typedefstruct { /* XXX LSN is member of *any* block, not only page-organized ones */ PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog * record for last change to this page */ uint16 pd_checksum; /* checksum */ uint16 pd_flags; /* flag bits, see below */ LocationIndex pd_lower; /* offset to start of free space */ LocationIndex pd_upper; /* offset to end of free space */ LocationIndex pd_special; /* offset to start of special space */ uint16 pd_pagesize_version; ShortTransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */ ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* beginning of line pointer array */ } PageHeaderData;
typedefstruct { /* XXX LSN is member of *any* block, not only page-organized ones */ PageXLogRecPtr pd_lsn; /* LSN: next byte after last byte of xlog * record for last change to this page */ uint16 pd_checksum; /* checksum */ uint16 pd_flags; /* flag bits, see below */ LocationIndex pd_lower; /* offset to start of free space */ LocationIndex pd_upper; /* offset to end of free space */ LocationIndex pd_special; /* offset to start of special space */ uint16 pd_pagesize_version; ShortTransactionId pd_prune_xid; /* oldest prunable XID, or zero if none */ TransactionId pd_xid_base; /* base value for transaction IDs on page */ TransactionId pd_multi_base; /* base value for multixact IDs on page */ ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* beginning of line pointer array */ } HeapPageHeaderData;
typedefstructHeapTupleFields { TransactionId t_xmin; /* inserting xact ID */ TransactionId t_xmax; /* deleting or locking xact ID */
union { CommandId t_cid; /* inserting or deleting command ID, or both */ TransactionId t_xvac; /* old-style VACUUM FULL xact ID */ } t_field3; } HeapTupleFields;
typedefstructHeapTupleHeaderData { union { HeapTupleFields t_heap; DatumTupleFields t_datum; } t_choice;
ItemPointerData t_ctid; /* current TID of this or newer tuple */ /* Fields below here must match MinimalTupleData! */ uint16 t_infomask2; /* number of attributes + various flags */ uint16 t_infomask; /* various flag bits, see below */ uint8 t_hoff; /* sizeof header incl. bitmap, padding */ /* ^ - 23 bytes - ^ */ bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; /* bitmap of NULLs -- VARIABLE LENGTH */ /* MORE DATA FOLLOWS AT END OF STRUCT */ } HeapTupleHeaderData;
/* ---------------------------------------------------------------- * ExecutePlan * * Processes the query plan until we have retrieved 'numberTuples' tuples, * moving in the specified direction. * * Runs to completion if numberTuples is 0 * * Note: the ctid attribute is a 'junk' attribute that is removed before the * user can see it * ---------------------------------------------------------------- */ staticvoidExecutePlan(EState *estate, PlanState *planstate, bool use_parallel_mode, CmdType operation, bool sendTuples, uint64 numberTuples, ScanDirection direction, DestReceiver *dest, bool execute_once) { TupleTableSlot *slot; uint64 current_tuple_count;
/* * initialize local variables */ current_tuple_count = 0;
/* * Set the direction. */ estate->es_direction = direction;
/* * If the plan might potentially be executed multiple times, we must force * it to run without parallelism, because we might exit early. Also * disable parallelism when writing into a relation, because no database * changes are allowed in parallel mode. */ if (!execute_once || dest->mydest == DestIntoRel) use_parallel_mode = false;
estate->es_use_parallel_mode = use_parallel_mode; if (use_parallel_mode) EnterParallelMode();
/* * Loop until we've processed the proper number of tuples from the plan. */ for (;;) { /* Reset the per-output-tuple exprcontext */ ResetPerTupleExprContext(estate);
/* * Execute the plan and obtain a tuple */ slot = ExecProcNode(planstate);
/* * if the tuple is null, then we assume there is nothing more to * process so we just end the loop... */ if (TupIsNull(slot)) { /* Allow nodes to release or shut down resources. */ (void) ExecShutdownNode(planstate); break; }
/* * If we have a junk filter, then project a new tuple with the junk * removed. * * Store this new "clean" tuple in the junkfilter's resultSlot. * (Formerly, we stored it back over the "dirty" tuple, which is WRONG * because that tuple slot has the wrong descriptor.) */ if (estate->es_junkFilter != NULL) slot = ExecFilterJunk(estate->es_junkFilter, slot);
/* * If we are supposed to send the tuple somewhere, do so. (In * practice, this is probably always the case at this point.) */ if (sendTuples) { /* * If we are not able to send the tuple, we assume the destination * has closed and no more tuples can be sent. If that's the case, * end the loop. */ if (!((*dest->receiveSlot) (slot, dest))) break; }
/* * Count tuples processed, if this is a SELECT. (For other operation * types, the ModifyTable plan node must count the appropriate * events.) */ if (operation == CMD_SELECT) (estate->es_processed)++;
/* * check our tuple count.. if we've processed the proper number then * quit, else loop again and process more tuples. Zero numberTuples * means no limit. */ current_tuple_count++; if (numberTuples && numberTuples == current_tuple_count) { /* Allow nodes to release or shut down resources. */ (void) ExecShutdownNode(planstate); break; } }
/* * Fetch data from node */ qual = node->ps.qual; projInfo = node->ps.ps_ProjInfo; econtext = node->ps.ps_ExprContext;
/* interrupt checks are in ExecScanFetch */
/* * If we have neither a qual to check nor a projection to do, just skip * all the overhead and return the raw scan tuple. */ if (!qual && !projInfo) { ResetExprContext(econtext); return ExecScanFetch(node, accessMtd, recheckMtd); }
/* * Reset per-tuple memory context to free any expression evaluation * storage allocated in the previous tuple cycle. */ ResetExprContext(econtext);
/* * get a tuple from the access method. Loop until we obtain a tuple that * passes the qualification. */ for (;;) { TupleTableSlot *slot;
/* * if the slot returned by the accessMtd contains NULL, then it means * there is nothing more to scan so we just return an empty slot, * being careful to use the projection result slot so it has correct * tupleDesc. */ if (TupIsNull(slot)) { if (projInfo) return ExecClearTuple(projInfo->pi_state.resultslot); else return slot; }
/* * place the current tuple into the expr context */ econtext->ecxt_scantuple = slot;
/* * check that the current tuple satisfies the qual-clause * * check for non-null qual here to avoid a function call to ExecQual() * when the qual is null ... saves only a few cycles, but they add up * ... */ if (qual == NULL || ExecQual(qual, econtext)) { /* * Found a satisfactory scan tuple. */ if (projInfo) { /* * Form a projection tuple, store it in the result tuple slot * and return it. */ return ExecProject(projInfo); } else { /* * Here, we aren't projecting, so just return scan tuple. */ return slot; } } else InstrCountFiltered1(node, 1);
/* * Tuple fails qual, so free per-tuple memory and try again. */ ResetExprContext(econtext); } }
if (estate->es_epqTuple != NULL) { /* * We are inside an EvalPlanQual recheck. Return the test tuple if * one is available, after rechecking any access-method-specific * conditions. */ Index scanrelid = ((Scan *) node->ps.plan)->scanrelid;
if (scanrelid == 0) { TupleTableSlot *slot = node->ss_ScanTupleSlot;
/* * This is a ForeignScan or CustomScan which has pushed down a * join to the remote side. The recheck method is responsible not * only for rechecking the scan/join quals but also for storing * the correct tuple in the slot. */ if (!(*recheckMtd) (node, slot)) ExecClearTuple(slot); /* would not be returned by scan */ return slot; } elseif (estate->es_epqTupleSet[scanrelid - 1]) { TupleTableSlot *slot = node->ss_ScanTupleSlot;
/* Return empty slot if we already returned a tuple */ if (estate->es_epqScanDone[scanrelid - 1]) return ExecClearTuple(slot); /* Else mark to remember that we shouldn't return more */ estate->es_epqScanDone[scanrelid - 1] = true;
/* Return empty slot if we haven't got a test tuple */ if (estate->es_epqTuple[scanrelid - 1] == NULL) return ExecClearTuple(slot);
/* Store test tuple in the plan node's scan slot */ ExecStoreTuple(estate->es_epqTuple[scanrelid - 1], slot, InvalidBuffer, false);
/* Check if it meets the access-method conditions */ if (!(*recheckMtd) (node, slot)) ExecClearTuple(slot); /* would not be returned by scan */
return slot; } }
/* * Run the node-type-specific access method function to get the next tuple */ return (*accessMtd) (node); }
typedefstructScanState { PlanState ps; /* its first field is NodeTag */ Relation ss_currentRelation; HeapScanDesc ss_currentScanDesc; TupleTableSlot *ss_ScanTupleSlot; } ScanState;
/* ---------------- * SeqScanState information * ---------------- */ typedefstructSeqScanState { ScanState ss; /* its first field is NodeTag */ Size pscan_len; /* size of parallel heap scan descriptor */ } SeqScanState;
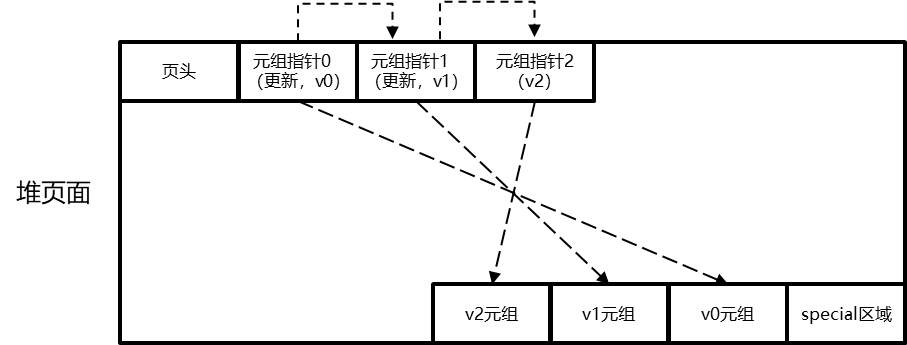
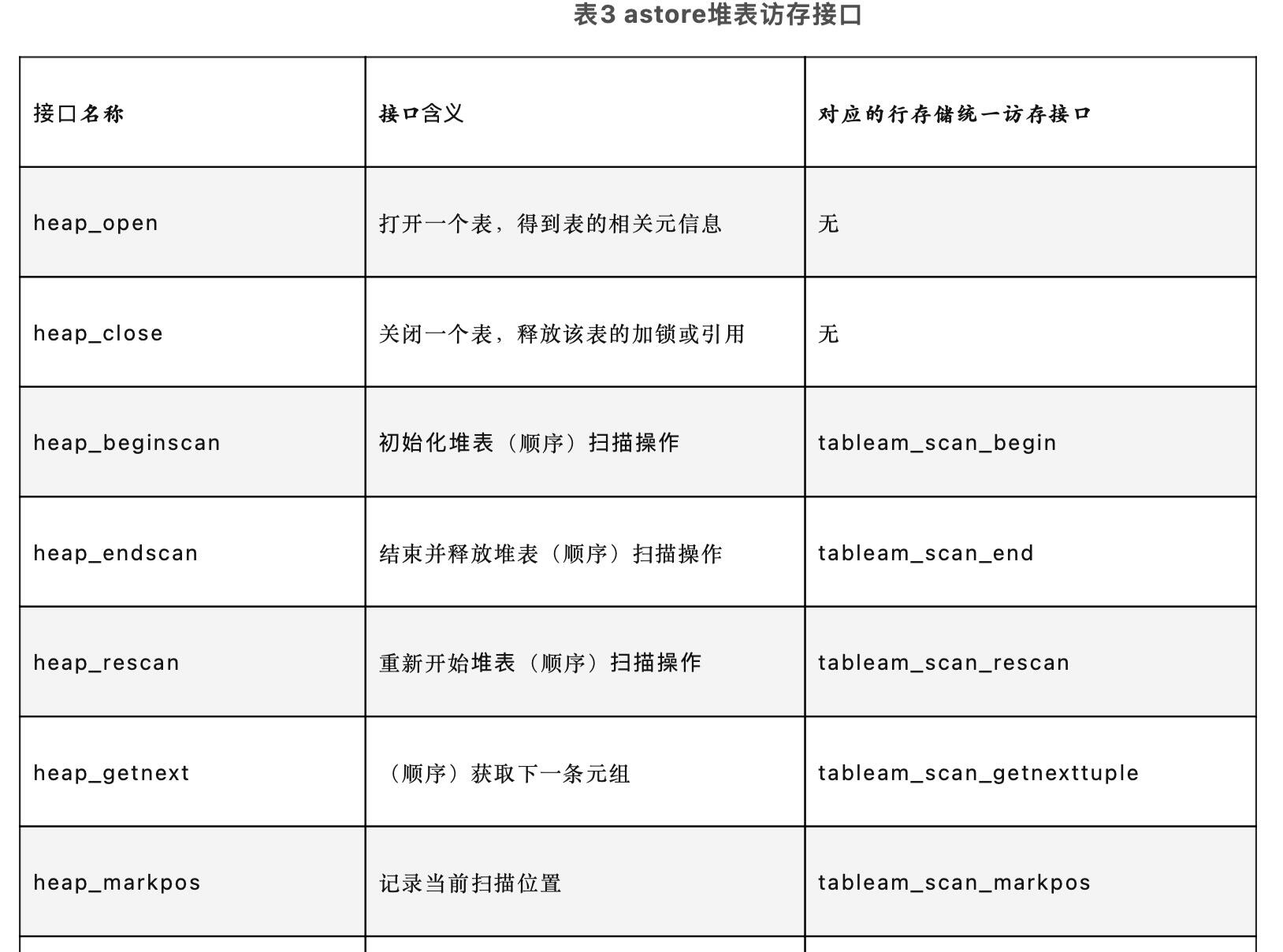
typedefstructHeapScanDescData { /* scan parameters */ Relation rs_rd; /* 堆表描述符;heap relation descriptor */ Snapshot rs_snapshot; /* 快照;snapshot to see */ int rs_nkeys; /* 扫描键数;number of scan keys */ ScanKey rs_key; /* 扫描键数组;array of scan key descriptors */ bool rs_bitmapscan; /* bitmap scan=>T;true if this is really a bitmap scan */ bool rs_samplescan; /* sample scan=>T;true if this is really a sample scan */ bool rs_pageatatime; /* 是否验证可见性(MVCC机制);verify visibility page-at-a-time? */ bool rs_allow_strat; /* 是否允许访问策略的使用;allow or disallow use of access strategy */ bool rs_allow_sync; /* 是否允许syncscan的使用;allow or disallow use of syncscan */ bool rs_temp_snap; /* 是否在扫描结束后取消快照"登记";unregister snapshot at scan end? */ /* state set up at initscan time */ BlockNumber rs_nblocks; /* rel中的blocks总数;total number of blocks in rel */ BlockNumber rs_startblock; /* 开始的block编号;block # to start at */ BlockNumber rs_numblocks; /* 最大的block编号;max number of blocks to scan */ /* rs_numblocks is usually InvalidBlockNumber, meaning "scan whole rel" */ BufferAccessStrategy rs_strategy; /* 读取时的访问场景;access strategy for reads */ bool rs_syncscan; /* 在syncscan逻辑处理时是否报告位置;report location to syncscan logic? */ /* scan current state */ bool rs_inited; /* 如为F,则扫描尚未初始化;false = scan not init'd yet */ HeapTupleData rs_ctup; /* 当前扫描的tuple;current tuple in scan, if any */ BlockNumber rs_cblock; /* 当前扫描的block;current block # in scan, if any */ Buffer rs_cbuf; /* 当前扫描的buffer;current buffer in scan, if any */ /* NB: if rs_cbuf is not InvalidBuffer, we hold a pin on that buffer */ ParallelHeapScanDesc rs_parallel; /* 并行扫描信息;parallel scan information */ /* these fields only used in page-at-a-time mode and for bitmap scans */ int rs_cindex; /* 在vistuples中的当前元组索引;current tuple's index in vistuples */ int rs_ntuples; /* page中的可见元组计数;number of visible tuples on page */ OffsetNumber rs_vistuples[MaxHeapTuplesPerPage]; /* 元组的偏移;their offsets */ } HeapScanDescData; /* struct definitions appear in relscan.h */ typedefstructHeapScanDescData *HeapScanDesc;
/* * get information from the estate and scan state */ scandesc = node->ss.ss_currentScanDesc; estate = node->ss.ps.state; direction = estate->es_direction; slot = node->ss.ss_ScanTupleSlot; /* 如果不存在scandesc,就创建一个scandesc */ if (scandesc == NULL) { /* * We reach here if the scan is not parallel, or if we're serially * executing a scan that was planned to be parallel. */ scandesc = heap_beginscan(node->ss.ss_currentRelation, estate->es_snapshot, 0, NULL); node->ss.ss_currentScanDesc = scandesc; }
/* * get the next tuple from the table * 获取一条可见元组 */ tuple = heap_getnext(scandesc, direction);
/* * save the tuple and the buffer returned to us by the access methods in * our scan tuple slot and return the slot. Note: we pass 'false' because * tuples returned by heap_getnext() are pointers onto disk pages and were * not created with palloc() and so should not be pfree()'d. Note also * that ExecStoreTuple will increment the refcount of the buffer; the * refcount will not be dropped until the tuple table slot is cleared. * 一些清理工作,比如对buffer page执行unpin操作。 */ if (tuple) ExecStoreTuple(tuple, /* tuple to store */ slot, /* slot to store in */ scandesc->rs_cbuf, /* buffer associated with this * tuple */ false); /* don't pfree this pointer */ else ExecClearTuple(slot);
if (scan->rs_ctup.t_data == NULL) { HEAPDEBUG_2; /* heap_getnext returning EOS */ returnNULL; }
/* * if we get here it means we have a new current scan tuple, so point to * the proper return buffer and return the tuple. */ HEAPDEBUG_3; /* heap_getnext returning tuple */

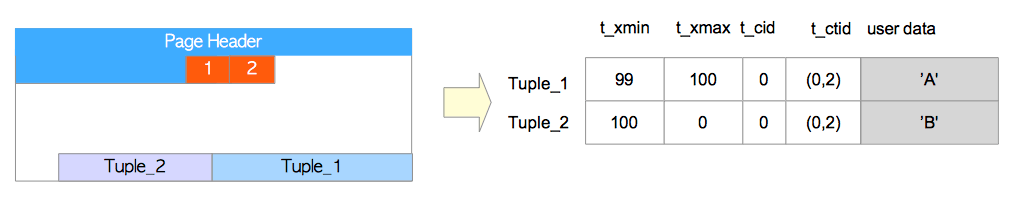
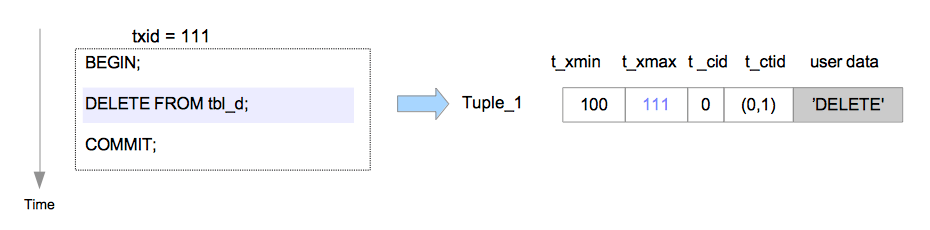
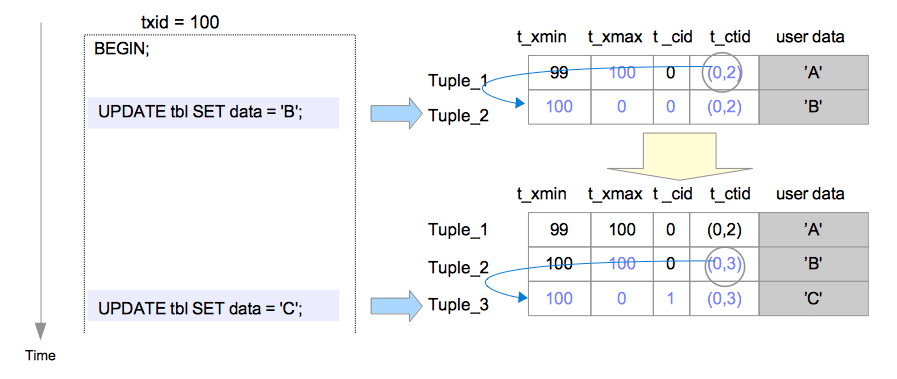
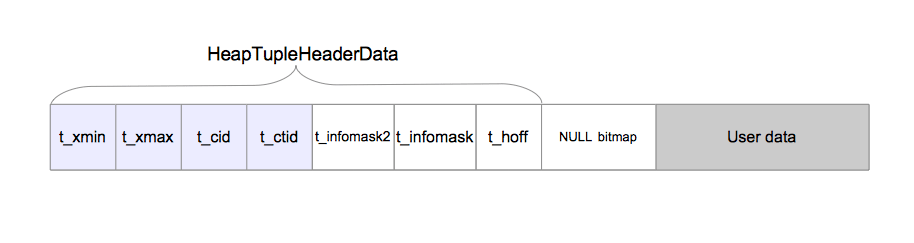 t_xmin:代表插入此元组的事务xid;
t_xmin:代表插入此元组的事务xid;