openGauss整体架构
openGauss整体架构
客户端/服务端通信
#/src/gausskernel/process/postmaster
openGauss查询响应是使用简单的“单一用户对应一个服务器线程”的客户端/服务器模型实现。
openGauss数据库中处理客户端连接请求的模块叫做postmaster。主进程(GaussMaster)主进程在指定的TCP/IP端口上侦听传入的连接,只要检测到连接请求,主进程就会生成一个新的服务器线程。
服务器线程之间使用信号量和共享内存相互通信,以确保整个并发数据访问期间的数据完整性。
建立连接后,客户端进程可以将查询发送到后端服务器。服务器解析查询语句、创建执行计划、执行并通过在已建立的连接上传输检索到的结果集,将其返回给客户端。
公共组件
系统表
数据库初始化
多线程架构|线程池
内存管理
模拟信号机制
多维监控
SQL引擎
#/src/common/backend/parser
SQL引擎负责解析SQL字符串语句,然后输出执行计划(查询计划?计划树方式传递给执行器)。
查询解析—parser
SQL解析对输入的SQL语句进行词法分析、语法分析、语义分析,获得查询解析树或者逻辑计划。
查询分流—traffic cop
#src/gausskernel/process/tcop
traffic cop模块负责查询的分流,它负责区分简单和复杂的查询指令。事务控制命令(例如BEGIN和ROLLBACK)非常简单,因此不需要其它处理,而其它命令(例如SELECT和JOIN)则传递给重写器。
简单和复杂查询指令也对应如下2类解析:
(1)软解析(简单,旧查询):当openGauss共享缓冲区中存在已提交SQL语句的已解析表示形式时,可以重复利用缓存内容执行语法和语义检查,避免查询优化的相对昂贵的操作。
(2)硬解析(复杂,新查询):如果无缓存语句可重用,或者第一次将SQL语句加载到openGauss共享缓冲区中,则会导致硬解析。同样,当一条语句在共享缓冲区中老化时,再次重新加载该语句时,还会导致另一次硬解析。因此,共享Buffer的大小也会影响解析调用的数量。‘
也就是说openGauss区别了简单和复杂的Sql语句,并为已解析的sql建立了缓存。
查询重写—rewriter
#src/gausskernel/optimizer/rewrite
查询重写利用已有语句特征和关系代数运算来生成更高效的等价语句,在数据库优化器中扮演关键角色
几个查询重写:
- 常量表达式化简
- 嵌套子查询化为半连接semi join
- 谓词下推
查询优化—optimizer
在某些情况下,检查执行查询的每种可能方式都会占用大量时间和内存空间,特别是在执行涉及大量连接操作(Join)的查询时。
为了在合理的时间内确定合理的(不一定是最佳的)查询计划,当查询连接数超过阈值时,openGauss使用遗传查询优化器(genetic query optimizer),通过遗传算法来做执行计划的枚举。
优化器的查询计划(plan)确定代价最低的路径后,将构建完整的计划树以传递给执行器。
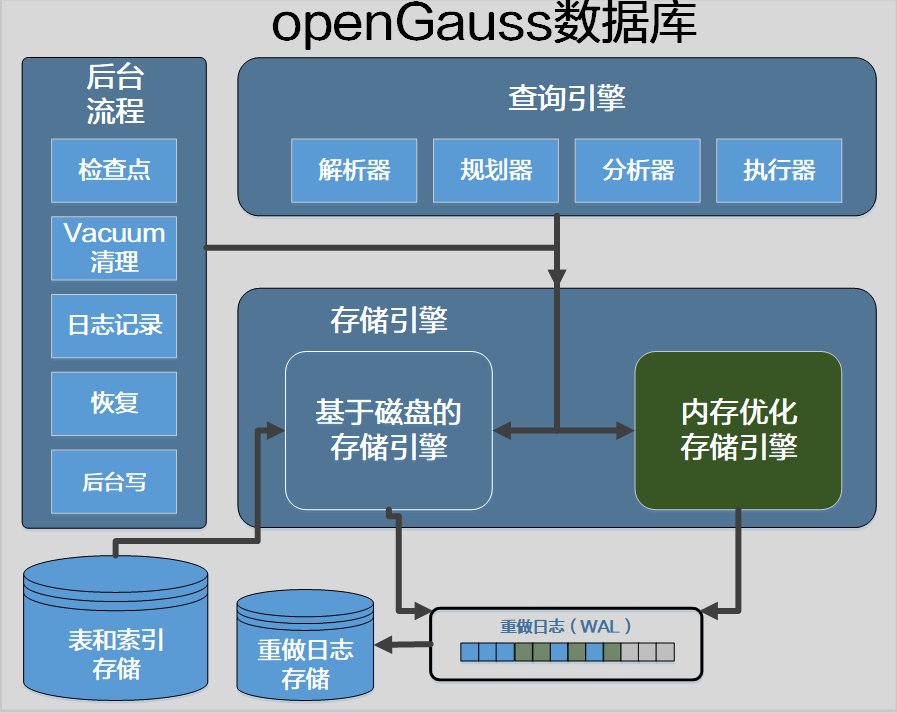
存储引擎

总体上,根据存储介质和并发控制机制,存储引擎分为磁盘引擎和内存引擎两大类。
- 磁盘引擎主要面向通用的、大容量的业务场景
- astore(append-store,追加写优化格式)
- usotre(In-place Update,原地更新优化格式)
- cstore(column store,列存储格式)
- 可拓展的数据元组和数据页面组织格式
- 内存引擎主要面向容量可控的、追求极致性能的业务场景
- mstore(memory-store,内存优化格式)
openGauss存储引擎是可插拔、自组装的,支持多个存储引擎来满足不同场景的业务诉求,目前支持
- 行存储引擎
- 列存储引擎
- 内存引擎
行存储引擎
磁盘引擎存储可以分为行存储格式和列存储格式。这两种数据格式共用相同的事务并发控制、日志系统、持久化和故障恢复、主备系统。
在此基础之上,行存储格式内部设计为可以支持多种不同子格式的可扩展架构。不同行存储子格式之间共用相同的行存储统一访存接口(table access method)、共享缓冲区、索引机制等。
行存储引擎:
- astore(追加写优化)
- ustore(写优化)
在openGauss行存储格式中,对同一行数据的写-写查询冲突通过两阶段锁协议来实现并发控制;对同一行数据的读-写查询冲突通过行级多版本技术来实现互不阻塞的、高效的并发控制。
事务机制
事务架构
并发控制
事务ID与CLGO/CSNLOG
MVCC机制
锁机制