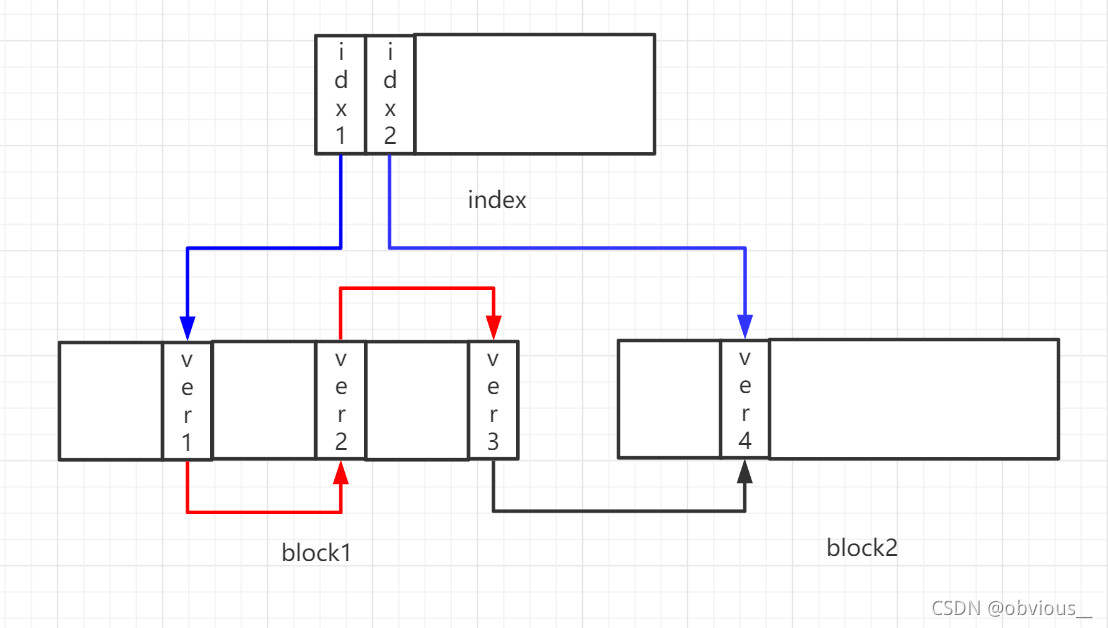
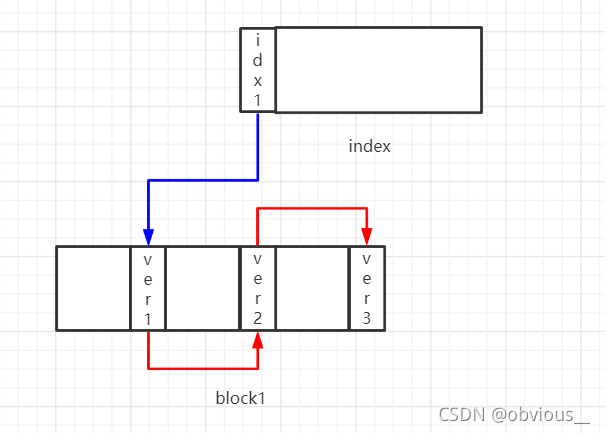
Free Space Map,FSM,空闲空间映射图。当数据块中进行insert、update、delete这些操作时,都会产生一个旧版本的数据。vacuum时便会清理掉这些旧版本数据,数据块便存在许多空闲的空间,如果能够将这些空间再次利用起来当然是很好的,不然新插入数据时继续分配一个新的数据块,那数据文件的膨胀速度就会非常快,因此便通过FSM来实现这一功能。
if (PageHasFreeLinePointers(phdr)) { /* * Look for "recyclable" (unused) ItemId. We check for no storage * as well, just to be paranoid --- unused items should never have * storage. */ for (offsetNumber = 1; offsetNumber < limit; offsetNumber++) { itemId = PageGetItemId(phdr, offsetNumber); if (!ItemIdIsUsed(itemId) && !ItemIdHasStorage(itemId)) break; } if (offsetNumber >= limit) { /* the hint is wrong, so reset it */ PageClearHasFreeLinePointers(phdr); } }
/* Ignore items already processed as part of an earlier chain */ if (prstate.marked[offnum]) continue;
/* Nothing to do if slot is empty or already dead */ itemid = PageGetItemId(page, offnum); if (!ItemIdIsUsed(itemid) || ItemIdIsDead(itemid)) continue;
/* Process this item or chain of items */ ndeleted += heap_prune_chain(relation, buffer, offnum, OldestXmin, &prstate); } ...
/* Have we found any prunable items? */ if (prstate.nredirected > 0 || prstate.ndead > 0 || prstate.nunused > 0) { /* * Apply the planned item changes, then repair page fragmentation, and * update the page's hint bit about whether it has free line pointers. */ heap_page_prune_execute(buffer, prstate.redirected, prstate.nredirected, prstate.nowdead, prstate.ndead, prstate.nowunused, prstate.nunused);
/* Start from the root tuple */ offnum = rootoffnum;
/* while not end of the chain * 步骤1:遍历元组的HOT链 */ for (;;) { ItemId lp; bool tupdead, recent_dead;
/* Some sanity checks */ if (offnum < FirstOffsetNumber || offnum > maxoff) break;
/* If item is already processed, stop --- it must not be same chain */ if (prstate->marked[offnum]) break;
lp = PageGetItemId(dp, offnum);
/* Unused item obviously isn't part of the chain */ if (!ItemIdIsUsed(lp)) break;
/* * If we are looking at the redirected root line pointer, jump to the * first normal tuple in the chain. If we find a redirect somewhere * else, stop --- it must not be same chain. */ if (ItemIdIsRedirected(lp)) { if (nchain > 0) break; /* not at start of chain */ chainitems[nchain++] = offnum; offnum = ItemIdGetRedirect(rootlp); continue; }
/* * Likewise, a dead item pointer can't be part of the chain. (We * already eliminated the case of dead root tuple outside this * function.) */ if (ItemIdIsDead(lp)) break;
/* * Check the tuple XMIN against prior XMAX, if any */ if (TransactionIdIsValid(priorXmax) && !TransactionIdEquals(HeapTupleHeaderGetXmin(htup), priorXmax)) break;
/* * OK, this tuple is indeed a member of the chain. */ chainitems[nchain++] = offnum;
/* * Remember the last DEAD tuple seen. We will advance past * RECENTLY_DEAD tuples just in case there's a DEAD one after them; * but we can't advance past anything else. (XXX is it really worth * continuing to scan beyond RECENTLY_DEAD? The case where we will * find another DEAD tuple is a fairly unusual corner case.) */ if (tupdead) { latestdead = offnum; HeapTupleHeaderAdvanceLatestRemovedXid(htup, &prstate->latestRemovedXid); } elseif (!recent_dead) break;
/* * If the tuple is not HOT-updated, then we are at the end of this * HOT-update chain. * 判断是否到达链尾,链尾不含HEAP_HOT_UPDATED标志。 */ if (!HeapTupleHeaderIsHotUpdated(htup)) break;
/* * Advance to next chain member. */ Assert(ItemPointerGetBlockNumber(&htup->t_ctid) == BufferGetBlockNumber(buffer)); offnum = ItemPointerGetOffsetNumber(&htup->t_ctid); priorXmax = HeapTupleHeaderGetUpdateXid(htup); }
/* * If we found a DEAD tuple in the chain, adjust the HOT chain so that all * the DEAD tuples at the start of the chain are removed and the root line * pointer is appropriately redirected. * 步骤3:记录需要设置为LP_UNUSED、LP_DEAD、LP_REDIRECT的元组 */ if (OffsetNumberIsValid(latestdead)) { /* * Mark as unused each intermediate item that we are able to remove * from the chain. * * When the previous item is the last dead tuple seen, we are at the * right candidate for redirection. */ for (i = 1; (i < nchain) && (chainitems[i - 1] != latestdead); i++) { //记录需要设置为LP_UNUSED的元组 heap_prune_record_unused(prstate, chainitems[i]); ndeleted++; }
/* * If the root entry had been a normal tuple, we are deleting it, so * count it in the result. But changing a redirect (even to DEAD * state) doesn't count. */ if (ItemIdIsNormal(rootlp)) ndeleted++;
/* * If the DEAD tuple is at the end of the chain, the entire chain is * dead and the root line pointer can be marked dead. Otherwise just * redirect the root to the correct chain member. */ if (i >= nchain) /*记录需要设置为LP_DEAD的元组i >= nchain说明HOT链上的所有元组都过期了, *这时需要将链头设置为LP_DEAD */ heap_prune_record_dead(prstate, rootoffnum); else /*HOT链上还有元组没有过期,所以需要将链头重定位到该元组*/ heap_prune_record_redirect(prstate, rootoffnum, chainitems[i]); } elseif (nchain < 2 && ItemIdIsRedirected(rootlp)) { /* * We found a redirect item that doesn't point to a valid follow-on * item. This can happen if the loop in heap_page_prune caused us to * visit the dead successor of a redirect item before visiting the * redirect item. We can clean up by setting the redirect item to * DEAD state. */ heap_prune_record_dead(prstate, rootoffnum); }
void heap_page_prune_execute(Buffer buffer, OffsetNumber *redirected, int nredirected, OffsetNumber *nowdead, int ndead, OffsetNumber *nowunused, int nunused) { Page page = (Page) BufferGetPage(buffer); OffsetNumber *offnum; int i;
//步骤1:依据heap_prune_chain的处理结果,将相关元组设置为LP_UNUSED、LP_DEAD、LP_REDIRECT。 /* Update all redirected line pointers */ offnum = redirected; for (i = 0; i < nredirected; i++) { OffsetNumber fromoff = *offnum++; OffsetNumber tooff = *offnum++; ItemId fromlp = PageGetItemId(page, fromoff);
ItemIdSetRedirect(fromlp, tooff); }
/* Update all now-dead line pointers */ offnum = nowdead; for (i = 0; i < ndead; i++) { OffsetNumber off = *offnum++; ItemId lp = PageGetItemId(page, off);
ItemIdSetDead(lp); }
/* Update all now-unused line pointers */ offnum = nowunused; for (i = 0; i < nunused; i++) { OffsetNumber off = *offnum++; ItemId lp = PageGetItemId(page, off);
ItemIdSetUnused(lp); }
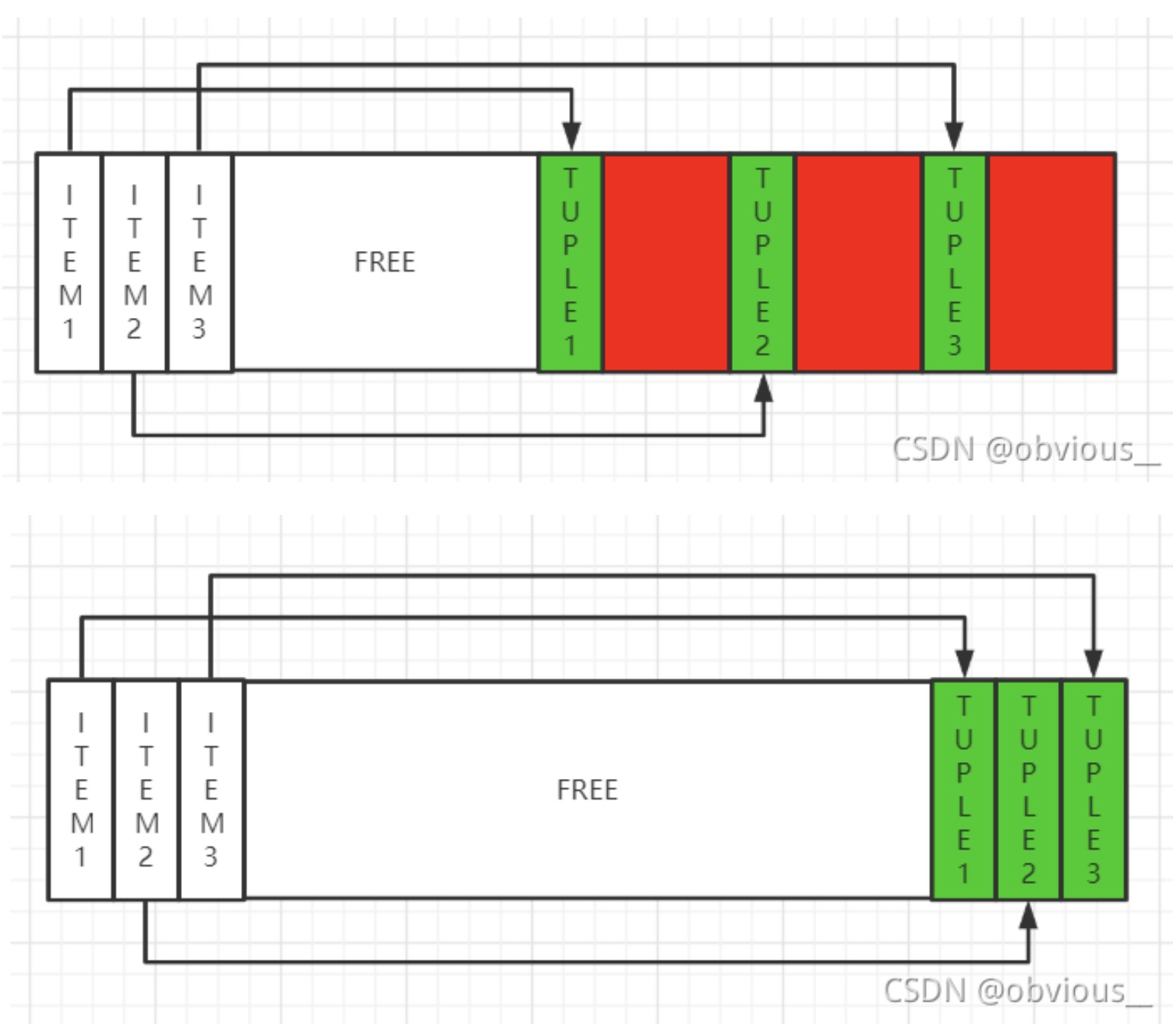
/* * Finally, repair any fragmentation, and update the page's hint bit about * whether it has free pointers. * 步骤2:调用PageRepairFragmentation对页面内进行空间整理,即删除过期元组的元组实体部分。 */ PageRepairFragmentation(page); }
/* * It's worth the trouble to be more paranoid here than in most places, * because we are about to reshuffle data in (what is usually) a shared * disk buffer. If we aren't careful then corrupted pointers, lengths, * etc could cause us to clobber adjacent disk buffers, spreading the data * loss further. So, check everything. */ if (pd_lower < SizeOfPageHeaderData || pd_lower > pd_upper || pd_upper > pd_special || pd_special > BLCKSZ || pd_special != MAXALIGN(pd_special)) ereport(ERROR, (errcode(ERRCODE_DATA_CORRUPTED), errmsg("corrupted page pointers: lower = %u, upper = %u, special = %u", pd_lower, pd_upper, pd_special)));
nline = PageGetMaxOffsetNumber(page); nunused = nstorage = 0; //步骤1:统计块内需要保留的元组数量。 for (i = FirstOffsetNumber; i <= nline; i++) { lp = PageGetItemId(page, i); if (ItemIdIsUsed(lp)) { if (ItemIdHasStorage(lp)) nstorage++; } else { /* Unused entries should have lp_len = 0, but make sure */ ItemIdSetUnused(lp); nunused++; } }
if (nstorage == 0) { /* Page is completely empty, so just reset it quickly * 如果块内没有元组需要保留,则直接修改块的pd_upper指针让其指向块末尾。 */ ((PageHeader) page)->pd_upper = pd_special; } else { /* Need to compact the page the hard way */ itemIdSortData itemidbase[MaxHeapTuplesPerPage]; itemIdSort itemidptr = itemidbase; //步骤2:记录块内需要保留的元组。 totallen = 0; for (i = 0; i < nline; i++) { lp = PageGetItemId(page, i + 1); if (ItemIdHasStorage(lp)) { itemidptr->offsetindex = i; itemidptr->itemoff = ItemIdGetOffset(lp); if (itemidptr->itemoff < (int) pd_upper || itemidptr->itemoff >= (int) pd_special) ereport(ERROR, (errcode(ERRCODE_DATA_CORRUPTED), errmsg("corrupted item pointer: %u", itemidptr->itemoff))); itemidptr->alignedlen = MAXALIGN(ItemIdGetLength(lp)); totallen += itemidptr->alignedlen; itemidptr++; } }
if (totallen > (Size) (pd_special - pd_lower)) ereport(ERROR, (errcode(ERRCODE_DATA_CORRUPTED), errmsg("corrupted item lengths: total %u, available space %u", (unsignedint) totallen, pd_special - pd_lower)));