别是全表扫描然后更新的这种场景下,缓存池就会非常紧张。也就是说,每个事务可修改的数据的量严重受缓存池大小限制。
Shadow Paging
Shadow Paging是上文No-Steal+Force策略的一个具体实现。具体地,它会维护两份数据库的数据。
- Master:所有数据的更改都已经提交,是一个一致性的状态。
- Shadow:在Master上作修改,但是事务没有提交。
shadow可以理解为数据库的一份拷贝,事务先在shadow上作修改,提交后,shadow就成为新的master。
为了提高效率,DBMS 不会复制整个数据库,只需要复制有变动的页面。
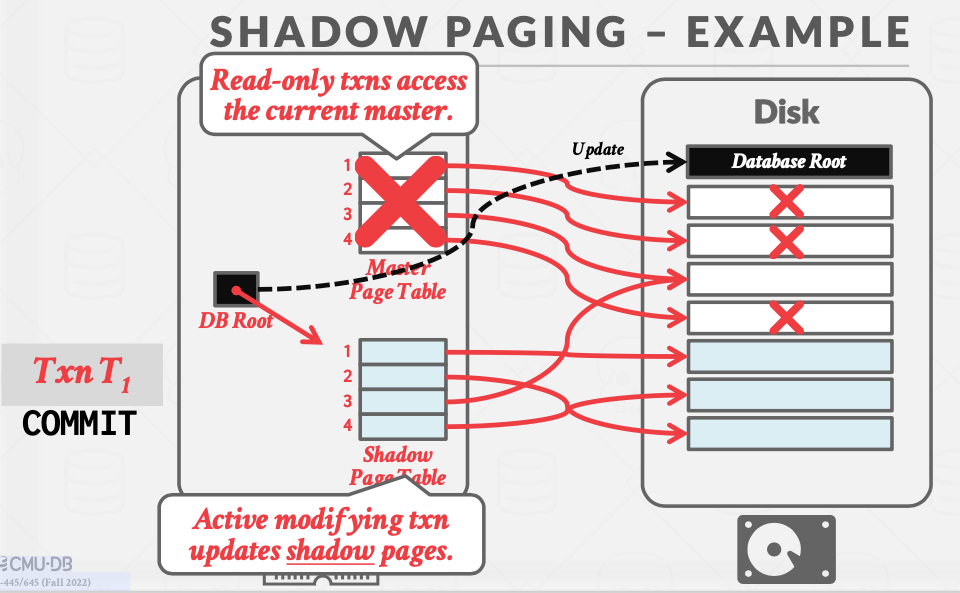
优点:仍然是容易实现redo和undo
- undo:只需撤销shadow page,DB root仍然指向原先的master。
- redo:不需要做什么。
缺点:
- 磁盘IO开销大,事务的每个更新都要落盘;事务提交后还要更新page table、DB root
- 数据的碎片化,存储不连续
- 内存和磁盘旧页需要垃圾清理
- 只支持一个写事务或批量写事务
SQLite

SQLite曾经使用改进后的shadow paging的策略。
硬盘上journal file里存储的是事务要修改的页的原始版本,commit时会把缓存池里修改后的页刷入磁盘里对应的地方(非jouranl file区)。如果刷入Page 2’之后停电了,机器重启后会把journal file加载入缓存,然后把它写入磁盘,这就完成了对断电时未提交的事务的回滚,保证了事务的原子性。
Shadow Paging策略会造成对硬盘的大量的随机访问,这会降低性能,DBMS需要一个方案去把对磁盘的随机的写转换成连续的写。
Write-Ahead Log
“预写日志”,也就是要先写日志,再写数据。在这个策略里,磁盘里面会单独开辟一块类似于前面所讲的journal file的区域,称为log file,用于保存事务对于数据的修改。
DBMS在把用户所修改过的缓存池中的页刷入磁盘之前,它需要先把预写日志写入磁盘中的日志文件,也就是说先完成预写日志的持久化,再完成缓存池里dirty page的持久化。当日志持久化完成,事务才能提交。之后才将dirty page持久化。
Buffer Pool Policy:Steal + No-Force
WAL的日志格式:
1 | → Transaction Id |
实现优化:在事务提交时,需要将日志都刷回磁盘,这将成为性能瓶颈。不妨把多个事务的日志攒到一起提交(第一个到达的事务执行到commit时先阻塞住,然后多攒几个要commit的事务,之后一次性地把它们的日志全部刷入磁盘,然后同时将“事务成功提交”返回给所有等待着的用户),这样的话就会把多个事务的磁盘I/O合并到一起来处理,减少磁盘I/O的次数与开销。
如果某段时间内DBMS中的事务数量不多,很长的一段时间内都没有新的事务到达,那么也没有必要等到事务攒够一定的数量再group commit,不然会导致等待的时间过长。可以设置一个等待时长上限,到了这个上限之后就把当前所有想要commit的事务的日志写入硬盘。
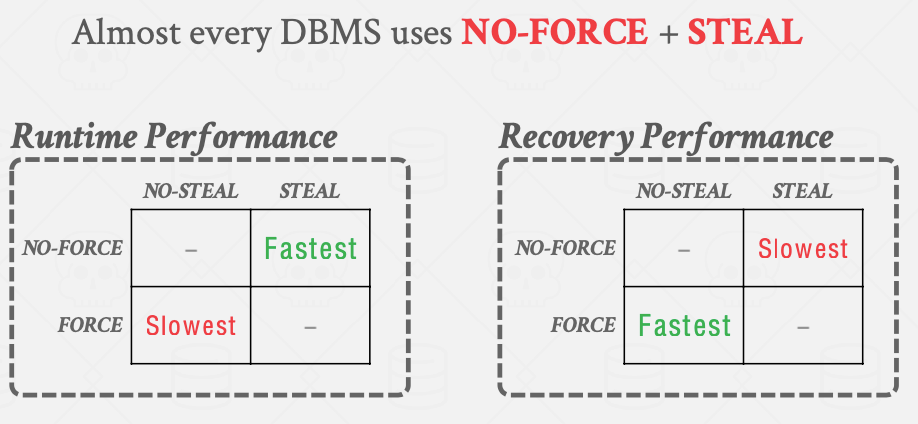
runtime performance是事务正常执行的时候的性能,no-force+steal策略的runtime performance是最好的,因为steal策略会把多次的刷dirty page回磁盘的I/O合并成一次(而且还是顺序写),no-force策略下没有强制要求用户在commit的时候刷盘;与之相反,force+no-steal的runtime performance最差。
recover performance是数据库恢复的时候的性能,no-force+steal策略下的recover performance最差,因为no-force策略会导致宕机后重启时用log重放事务(因为事务commit的时候没有立即把dirty page刷回磁盘),steal策略会导致往磁盘里刷了好多没有还没有提交的事务所做的数据更新,因此DBMS需要执行undo操作把crash的时候没执行完的事务回滚。
DBMS比较注重运行性能,故障恢复比较不常见。
Logging Schemes
- 物理日志:记录每个二进制位的变化
- 逻辑日志:记录日志执行的操作,比如更新、删除、插入等
- 混合式日志phsilogical logging:比如说用page id + slot id记录一条tuple的二进制位发生的变化
物理日志缺点是记录的数据量大,比如修改全表的一个attribute,逻辑日志之需要一条sql语句。
逻辑日志的缺点是:并发问题。由于逻辑日志难以携带并发执行顺序的信息,当同时有多个事务产生更新操作时,数据库内部会将这些操作调度为串行化序列执行,需要机制来保障每次回放操作的执行顺序与调度产生的顺序一致。
逻辑日志的另外一个缺点是:如果sql语句带有不可复现的语句,比如“当前时间”,还是需要记录物理变化。
混合式日志优点是:不会受存储引擎整理数据页中的tuple时造成的影响。(比如,删除相关的SQL指令在页中删除tuple后导致空穴和碎片,DBMS会整理tuple进而清理碎片。整理前后,同一个tuple在这个页中的偏移量会发生变化,因此在清理碎片的同时需要维护物理日志。如果日志里记录的是slot号而非偏移量,那么就省去了这个维护操作带来的开销)
Checkpoints
WAL日志的缺点:
- 无限增大
- 崩溃后,重做日志花费时间长
那么就有一种思想,数据库每隔一段时间,将自己的状态以物理形式记录在磁盘上,这个点以前的日志就无需存储。崩溃重做时,只需加载备份,然后重做一小部分日志即可恢复。
生成checkpoint的算法:
- 停止查询
- 将所有WAL日志都刷到磁盘
- 将所有脏页都刷回磁盘
- 将一个checkpoint的标记刷到日志,然后保存状态(只有当DBMS中已有的事务都结束,而且新的事务没有开始,也就是数据库中没有任何事务在进行,整个数据库是静态的时候,在这样的一个“空档期”才能做checkpoint,这样才能保证实现一致性的快照)
- 开放查询
Checkpoint本身肯定会带来性能损耗,存档需要花时间做磁盘I/O,事务的执行会被阻塞住。并且在数据库恢复的时候需要去根据日志判断哪些事务在crash前没有commit,进而需要扫描日志文件,因此也会带来开销。
数据库多长时间存档一次也是问题。频繁存档影响性能,太长时间存档影响恢复效率。
cmu15-445笔记十三 日志