《Linux多线程服务端编程:使用muduo C++网络库》,muduo的核心我认为是EventLoop、Poller、Channel。EventLoop实现了one loop per thread 语义,poller管理众多channel、channel管理fd以及相关的事件回调。三者互相配合,实现了简洁高效的网络库。
注:为展示核心逻辑,贴出的代码有删减。
前置知识 std::bind
std::function
eventfd
前置知识:eventfd相当于一个计数器,可以随时对它写,但只能在计数器有值时可读。写入为累加操作,读取可每次读1或者读全部,随后减去读取的值。
那么eventfd有什么作用?事件通知/事件驱动。
线程b监听一个eventfd,线程a如果想要通知线程b,只需要向eventfd中写值就行了。
引用eventfs的Manual中NOTE段落的第一句话:
Applications can use an eventfd file descriptor instead of a pipe in all cases where a pipe is used simply to signal events.
在信号通知的场景下,相比pipe有非常大的资源和性能优势。其根本在于counter(计数器)和channel(数据信道)的区别。
第一,是打开文件数量的巨大差别。由于pipe是半双工的传统IPC方式,所以两个线程通信需要两个pipe文件,而用eventfd只要打开一个文件。众所周知,文件描述符可是系统中非常宝贵的资源,linux的默认值也只有1024而已。那开发者可能会说,1相比2也只节省了一半嘛。要知道pipe只能在两个进程/线程间使用,并且是面向连接(类似TCP socket)的,即需要之前准备好两个pipe;而eventfd是广播式的通知,可以多对多的。如上面的NxM的生产者-消费者例子,如果需要完成全双工的通信,需要NxMx2个的pipe,而且需要提前建立并保持打开,作为通知信号实在太奢侈了,但如果用eventfd,只需要在发通知的时候瞬时创建、触发并关闭一个即可。
第二,是内存使用的差别。eventfd是一个计数器,内核维护几乎成本忽略不计,大概是自旋锁+唤醒队列(后续详细介绍),8个字节的传输成本也微乎其微。但pipe可就完全不是了,一来一回数据在用户空间和内核空间有多达4次的复制,而且更糟糕的是,内核还要为每个pipe分配至少4K的虚拟内存页,哪怕传输的数据长度为0。
第三,对于timerfd,还有精准度和实现复杂度的巨大差异。由内核管理的timerfd底层是内核中的hrtimer(高精度时钟定时器),可以精确至纳秒(1e-9秒)级,完全胜任实时任务。而用户态要想实现一个传统的定时器,通常是基于优先队列/二叉堆,不仅实现复杂维护成本高,而且运行时效率低,通常只能到达毫秒级。
所以,第一个最佳实践法则:当pipe只用来发送通知(传输控制信息而不是实际数据),放弃pipe,放心地用eventfd/timerfd,”in all cases”。
另外一个重要优势就是eventfd/timerfd被设计成与epoll完美结合,比如支持非阻塞的读取等。事实上,二者就是为epoll而生的(但是pipe就不是,它在Unix的史前时代就有了,那时不仅没有epoll连Linux都还没诞生)。应用程序可以在用epoll监控其他文件描述符的状态的同时,可以“顺便“”一起监控实现了eventfd的内核通知机制,何乐而不为呢?
https://zhuanlan.zhihu.com/p/40572954
从echo服务器例子看起 muduo库是怎么搭建echo服务器的?下面的例子展示了两个组件:
调用Server的start以及EventLoop的loop后,整个服务器就开始运行了。
1 2 3 4 5 6 7 8 9 10 11 12 int main () EventLoop loop;。 InetAddress addr (4567 ) ; EchoServer server (&loop, addr, "EchoServer-01" ) ; server.start (); loop.loop (); return 0 ; }
下面再看看Server是如何编写的。我们的Server有两个成员变量:
EventLoop是muduo库的核心,这里先按下不表。EchoServer的构造函数和Start方法其实都是调用TcpServer的方法,前者注册两种事件的回调,后者调用TcpServer的start方法。
这里注册了两种事件的回调:连接事件和可读事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class EchoServer { public : EchoServer (EventLoop *loop, const InetAddress &addr, const std::string &name) : server_ (loop, addr, name), loop_ (loop) { server_.setConnectionCallback ( std::bind (&EchoServer::onConnection, this , std::placeholders::_1) ); server_.setMessageCallback ( std::bind (&EchoServer::onMessage, this , std::placeholders::_1, std::placeholders::_2, std::placeholders::_3) ); server_.setThreadNum (3 ); } void start () start ();} private : void onConnection (const TcpConnectionPtr &conn) { if (conn->connected ()) LOG_INFO ("Connection UP : %s" , conn->peerAddress ().toIpPort ().c_str ()); else LOG_INFO ("Connection DOWN : %s" , conn->peerAddress ().toIpPort ().c_str ()); } void onMessage (const TcpConnectionPtr &conn, Buffer *buf, Timestamp time) { std::string msg = buf->retrieveAllAsString (); conn->send (msg); conn->shutdown (); } private : EventLoop *loop_; TcpServer server_; };
回调注册的艺术 可以看到,muduo库使用非常简单,只要和EventLoop和TcpServer两个交流即可:
EventLoop调用Loop函数
TcpServer注册事件回调以及调用setThreadNum和start函数
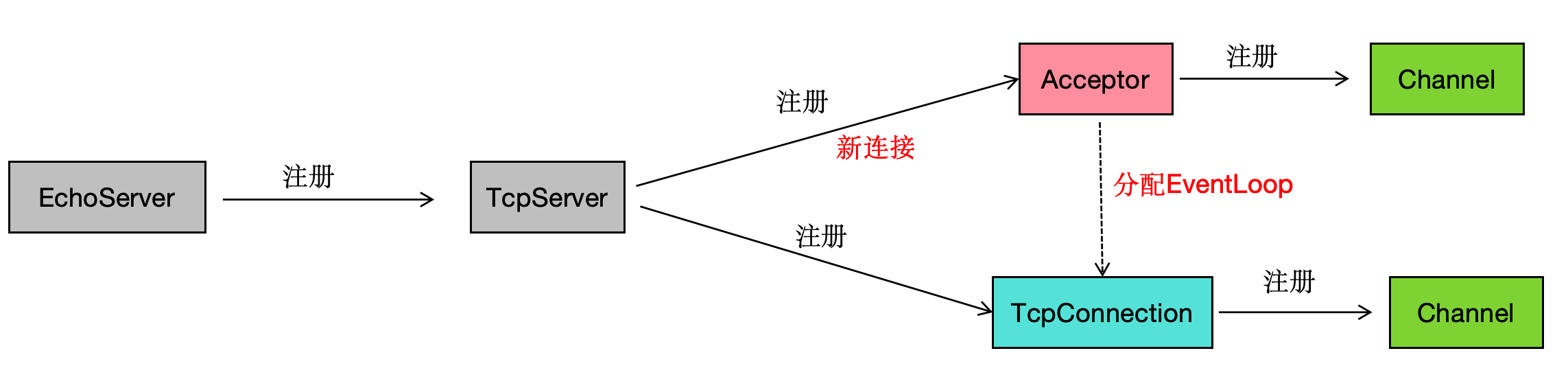
如果要继续了解muduo,那么得深入了解TcpServer的实现:
TcpServer注册了Acceptor的回调
TcpServer内含有一个线程池
Acceptor::listen函数在loop内运行runInLoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 TcpServer::TcpServer (EventLoop* loop, const InetAddress& listenAddr) : loop_ (CHECK_NOTNULL (loop)), ipPort_ (listenAddr.toIpPort ()) { acceptor_->setNewConnectionCallback ( std::bind (&TcpServer::newConnection, this , _1, _2) ); } void TcpServer::start () threadPool_->start (threadInitCallback_); loop_->runInLoop ( std::bind (&Acceptor::listen, get_pointer (acceptor_)) ); }
这里不禁发问:
Acceptor是什么东西,为什么又注册了回调?
runInLoop是什么含义?为什么要运行Acceptor的listen函数?
从字面意思上可以猜测,Acceptor是连接接受类,管理连接事件。listen函数其实就是监听开始,runInLoop就是让loop所在的线程执行listen函数。
换个方向 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 void EventLoop::loop () while (!quit_){ activeChannels_.clear (); pollReturnTime_ = poller_->poll (kPollTimeMs, &activeChannels_); for (Channel* channel : activeChannels_){ currentActiveChannel_ = channel; currentActiveChannel_->handleEvent (pollReturnTime_); } doPendingFunctors (); } } void EventLoop::doPendingFunctors () std::vector<Functor> functors; callingPendingFunctors_ = true ; { MutexLockGuard lock (mutex_) ; functors.swap (pendingFunctors_); } for (const Functor& functor : functors){ functor (); } callingPendingFunctors_ = false ; }
loop函数的实现回归了poll/epoll调用的范例:
先调用poller_->poll进行监听事件
再调用currentActiveChannel_->handleEvent进行活跃事件的处理
最后调用doPendingFunctors()处理其他不紧急的事件
这里先不管poller(大概率是epoll/poll的封装 )和 Channel。
Wait,既然loop函数在busy-querying,那么loop对应的线程又是怎么runInLoop的?
One Loop Per Thread one loop per thread是muduo的核心:一个EventLoop绑定一个线程。你有任务交给这个eventloop,那么eventloop对应的线程就会干活,有两种让线程干活的方式:
runInLoop 马上进行
queueInLoop 排队进行
那么,如何保证一个EventLoop对应一个线程?muduo采用的方案也很简单,eventLoop持有所在线程的线程号,当你有任务交给一个eventLoop做时,它先校验当前线程号是否与自己持有的线程号相同:
如果相同,说明在同一个线程中,唤醒线程干活
如果不同,那么将任务添加到eventLoop的等待队列pendingFuncotrs中
(1)t_loopInThisThread 线程局部变量
前述中eventLoop的线程号只保证了一个eventLoop对应一个线程,却并不能保证一个线程对应多个eventLoop。
t_loopInThisThread 变量就是为了解决一个线程对应一个eventLoop的问题,它是eventLoop的指针,并且是线程局部存储的(这意味着它不会在线程间共享,而是每个线程独自有一份)。在eventLoop的构造函数中会检查t_loopInThisThread的值是否设置,如果设置了,就打破了one loop per thread的语义。
另外,在许多函数中,都有 loop_->assertInLoopThread(); 来检查当前线程id是否与eventloop构造时存储的线程id一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 __thread EventLoop* t_loopInThisThread = nullptr; EventLoop::EventLoop() : threadId_(CurrentThread::tid()), wakeupFd_(createEventfd()), wakeupChannel_(new Channel(this, wakeupFd_)) { if (t_loopInThisThread) LOG_FATAL("Another EventLoop %p exits in this thread %d \n" , t_loopInThisThread, threadId_); else t_loopInThisThread = this; wakeupChannel_->setReadCallback(std ::bind(&EventLoop::handleRead, this)); wakeupChannel_->enableReading(); } void assertInLoopThread () { if (!isInLoopThread()){ abortNotInLoopThread(); } } bool isInLoopThread () const { return threadId_ == CurrentThread::tid(); }
(2)runInLoop & queueInLoop
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 void EventLoop::runInLoop (Functor cb) { if (isInLoopThread()){ cb(); }else { queueInLoop(std ::move(cb)); } } void EventLoop::queueInLoop (Functor cb) { { MutexLockGuard lock (mutex_) ; pendingFunctors_.push_back(std ::move(cb)); } if (!isInLoopThread() || callingPendingFunctors_){ wakeup(); } } void EventLoop::wakeup () { uint64_t one = 1 ; ssize_t n = write(wakeupFd_, &one, sizeof (one)); }
这里需要将eventLoop与线程分开来看待。
先说明一个背景:每个线程其实是在执行eventLoop的loop函数,loop函数干什么?poll系统调用轮询感兴趣事件。那么在没有事件发生时,大部分线程其实都是在睡眠状态的。
为什么强调线程与eventLoop分开?因为我们的线程可能拿到其他线程的eventLoop,而那个eventLoop的线程t1可能在沉睡。queueInLoop于是先将cb添加到pendingFunctors_中,然后再进行唤醒(往eventfd写一个数据,t1监听到eventFd有数据后,就会唤醒工作)。eventLoop会在处理完所有activeChannel的事件后处理pendingFunctor队列里积累的任务。
Q:为什么wake的条件是!isInLoopThread() || callingPendingFunctors_?前者容易理解,不在当前线程,后者如何理解?
A:todo
刨根问底 前述已经追问到TcpServer的Acceptor,并且已经大致理解了EventLoop的one loop per thread的语义。我们自顶向下地看,不免看到诸多注册回调的过程:
真是又重又长,但我们去伪存真后就会发现,muduo的核心就在这几类上:
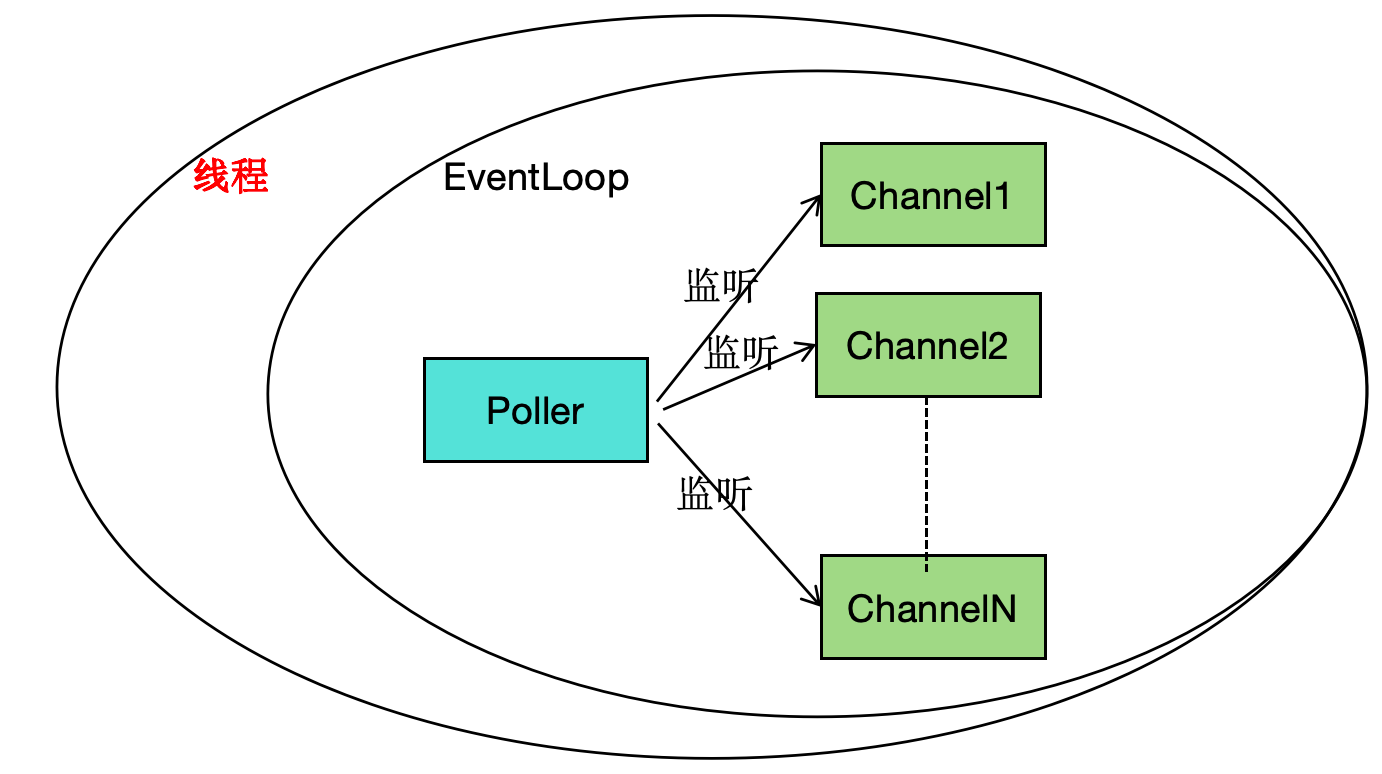
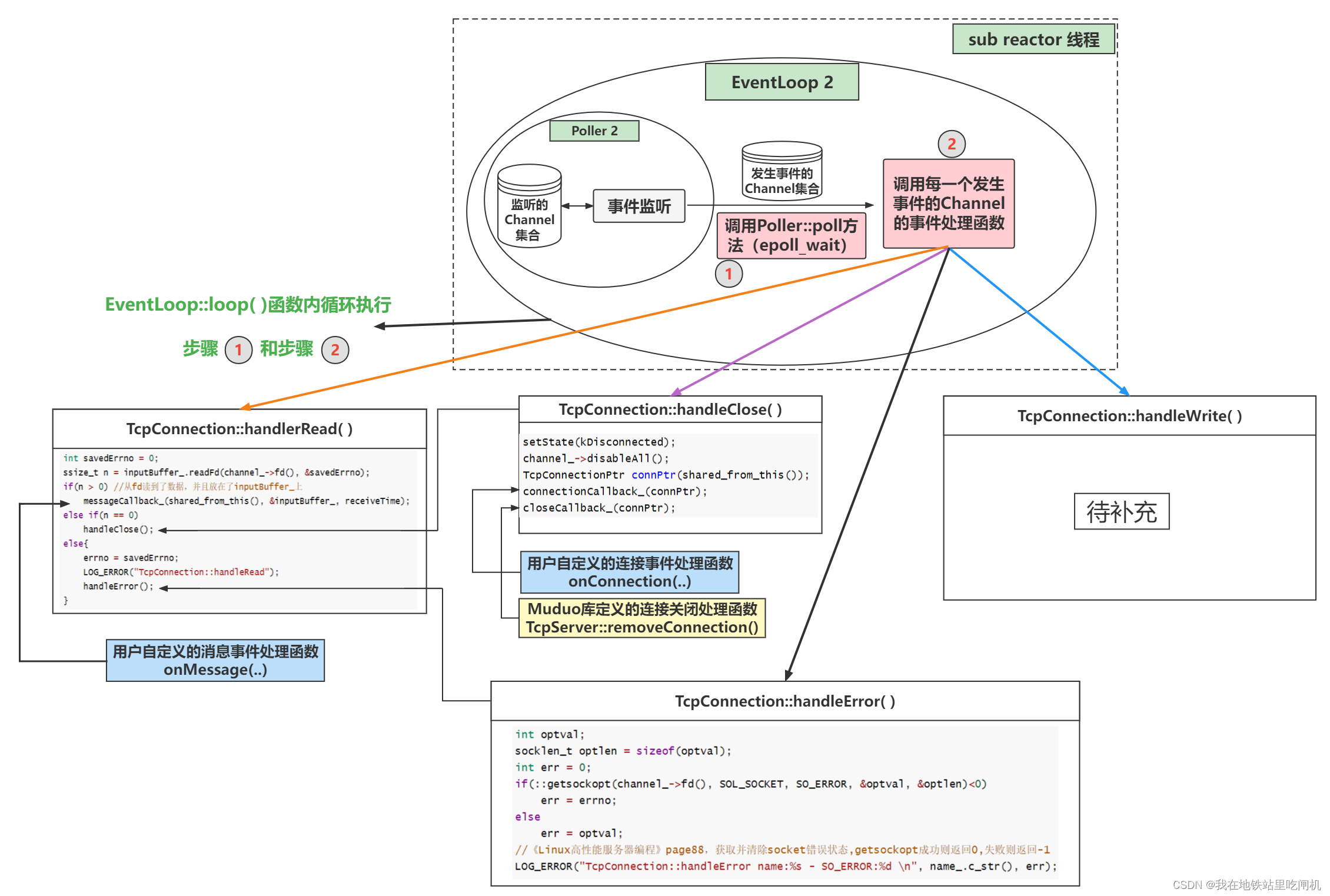
每个EventLoop都有一个Poller,Poller负责掌管众多Channel,而Channel则掌管着fd以及对应事件的回调。特别地,我们可以抛弃Acceptor和TcpConnection,只需要Channel(将各种回调都注册进Channe中)。
Channel 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 EventLoop* loop_; const int fd_; int events_; int revents_; ReadEventCallback readCallback_; EventCallback writeCallback_; EventCallback closeCallback_; EventCallback errorCallback_; void enableReading () { events_ |= kReadEvent; update(); } void disableReading () { events_ &= ~kReadEvent; update(); }void enableWriting () { events_ |= kWriteEvent; update(); }void disableWriting () { events_ &= ~kWriteEvent; update(); }void handleEvent (Timestamp receiveTime) ;void setReadCallback (ReadEventCallback cb) { readCallback_ = std ::move(cb); }void setWriteCallback (EventCallback cb) { writeCallback_ = std ::move(cb); }void setCloseCallback (EventCallback cb) { closeCallback_ = std ::move(cb); }void setErrorCallback (EventCallback cb) { errorCallback_ = std ::move(cb); }void Channel::handleEventWithGuard (Timestamp receiveTime) { if ((revents_ & POLLHUP) && !(revents_ & POLLIN)){ if (closeCallback_) closeCallback_(); } if (revents_ & (POLLERR | POLLNVAL)){ if (errorCallback_) errorCallback_(); } if (revents_ & (POLLIN | POLLPRI | POLLRDHUP)){ if (readCallback_) readCallback_(receiveTime); } if (revents_ & POLLOUT){ if (writeCallback_) writeCallback_(); } }
Channel类是事件机制的保姆,它封装fd上的感兴趣事件以及发生的事件,封装了注册修改事件以及发生对应事件的回调函数。在发生事件时,调用Channel的handleEvent进行事件处理。
Q:channel是什么时候被注册进poller中的呢?
A:enableReading、enableWriting等函数,该函数实现中的update
Poller 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Poller : noncopyable{ public : Poller (EventLoop *loop); virtual ~Poller (); virtual Timestamp poll (int timeoutMs, ChannelList *activeChannels) 0 ; virtual void updateChannel (Channel *channel) 0 ; protected : typedef std::map<int , Channel *> ChannelMap; ChannelMap channels_; private : EventLoop *ownerLoop_; }; Timestamp EPollPoller::poll (int timeoutMs, ChannelList* activeChannels) int numEvents = ::epoll_wait (epollfd_, &*events_.begin (), static_cast <int >(events_.size ()), timeoutMs); Timestamp now (Timestamp::now()) ; if (numEvents > 0 ){ fillActiveChannels (numEvents, activeChannels); } return now; } void EPollPoller::fillActiveChannels (int numEvents, ChannelList* activeChannels) const for (int i = 0 ; i < numEvents; ++i){ Channel* channel = static_cast <Channel*>(events_[i].data.ptr); channel->set_revents (events_[i].events); activeChannels->push_back (channel); } }
Pooler是Poll或Epoll的封装,提供注册修改Channel的接口。所有的Channel都会保存在poller的map中。poll函数是IO复用的重要封装,它将返回的事件填充到activeChannels中。
理解muduo
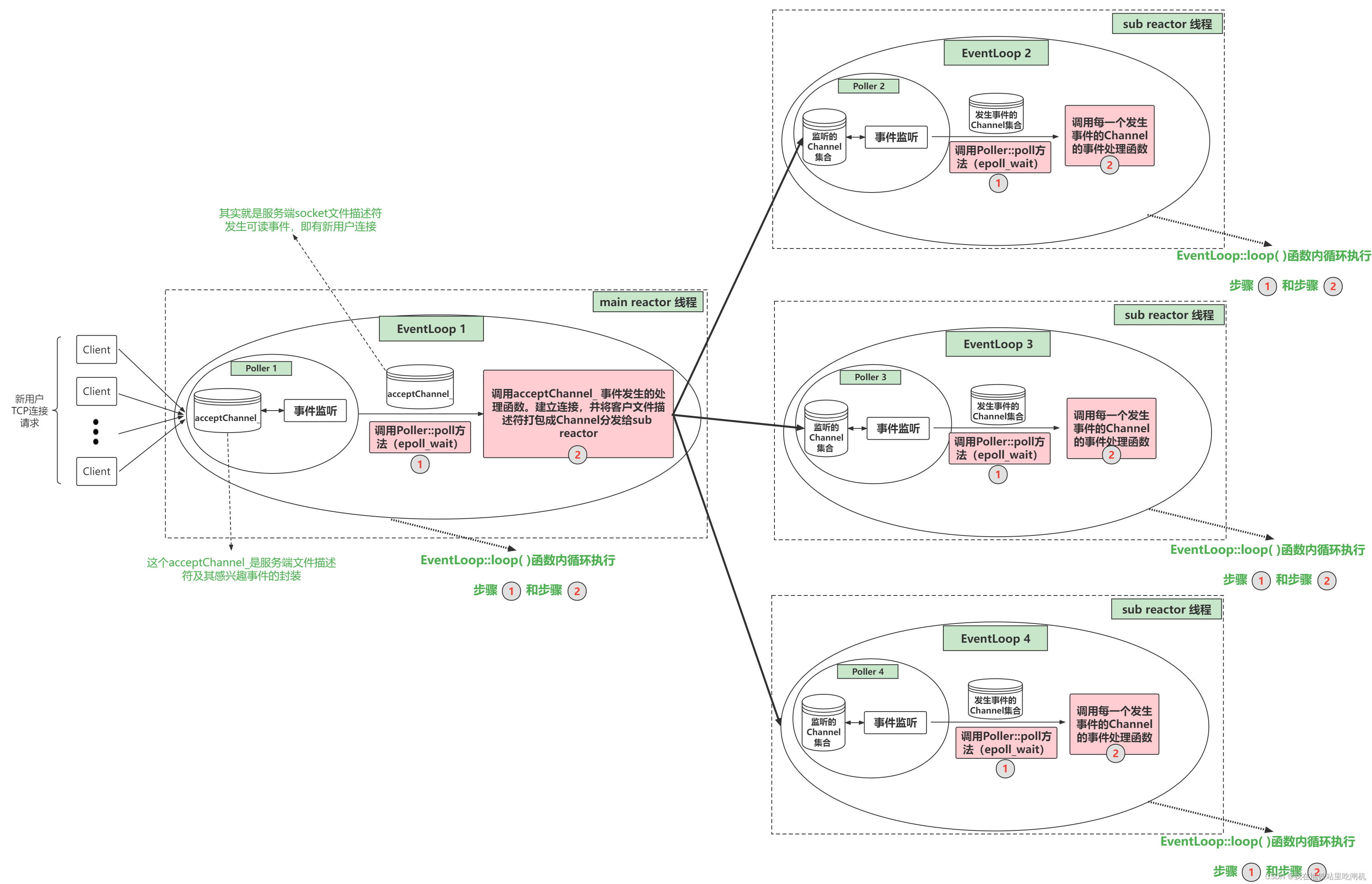
首先就是要理解mainReactor和subReactor,它们都是对应有eventLoop,分别称为mainEventloop和subEventloop。mainEventloop主要处理连接事件,包含了acceptor这个重要组件。subReactor有自己的监听器,处理读写事件。
每个eventloop都有自己的Poller(也就是事件监听器),这样的好处是高效利用线程(不这么做的话,线程就是干等任务,而如此实现,线程其实阻塞在epoll调用,相当于减少任务分发过程,还能保持一个连接同一个线程服务)。
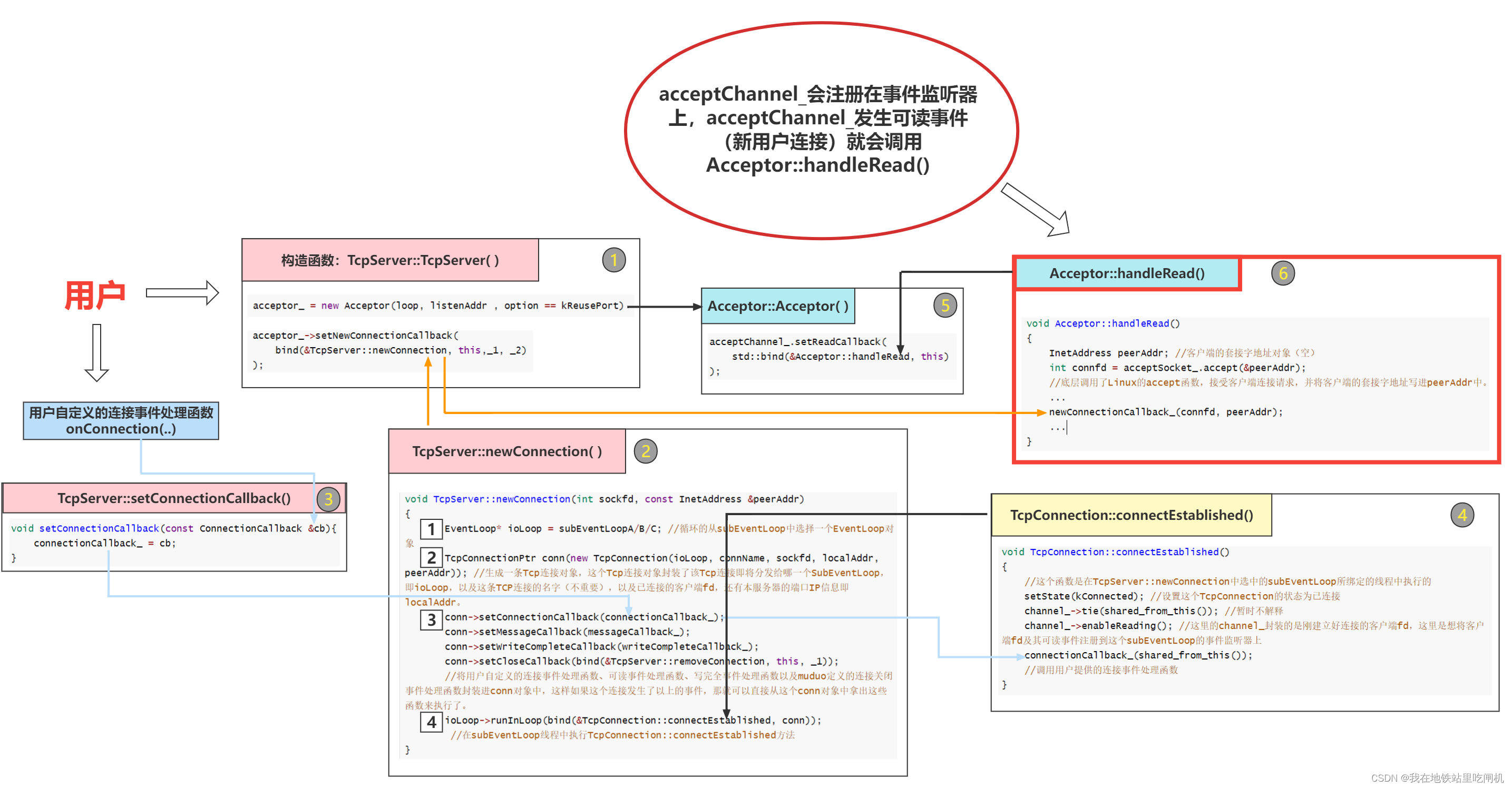
连接建立
上图中可能不太准确,5改为2,6改为3。
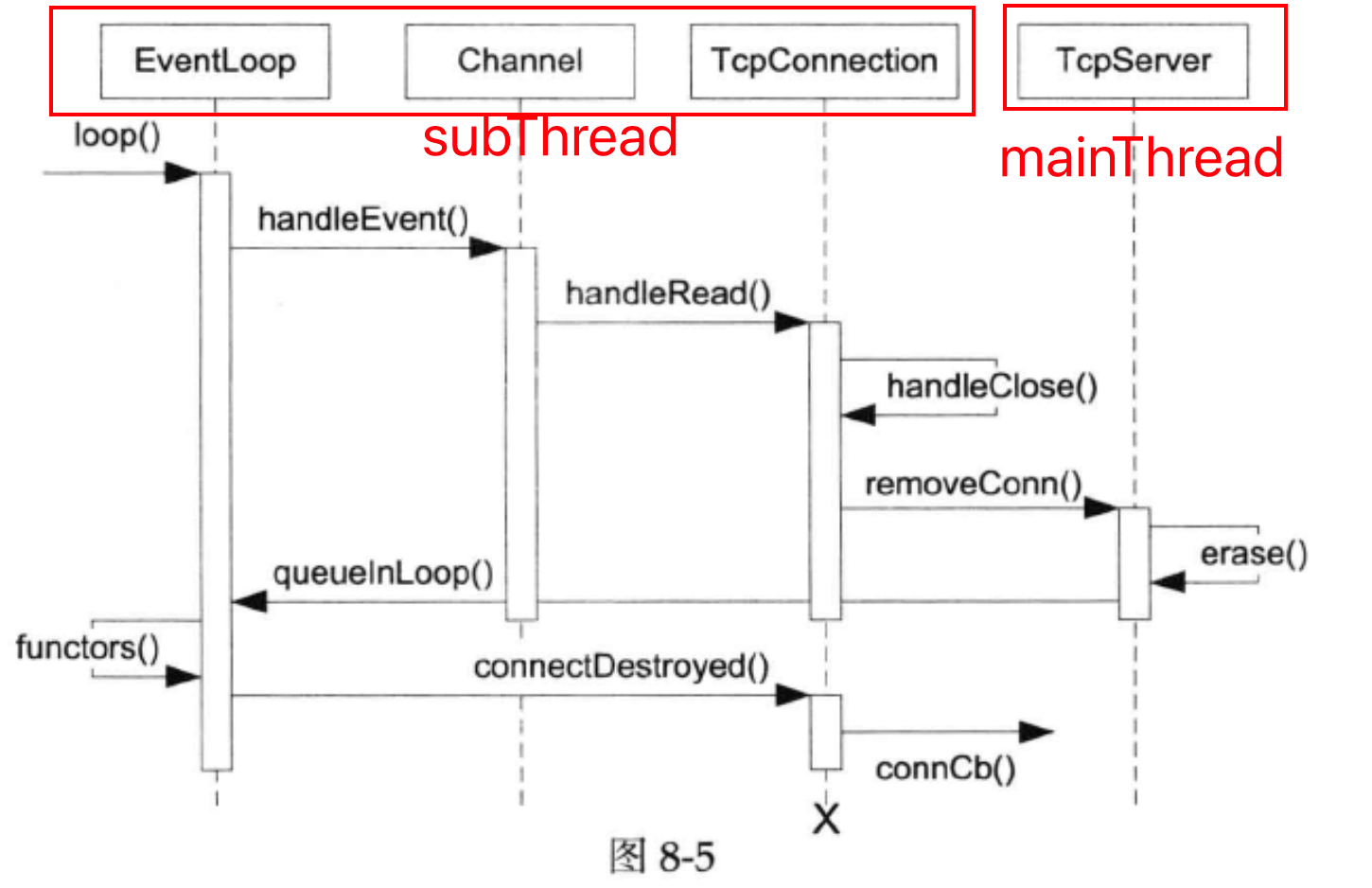
在muduo启动后,acceptor处理可读事件,调用TcpServer::newConnection。它获取一个subEventLoop,构造TcpConnection,然后在subEventLoop所在的线程中进行连接的建立(runInLoop、connectEstablished)。
connectEstablished会将fd注册到subEventloop中的Poller中 channel_->enableReading();
1 void enableReading () { events_ |= kReadEvent; update(); }
这里获取一个eventLoop然后调用runInLoop就能在所在线程执行任务是一个很关键的设计点,后续会讲。
消息读取
消息读取的主要逻辑就在loop函数中,对于每个channel依次调用对应事件的处理函数。读取处理分为两步:
读取消息至inputbuffer中
调用用户的messageCallBack
1 2 3 4 5 for (Channel* channel : activeChannels_){ currentActiveChannel_ = channel; currentActiveChannel_->handleEvent(pollReturnTime_); }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void TcpConnection::handleRead (TimeStamp receiveTime) { int savedErrno = 0 ; ssize_t n = inputBuffer_.readFd(channel_->fd(), &savedErrno); if (n > 0 ) { messageCallback_(shared_from_this(), &inputBuffer_, receiveTime); } else if (n == 0 ) handleClose(); else { errno = savedErrno; LOG_ERROR("TcpConnection::handleRead" ); handleError(); } }
消息发送 调用TcpConnetion::send(buf)函数,将buf内的数据发送给对应客户端。
这里对于写是多段处理的:如果TCP的缓冲区放不下buf的数据,那么剩余未发送的数据会存放到TcpConnection::outputBuffer_中。然后注册可写事件,在监听到可写时,由TcpConnection::handleWrite( )函数把TcpConnection::outputBuffer_中剩余的数据发送出去。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 void TcpConnection::sendInLoop (const void * data, size_t len) { loop_->assertInLoopThread(); ssize_t nwrote = 0 ; size_t remaining = len; bool faultError = false ; if (state_ == kDisconnected) { LOG_WARN << "disconnected, give up writing" ; return ; } if (!channel_->isWriting() && outputBuffer_.readableBytes() == 0 ) { nwrote = sockets::write(channel_->fd(), data, len); if (nwrote >= 0 ) { remaining = len - nwrote; if (remaining == 0 && writeCompleteCallback_) { loop_->queueInLoop(std ::bind(writeCompleteCallback_, shared_from_this())); } } else { nwrote = 0 ; if (errno != EWOULDBLOCK) { LOG_SYSERR << "TcpConnection::sendInLoop" ; if (errno == EPIPE || errno == ECONNRESET) { faultError = true ; } } } } assert(remaining <= len); if (!faultError && remaining > 0 ) { size_t oldLen = outputBuffer_.readableBytes(); if (oldLen + remaining >= highWaterMark_ && oldLen < highWaterMark_ && highWaterMarkCallback_) { loop_->queueInLoop(std ::bind(highWaterMarkCallback_, shared_from_this(), oldLen + remaining)); } outputBuffer_.append(static_cast<const char *>(data)+nwrote, remaining); if (!channel_->isWriting()) { channel_->enableWriting(); } } }
连接关闭 muduo处理连接关闭的方式只有一种——被动关闭。等待客户端关闭连接,服务端调用read返回0后被动关闭连接。
连接关闭既然从本地对应的subEventloop中删除fd,也要在mainEventLoop的TcpServer中删除该fd。
其余模块 Acceptor
TcpConnection
线程类:ThreadPool、ThreadData、Thread
TimerQueue、Buffer
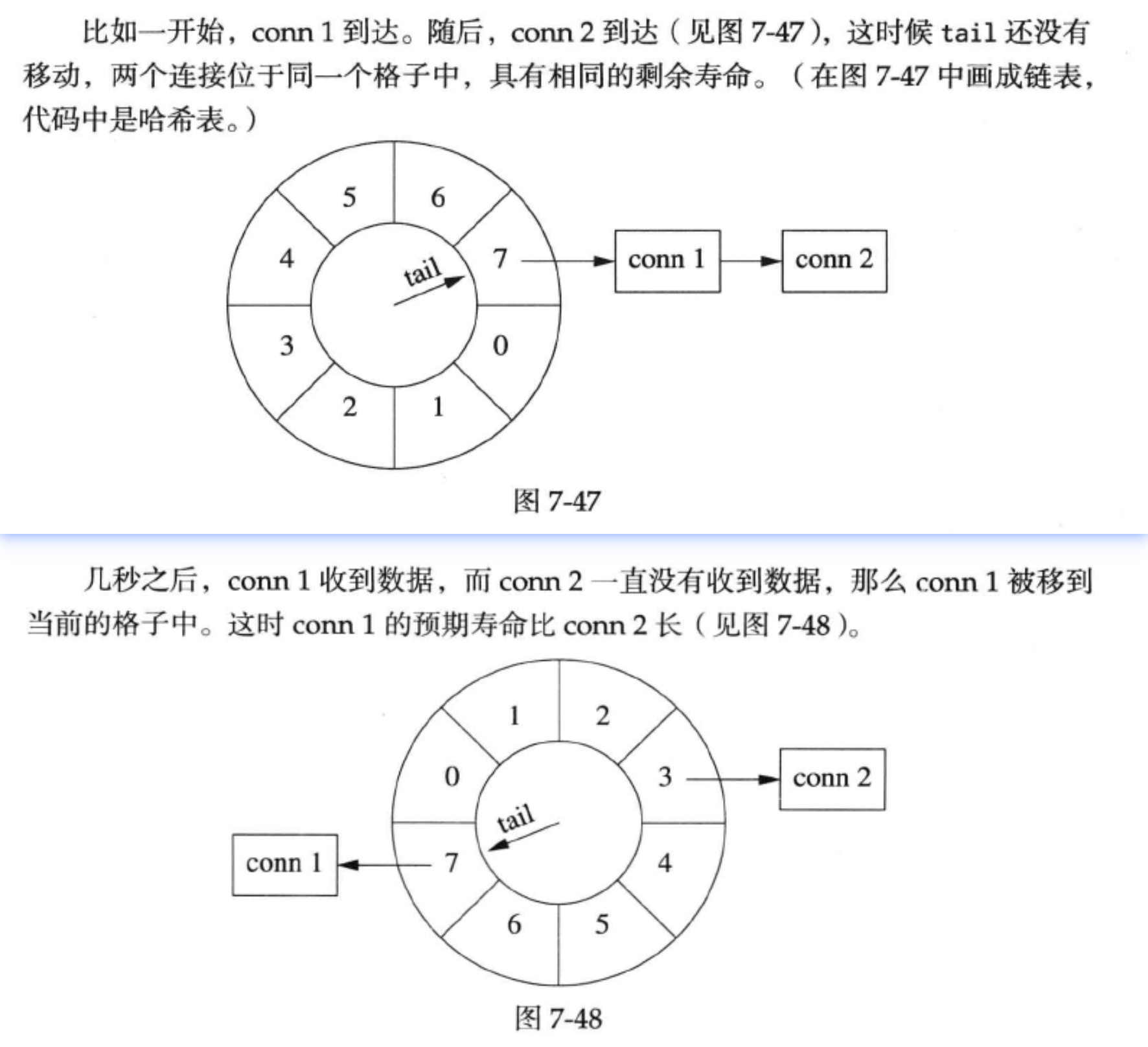
TimerQueue 定时器的实现比较有趣,时间轮:当连接有事件发生时,将连接注册到当前指针指向的格子中;指针每隔固定时间转动一格,当指向某格时,执行当前格里所有回调函数。
代码实现:不是真的把一个连接从一个格子移动到另一个格子中,而是利用引用计数方式。
格子以unordered_set的方式管理entry,一个entry就是一个连接的共享指针。
时间轮以环形队列管理
注册每秒的事件:往队尾添加一个空的Bucket。这样队头的Bucket就会弹出自动析构。
在接收到消息时,将Entry放到时间轮的队尾(如此,引用计数递增)
采用共享指针可以确保连接出现在格子中时,引用计数不为零。而当引用计数减为零时,说明连接没有在任何一个格子中出现,那么连接超时,Entry的析构函数会断开连接。
1 2 3 4 typedef std ::shared_ptr <Entry> EntryPtr;typedef std ::weak_ptr<Entry> WeakEntryPtr;typedef std ::unordered_set <EntryPtr> Bucket;typedef boost::circular_buffer<Bucket> WeakConnectionList;
细节:在TCPconnection中保存一个Entry的弱引用WeakEntryPtr,在接收到消息时,将弱引用提升为强引用EntryPtr。如此实现正确的引用计数。
Buffer
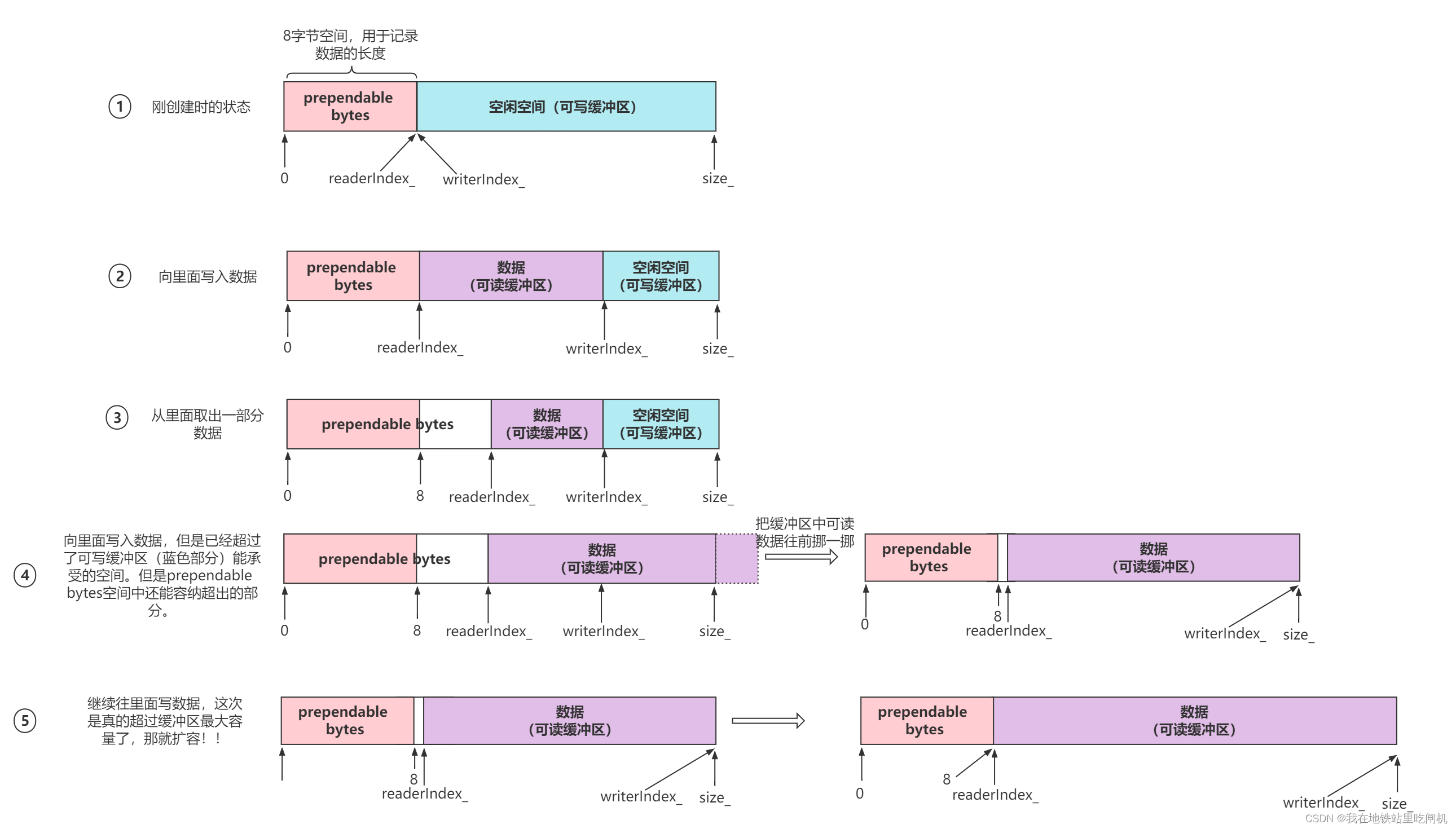
Buffer 封装了一段缓冲区,用于消息读取和写入。在muduo里,你不必自己去read或write某个socket,只会操作TcpConnection的input buffer和output buffer。
特性表现:
对外表现为连续内存,大小可以自动增长
表现为queue,从末尾写入数据,从头部读出数据
线程不安全
值的借鉴的设计有:缓冲区前增加一段8字节空间(prependable space),可以让程序以极低的代价在数据前面添加几个字节,比如说消息的长度。
代码设计:
两个游标readerIndex和writerIndex
size指向实际使用的空间,capacity指向扩容的总空间
内部腾挪:当writable空间不足时,会将已有数据整体前挪,再根据判断是否触发扩容
参考 长文梳理Muduo库核心代码及优秀编程细节剖析-CSDN博客