cmu15-445笔记十四
这节课主要讲述数据库恢复。
ARIES
Algorithms for Recovery and Isolation Exploiting Semantics,“数据库恢复原型算法“。
主要思想:
预写式日志
- 所有改变记在日志中,日志先于数据落盘
- 使用 steal + no-force 缓冲池策略
当 DBMS 重启时,按照日志记录的内容做回放,恢复到故障发生前的状态
在 undo 过程中记录 undo 操作到日志中,确保在恢复期间再次出现故障时不会执行多次相同的 undo 操作
Log Sequence Numbers
WAL中的每条日志记录都需要包含一个全局唯一且一般是单调递增的log sequence number (LSN)。

- flushedLSN:最后一个刷回磁盘的日志序号
- pageLSN:对于一个page x,最后修改它的日志的序号
- recLSN:对于一个page x,它刷回磁盘后第一个修改它的日志序号
- lastLSN:对于一个事务T,它的最后一条日志的序号
- MasterRecord:上一次checkpoint对应的lsn
事务每一次修改缓存里面的数据页,都要顺带修改page对应的pageLSN。
每次把内存里的log刷入磁盘时,DBMS也要顺带更新flushedLSN。
将一个page x刷回磁盘时,要遵循 $pageLSN_X \leq flushedLSN$ ,目的是保证page的修改日志已经落盘。
事务提交
1 | Assumptions in this lecture: |
当事务提交时,DBMS 先写入一条 COMMIT 记录到 WAL ,然后将 COMMIT 及之前的日志落盘。
一旦COMMIT记录安全地存储在磁盘上,DBMS就向应用程序返回事务已提交的确认信息,并将flushedLSN 被修改为 COMMIT 记录的 LSN。
在将来某一时刻,DBMS 会将内存中 COMMIT 及其之前的日志清除,并将缓存池中的脏页刷回磁盘,完成后再写入一条 TXN-END 记录到 WAL 中,作为内部记录。
When the commit succeeds, write a special TXN-END record to log.
→ Indicates that no new log record for a txn will appear in the log ever again.
→ This does not need to be flushed immediately.
TXN-END日志不需要马上刷新到磁盘,丢失也没关系,因为日志已经持久化了。
事务回滚
事务回滚对于数据库来说是特殊情况,因此ARIES算法也会做特殊的处理:在日志记录中再加一个字段:prevLSN。
这个字段代表着相同事务的日志的上一条日志,这样同一个事务的日志就形成了链(e.g. 15号日志记录的上一条日志记录不一定是14号日志记录,因为它们可能属于不同的事务)。
COMPENSATION LOG RECORDS
在对事务做回滚,也就是进行undo操作的时候,要记录”compensation log records”(简称CLR),也就是把进行过的回滚操作也写入日志,从而防止在回滚过程中再次故障导致部分操作被执行多次。
CLR 记录的是 undo 操作,它除了记录原操作相关的记录,还记录了 undoNext 指针,指向下一个将要被 undo 的 LSN。
CLR日志不需要强制落盘,因为大不了就下次DBMS重启的时候重新回滚一遍,不影响事务的原子性(也就是说,在事务abort的时候可以直接告知用户事务abort了,而不必等到所有的undo操作都做完并且CLR都落盘)
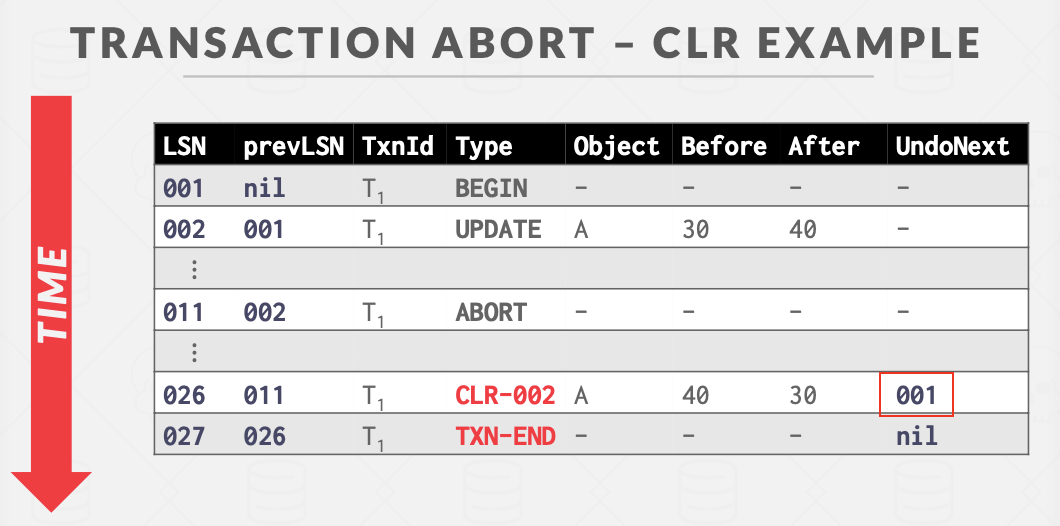
回滚算法
首先记录一条abort的日志。
然后反向分析事务的更新,对于每个更新记录,写一个CLR日志,然后加载恢复旧值。
最后,写TXN-END日志表明回滚完毕,释放所有锁。
Fuzzy checkpoints
Blocking CHECKPOINTS
DBMS在标记checkpoint的时候不让任何新的事务开始执行,并且把系统中还没有执行完的事务都执行完并且完成相应的数据更新的落盘。如果在还没执行完的那些事务里,有的事务非常的长,那么DBMS就会等待相当长的一段时间,在这段时间里不能接收新的事务,这会使得性能非常的差。
SLIGHTLY BETTER CHECKPOINTS
做checkpoint的时候不必等待当前还没执行完的事务去执行完,让它们停下即可。
- 让事务暂停的方法可以是在checkpoint开始后阻止事务获取数据或索引的写锁 (write latch)
- 如果事务是read-only的,那么可以让它继续
这时有些未commit的事务写入的数据可能会被checkpoint线程一起捎带落盘,因此这时磁盘中的数据 snapshot可能处于 inconsistent 的状态。
但是只要我们在 checkpoint 的时候记录哪些活跃事务正在进行,哪些数据页是脏的,故障恢复时读取 WAL 就能知道存在哪些活跃事务的数据可能被部分写出,从而恢复 inconsistent 的数据。因此整个 checkpoint 过程需要两类信息:活跃事务表 (ATT)与脏页表(DPT)
活跃事务表ATT中的entry包含三个字段:事务ID、状态、事务更新的lastLSN
事务彻底完成的时候(也就是它所做的全部更新都落盘,即TXN-END被写入日志时),ATT表中它所对应的entry才可以被删除
状态有:Running、Committing、U(Candidate for Undo)
(事务状态中的U可以理解为“还没提交”:如果数据库crash的时候这个事务还没提交,那么它就需要undo,所以称为”candidate for undo”)
DPT记录的是缓存池中当前还没落盘的脏页。
- entry代表一个未落盘的脏页,以及recLSN(让这个页开始变脏的log record的LSN)

采取了slightly better checkpoints策略后的WAL日志,checkpoint存档点中多了ATT和DPT。
FUZZY CHECKPOINTS
Slightly better checkpoints尽管比 Non-fuzzy 好一些,不需要等待所有活跃事务执行完毕,但仍然需要在 checkpoint 期间暂停执行所有写事务。fuzzy checkpoints策略下,在做checkpoint的时候,所有的事务都可以正常工作,并且不会强制把所有的脏页都
落盘。
fuzzy checkpoints会把原先的日志中的checkpoint的一个时间点变成一个时间段:
- checkpoint-begin:标志着checkpoint的开始,DBMS拍摄ATT和DPT的快照
- checkpoint-end:标志着checkpoint的结束,带有ATT和DPT(由begin阶段获取而来)
在checkpoint开始后的事务不会记录到checkpoint-end的ATT表。
ARIES Recovery
ARIES协议的恢复算法有三个阶段:
- Analysis:读取WAL日志,然后分析哪些脏页还没被刷到磁盘(DPT),哪些事务还是活跃的(ATT)
- Redo:重做
- undo:撤销未提交事务的影响
The DBMS starts the recovery process by examining the log starting from the last BEGIN-CHECKPOINT found via MasterRecord. It then begins the Analysis phase by scanning forward through time to build out ATT and DPT.
In the Redo phase, the algorithm jumps to the smallest recLSN, which is the oldest log record that may have modified a page not written to disk. The DBMS then applies all changes from the smallest recLSN.
The Undo phase starts at the oldest log record of a transaction active at crash and reverses all changes up to that point.
分析阶段
1 | Analysis Phase |
Redo阶段
此阶段的目标是让 DBMS 重复历史记录,以重建其状态,直到崩溃的那一刻。它将重新应用所有更新(甚至中止的事务)并重做 CLR。
1 | The DBMS scans forward from log record containing smallest recLSN in the DPT. For each update log record or CLR with a given LSN, the DBMS re-applies the update unless: |
若要重做操作,DBMS 会重新应用日志记录中的更改,然后将受影响页面的 pageLSN 设置为该日志记录的 LSN。 在重做阶段结束时,为所有状态为 COMMIT 的事务写入 TXN-END 日志记录,并将其从 ATT 中删除。
Undo阶段
在最后阶段,DBMS 会撤消崩溃时处于活动状态的所有事务。这些都是在分析阶段之后在 ATT 中具有 UNDO 状态的事务。
DBMS 使用 lastLSN 以相反的 LSN 顺序处理事务,以加快遍历速度。
当它撤消事务的更新时,DBMS 会为每次修改将一个 CLR 条目写入日志。 成功中止最后一个事务后,DBMS 将清除日志,然后准备开始处理新事务。